计算机系统工程之:INode文件系统
Weiquan Huanglec03 inode fs
- 文件事实上是binary array(durable and has a name)
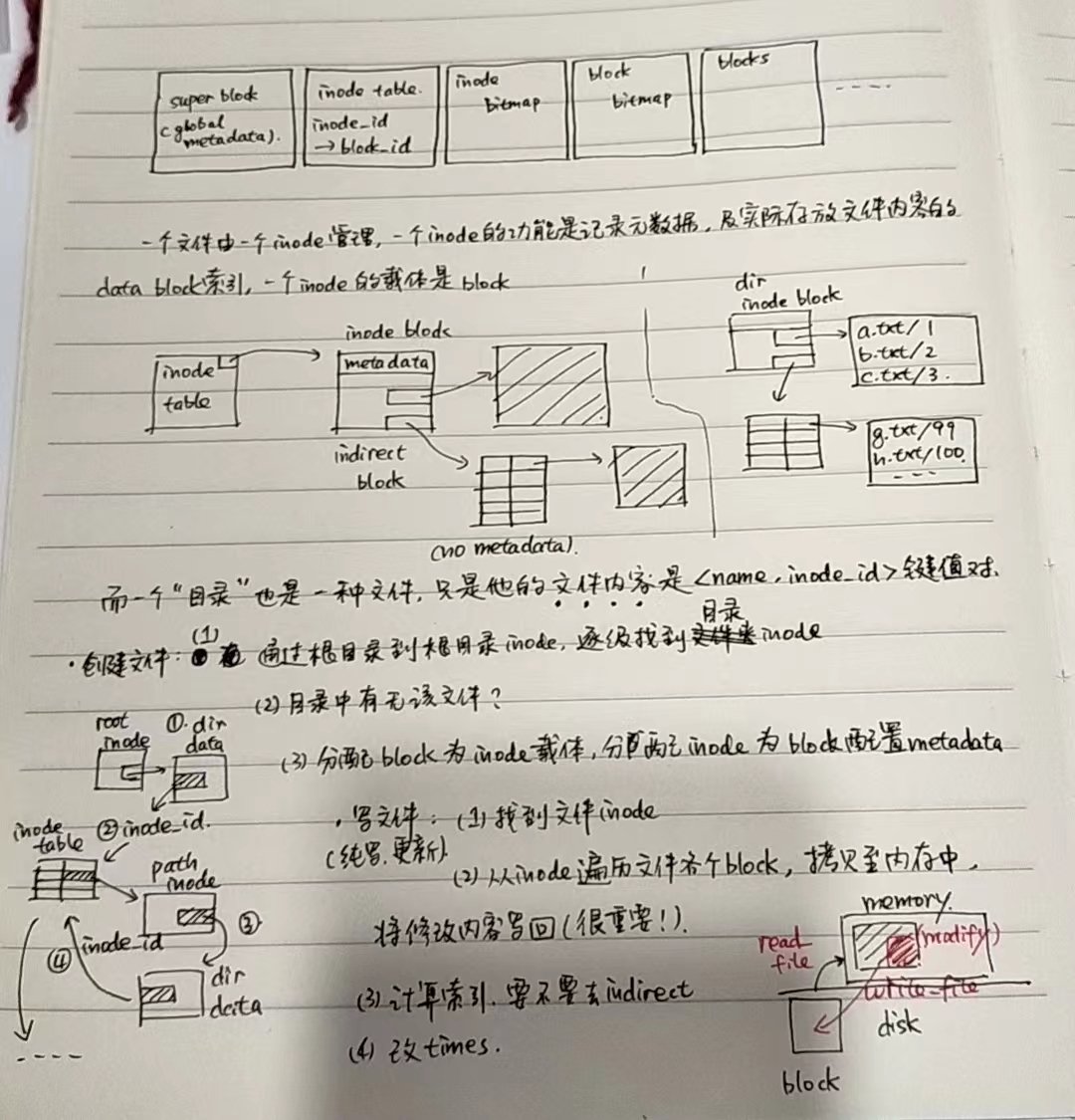
- block用来存储多个sector,一个sector是disk driver接口读取和写入的最基本单元,为了保证index存储的大小不会太大(sector比较小,意味着index比较多,意味着需要用比较多的byte去表示),加一层block用来减少index的位数
- 一般一个block只被一个file占用,即使空间被浪费
- 元数据的存储:
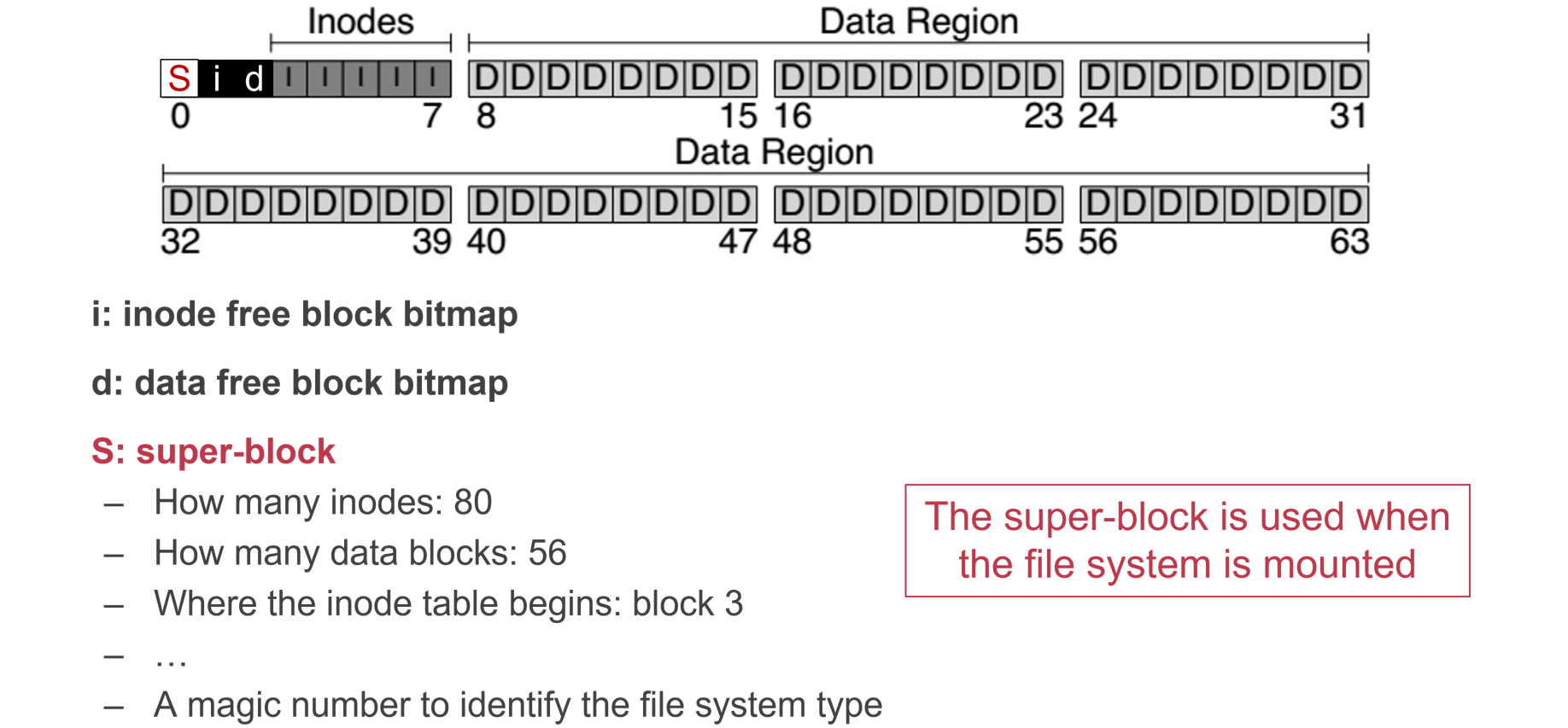
- superblock存储block size等较为通用的元数据
- inode bitmap存储空inode的index
- block bitmap存储空block的index,$(0|1)^+$

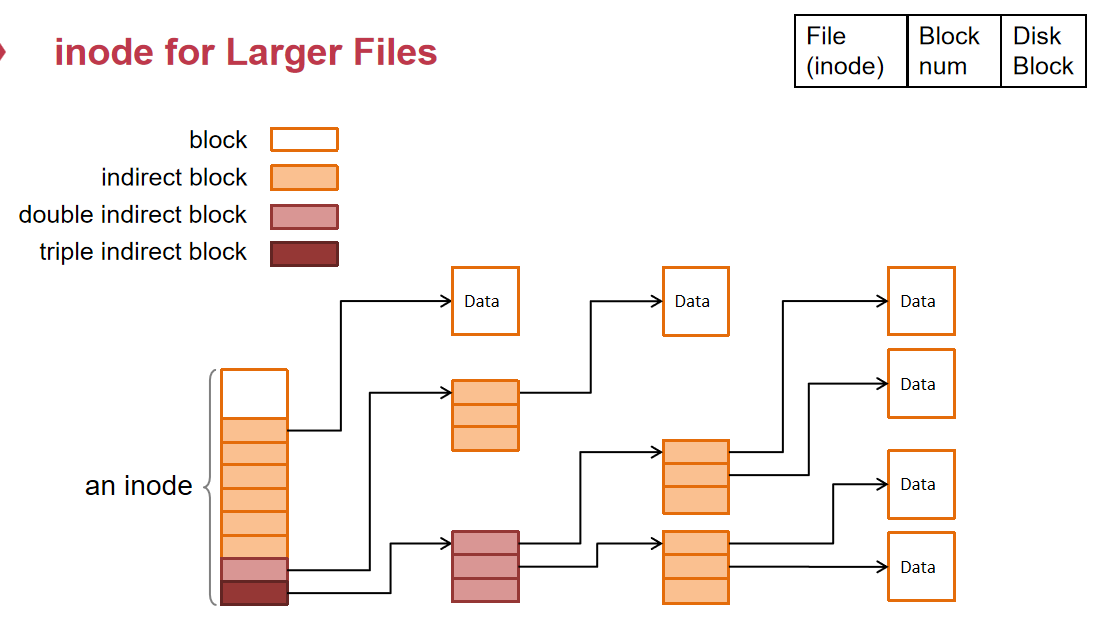
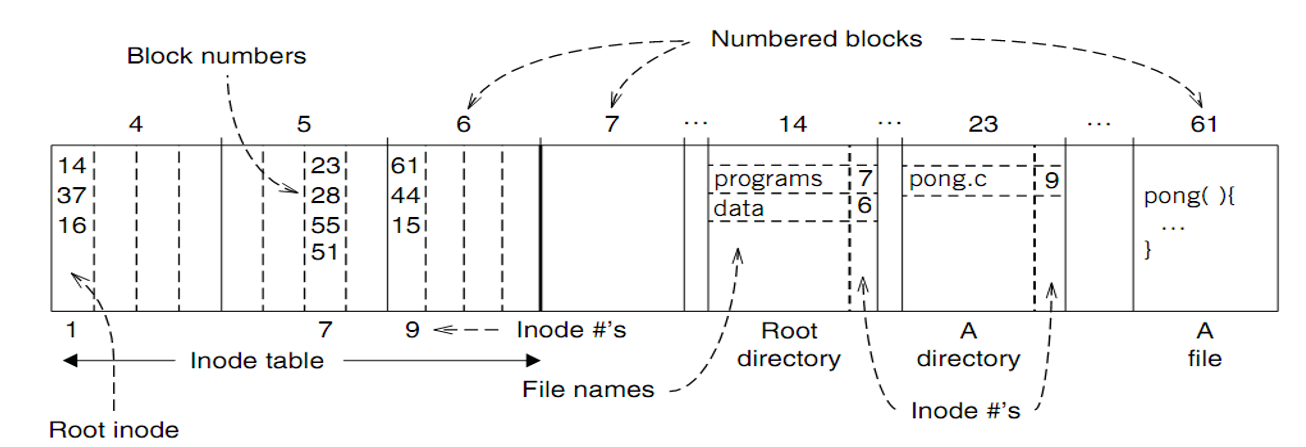
- 使用inode来存储单个file,inode结构为:由直接指向Data Block和指向Indirect Block的指针构成,最后汇集成一个file
- 使用一个叫做inode table的mapping表来存储每个inode file的block位置,并标记是否为空闲等
- 将文件名和inode的映射关系存放在称为directory的地方,directory同时也是一个文件,执行查找函数会返回file的iNode,而且会遍历directory的每一个file进行查找
- 分层结构(Hierarchy):结构化命名文件和目录,查找算法中进行从root到leaf的查找
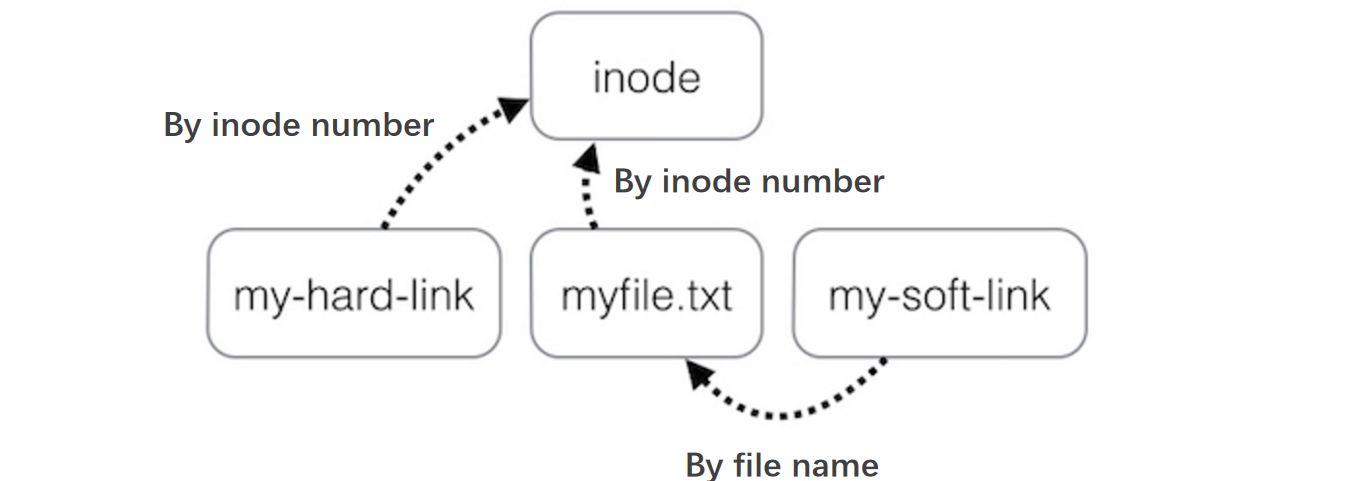
- Link是能够给文件目录路径起别名的机制,比如
LINK("mail/inbox/new-assignment", "assignment");文件需要维护一个ref count数据来记录当前指向自己的link,如果为0则可以删除;不允许出现环形的link,否则可能导致文件无法删除由于删除了/a目录的link,导致无法通过/a/b/c和/a访问这个文件目录,那么就无法对另一个绑定做解绑,因为访问不到这个路径了,就导致这些目录下的内容也无法自动删除 - 文件重命名:一般编辑文件会创建一个文件的
.swp副本,首先先UNLINK将要起的名字,将这个名字有的文件先删掉;然后LINK新文件名到旧文件名上;随后UNLINK旧文件名,就解除了这个文件在映射系统下对旧文件名的映射,建立了对新文件名的映射;需要是一个连续的原子操作
 由于删除了
由于删除了lec04 fs api
复习并澄清一些概念:
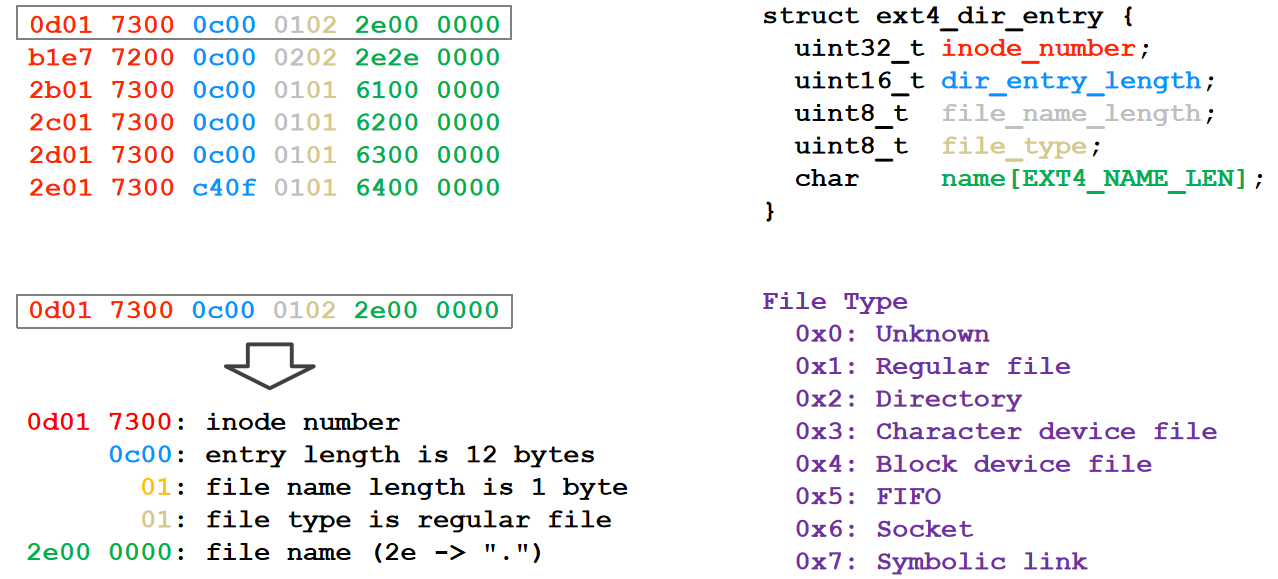
- file name保存在directory目录下,目录是一个file name-inode number的键值对存储,实际上一个文件是与inode关联的,其最直接的索引是inode number,给文件命名只是为了让用户可用
name_to_inode(filename, int dir_number)以文件名和目录号寻找文件- 二进制化一个directory的结果
- 根目录是最高权限、所有用户共有的, 每个用户有自己的
~目录,根目录的inode起始位置存储在特定寄存器中,可以通过根目录inode导引到根目录所在的block,由该block的键值对信息导引到子目录的inode,由子目录inode导引到子目录所在的block,然后再根据文件名导引到文件inode,然后导引到文件所在的block上(其中,inode table有不同的block号,这意味着这些文件/目录有不止一个block存储信息) - Symbolic link分为硬链接和软链接两种,硬链接之间互相等地位,都是指向一个文件的inode;软连接指向一个硬链接,可以虚空创建软连接
cd命令的特殊性:cd命令会存储上次执行的cd路径,假设cd ..则导向上次所存储路径的去掉一级目录的位置,比如cd /CSE而/CSE link to /C/S/E则执行cd ..导向/目录;如果想要跳转到实际连接下的目录需要添加-P参数- 文件名不是文件的一部分、目录大小和文件大小无关
实现fs api前置知识:
open()是linux专属文件操作函数,返回file descriptor;fopen()是C包装的一个函数,对不同的操作系统有不同的处理策略,由于其使用了io buffer,因此会有更好的读取效率- 文件metadata:block numbers, file size, file type(regular file, dir…), reference count, user id, group id, mode, access time(last read time), modification time, change of inode time(Link or other opr)
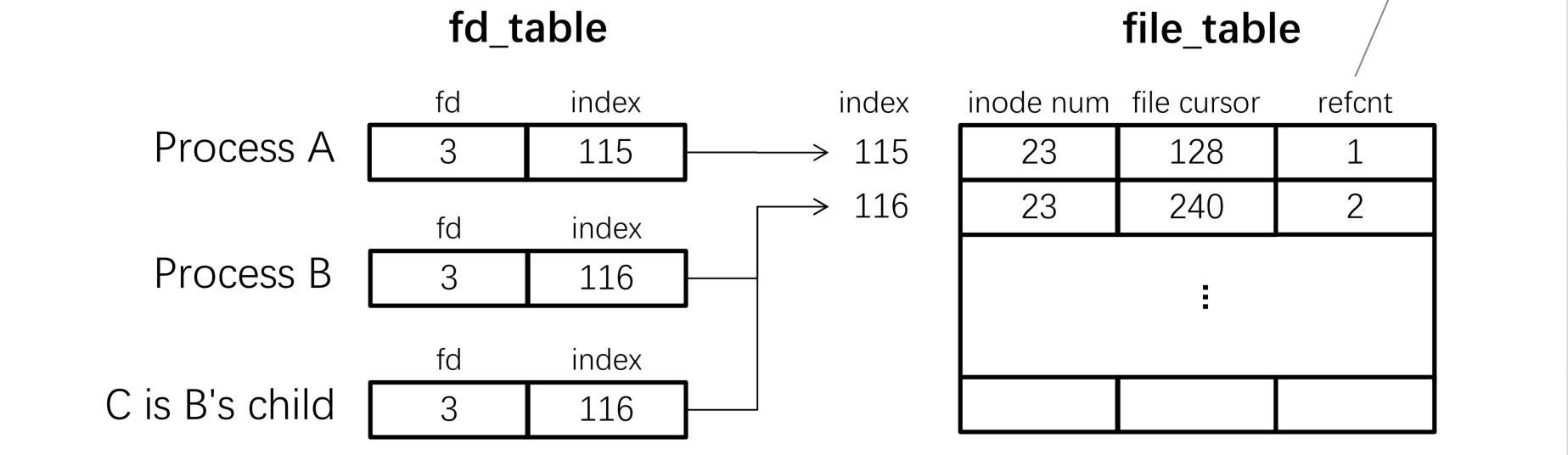
- file descriptor文件描述符可以作为程序和文件交互的通道,这里不直接使用文件的指针是因为防止别有用心者通过偏移指针访问到不该访问的其他文件;多个fd可以指向同一个file table的表项,而多个file table的表项又可以指向同一个inode
- cursor光标,用于标识当前对文件操作的位置
实现fs api:
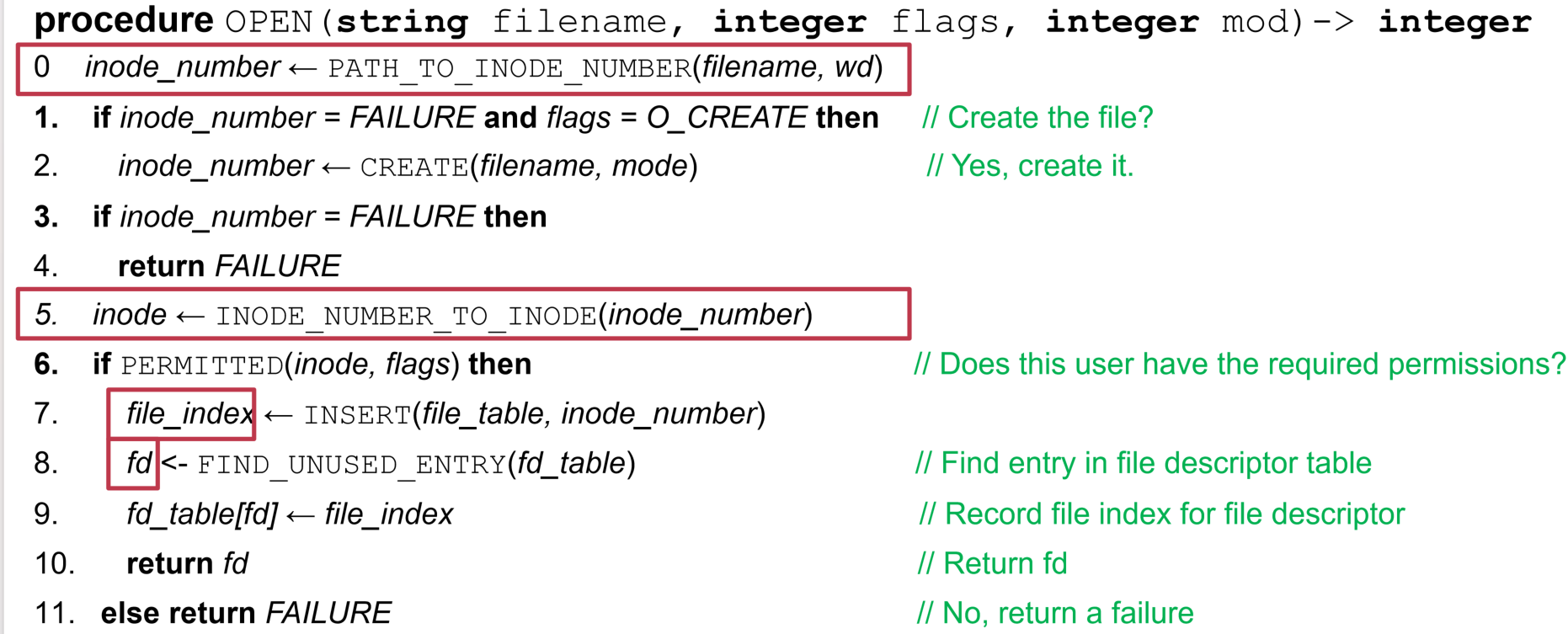
open:- 根据文件名寻找inode number,如果没有找到则根据操作类型判断是否要新建文件
- 获取inode number,将inode number插入file table中,并且在fd table中创建一个关联到该file table表项的fd表项,注意fd总是找下标最小的空表项
read:- 从fd查找file index,获取cursor和inode,修改atime
- 一个一个block地读取,直到读完文件或者读完预期大小的文件内容
write类似于readappend类似于writeclose:释放fd表项、递减refcnt、释放refcnt=0的file table表项

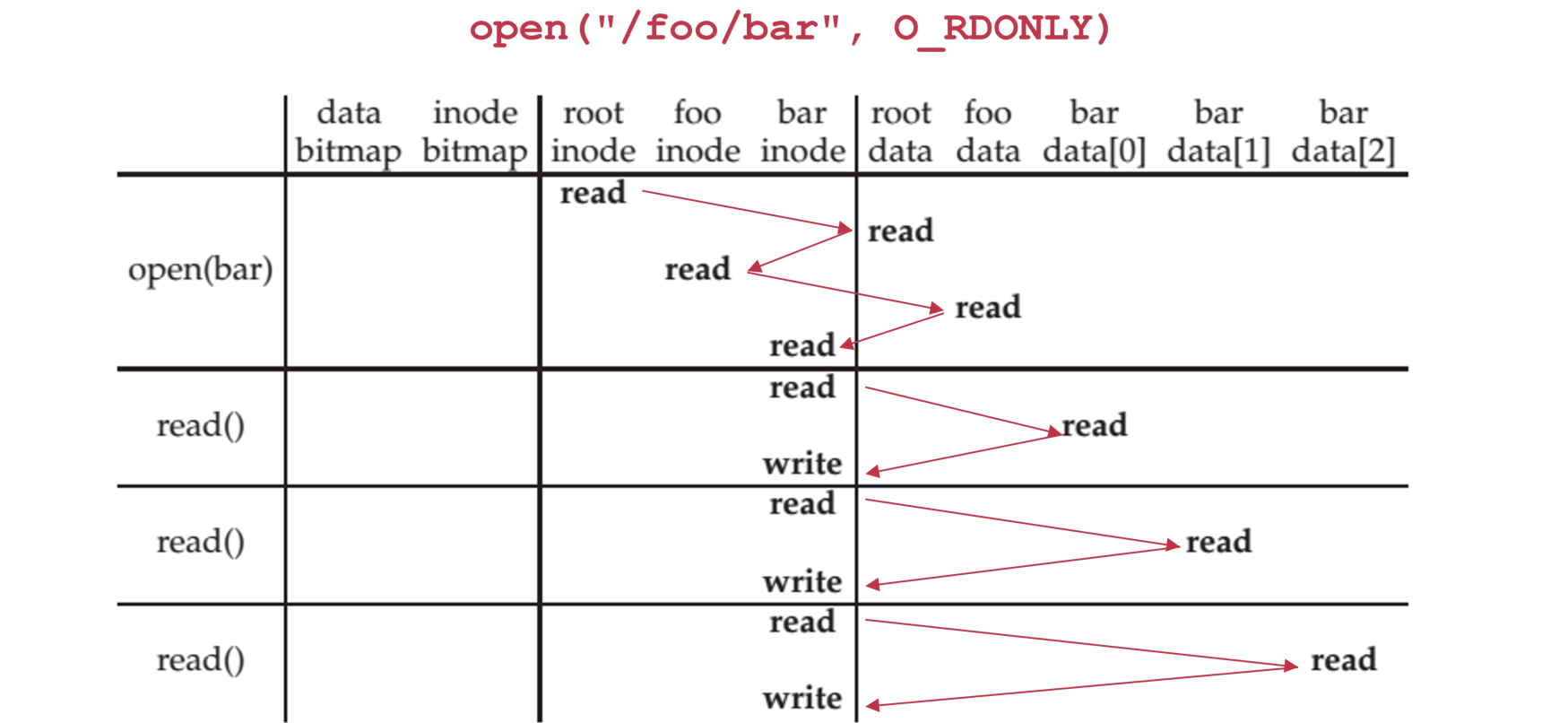
分析实际的读取步骤:
- 首先明确一下,一般inode是block的索引,最开始肯定先从root inode开始找root data
- 目录里存的data就是里面文件和inode的键值对,因此去目录搜索文件的步骤就是先去inode找data block位置,然后去data block处找,没找到再去inode读下一个data block的位置…
- write一般是修改atime,不过屡次修改过于耗时,目前打开文件默认为不在每次读取后修改atime,而是在close后修改
创建文件的步骤可以在复习的时候进行分析练习:
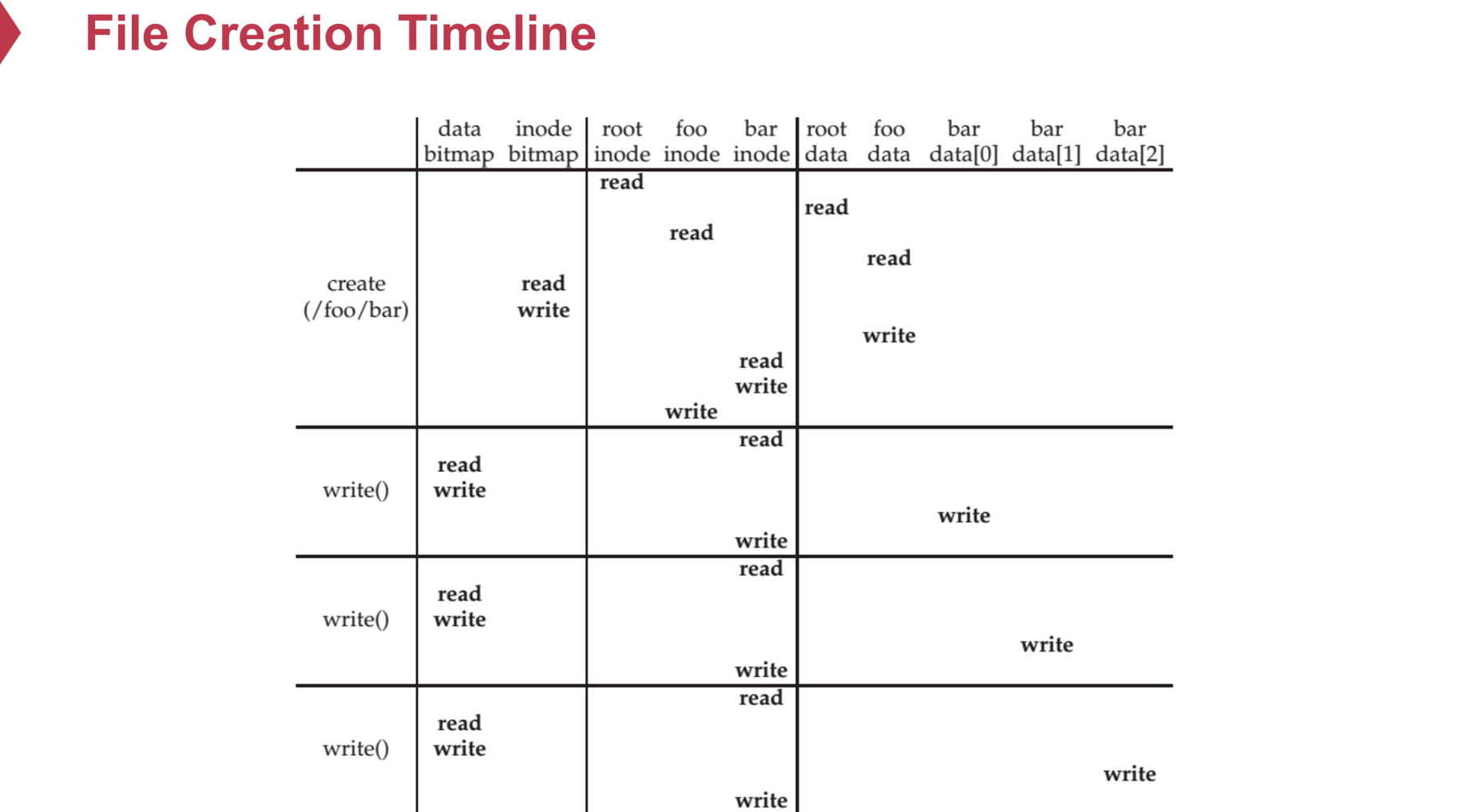
同步问题:内存使用缓存,但是突然断电,导致修改数据未及时持久化;设置每次修改cache之后进行一个异步的写入持久层操作
文件打开后删除?不直接回收inode,先把指向文件的name给回收了让文件refcnt=0,然后等关闭了之后回收inode
lab1 Basic File System
这个lab难度不大,但是由于没有复习fs的架构,以及对一些C++接口特定不熟悉/遗忘,导致耗时相对较长,下次考虑先复习相关内容,动手前先思考思路后再写代码
memcpystrcpy内存拷贝肯定用前者,strcpy如果遇到\0直接停了,不是内存定长拷贝的合适选项- 在
.gitignore文件可以通过通配符方式指定不需要通过git管理的文件、目录 - 不清楚docker container如何安装
gdb,用不了gdb还是用cout大法吧,虽然比较那啥,但是还是有效的,比自己瞎猜好 bitmap计算的时候由于u8有8个bit,所以size * 8才是正确的计算索引的基准[[maybe_unused]]表示函数不被用到也不会触发编译器的警告,类似的[[nodiscard]]表示函数返回值如果没有被接收会报警告