科大计网之:应用层
Weiquan Huangchp2-1 应用层协议原理
网络应用体系架构:
- CS模式(客户端服务器):这玩意我们部署过,挺熟悉这种架构的了;服务器一直运行,固定IP和端口号;客户端与服务器通信;缺点是可扩展性比较差,表现为宕机后会造成故障、服务集中于服务集群导致网络流量资源问题等
- 对等体(p2p):每个端系统自成服务/客户端,服务提供不再仅限于集中的服务器,流量和负载问题有改善;不过难以管理
- Napster(cs & p2p):中央服务器用于存储什么服务在什么IP的服务端上的表信息(搜索),客户端向中央服务器查找后导向目标服务端进行服务的请求(传输文件)
一个服务是运行在一个主机的一个 进程 ,同主机内进程通信通过 进程间通信机制(操作系统定义) 通信,不同主机通过 交换报文Message 来通信(通过OS的通信服务和协议进行规范)
- 一个进程用IP+port标示,是一个端节点(TCP/UDP分别有不同的port范围空间)
- 携带信息:要传输的报文SDU+传给谁和谁传的,应用层通过socket来标识通信的双方和单方,这样每次在socket传输报文的时候就不用携带那么多信息了
socket
socket是一种标号,标示通信的双方(tcp)或单方(udp),类似于os打开文件返回的句柄,对标号的操作就是对通信接口的操作
- TCP socket:
- 通信前建立连接,连接持续一段时间
- 唯一地指定了一个会话,使用这个标示和远端应用进程通信
- 具有本地意义的标示
- 相当于传输的时候提供SDU和TCP socket即可

- UDP socket:
- 无需建立连接
- 仅表示本应用实体的标示
- 传输报文的时候需额外提供对方IP port
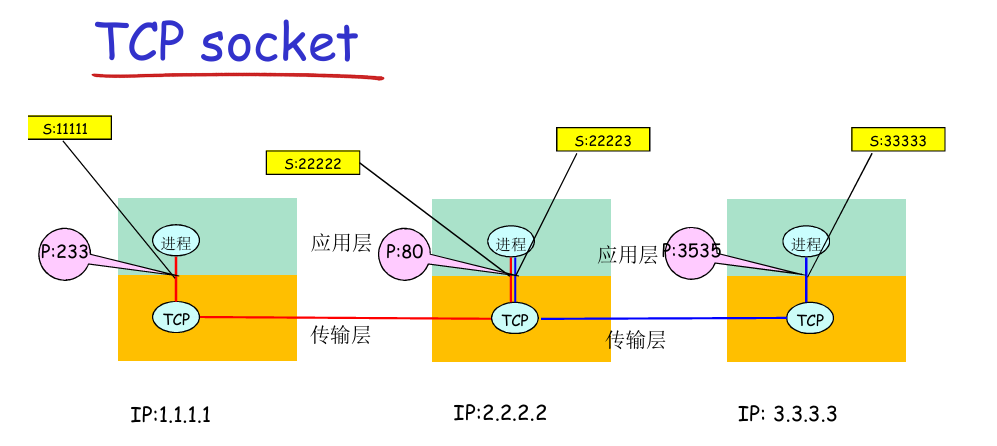
socket起到了将应用层数据转向传输层的作用,封装了传输层的细节,发送给socket就可以发送给对应通道数据
应用层协议
如何使用传输层提供的服务实现应用?需要定义应用层之间的协议,规定报文格式、解释、时序等
应用需要传输层提供什么样的服务?TCP/UDP之争
- TCP的优点就是稳定可靠:流量控制、拥塞控制、内容稳定发送
- UDP的优点就是效率高、无速度控制确保速度
- email web等偏爱TCP,视频流媒体平台偏爱UDP
- TCP、UDP不提供安全服务,可以在TCP上层再垫一个SSL,提供私密、鉴别等服务

chp2-2 Web和HTTP
web页由一些对象组成,对象可以是html文件、图片、Java小程序、音视频等,一个web页含有HTML框架和多个对其他对象的引用,通过url对每个对象进行引用(获取资源);在网页中,首先浏览器会请求html框架,随后再将一些图片对象再次发请求获取;URL格式为:Protocol://user:psw@hostname:port/path/to/resource
HTTP请求的过程:
- 服务端有一个“守候socket”,用来等待客户端的tcp连接建立请求,建立tcp连接会新建连接会话socket
- 客户端发起建立tcp连接的请求,服务端响应并创建连接,各自维护一个socket
- 基于这个tcp连接进行http协议报文(请求、响应)的发送
- 若是http/1.0,则关闭tcp连接
- 若是http/1.1,则默认不关闭连接,可以基于这个连接继续发送http请求,发送请求的模式分为流水线模式和非流水线模式(pipeline)
- 响应时间模型:两个tcp连接建立时间(往返传播时间)+响应体传输时间这就显示了不关闭连接的好处在于请求平均耗时会小于2RTT
 这就显示了不关闭连接的好处在于请求平均耗时会小于2RTT
这就显示了不关闭连接的好处在于请求平均耗时会小于2RTTHTTP请求的方法类型:
- GET、POST
- HEAD 只获取HTML的头,可用于爬虫、搜索引擎建立索引等
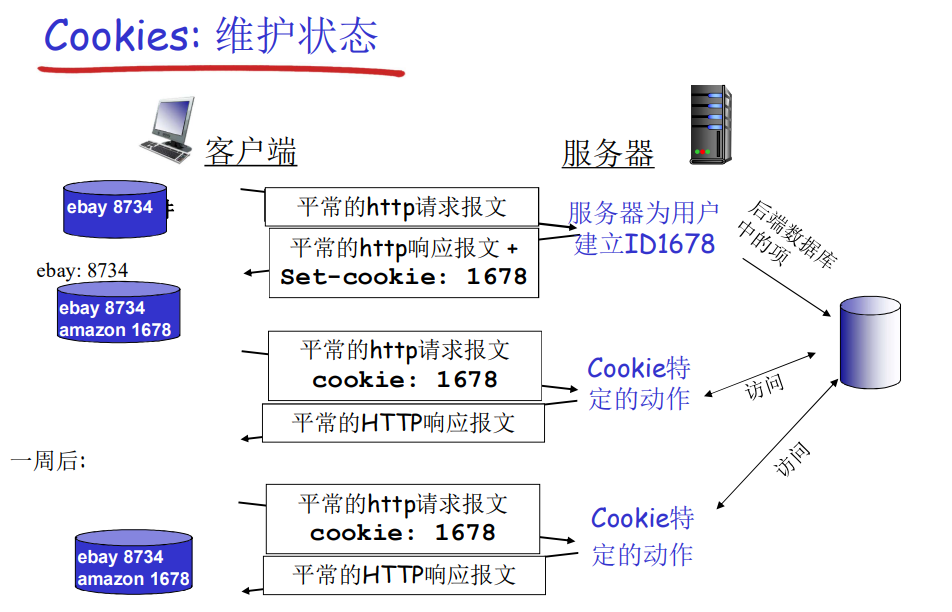
用户-服务器状态:Cookie
- 只要客户端的cookie文件和服务器端的数据库中对应的cookie都有存储,那么访问网站就会有用户信息的发送和维护
- 涉及隐私问题
Web缓存(代理服务器):不访问原始服务器,而是通过代理服务器满足客户的请求,原理和csapp的cache一样,命中缓存
条件GET方法:为了规避缓存和源服务器内容不一致的情况,每次缓存返回对象时,会先去向原服务器发送一个带有If-modified-since:<Date>的GET请求,用来判定是否需要更新,若需要则更新后再响应请求
chp2-3 FTP
文件传输协议是比较早的用于传输文件共享文件的协议,其工作流程大致如下:
- FTP客户端向FTP服务器发送建立TCP控制连接的请求,请求建立后客户端可以通过该连接进行查询LIST、上传RETR、下载STOR以及认证登录的USER、PASS命令
- 如果发生了文件的上传下载,那么FTP 服务器 就会向客户端发送一个建立TCP数据传输连接的请求,建立连接后文件的传输通过这个连接进行
- FTP需要维护用户的信息,以及用户目前处于什么目录,因此其是有状态的协议
chp2-4 EMail
由用户代理(邮件阅读器,即软件outlook)、邮件服务器、简单邮件传输协议(push为SMTP,pull为POP3、IMAP、HTTP)
邮件服务器管理用户的邮箱和发送给其他邮件服务器的发送队列,用户将邮件发送给邮件服务器,邮件服务器将其传入队列中等待发出,对方邮件服务器将其传入对应用户的邮箱中,对应用户通过pull类型请求获取邮件(服务器之间的发送邮件无中转服务器)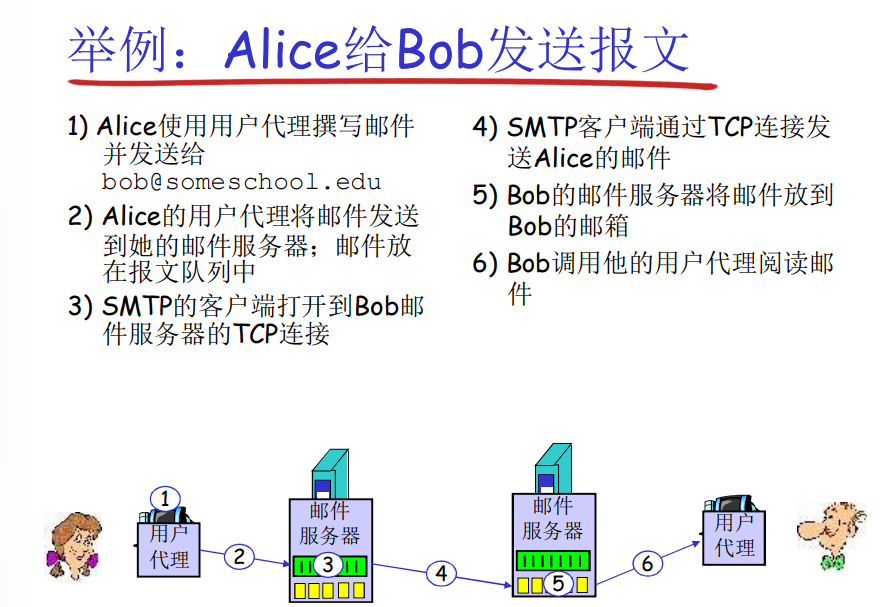
SMTP的特性:
- 持久连接,持续响应客户端发送的请求指令,知道客户端主动关闭
- 要求报文为ascii码,这意味着其他类型的语言或者文件需要通过编码来传输,具体的需要通过MIME多媒体邮件扩展声明来进行不同数据类型的传输
POP3也是持久响应客户端请求的,无状态,有下载并删除/保留两种模式,认为第二种模式适合于在不同客户机上获取邮件
IMAP可以管理远程邮箱的文件夹
chp2-5 DNS(Domain Name System)
必要性:用户需要可用性更强的域名来获取资源,而路由器只认ip,因此需要有一个
domain->ip翻译的服务器系统
命名问题
分层基于域的命名机制,同时还具有以下特性:
- 主机别名到规范名字的转换,比如运行Google程序的服务器不止一台,
www.ibm.com相当于别名,而他们服务器的规范名字servereast.backup2.ibm.com是用于特定服务器的 - 邮件服务器别名到邮件服务器的正规名字的转换,比如
sjtu.edu.cn->mail.sjtu.edu.cn,就好比邮箱地址hwqqz678@sjtu.edu.cn前面的是用户名,后面的是主机域名 - 负载均衡
DNS域名结构有许多“顶级域”,比如通用顶级域.com .edu ,或者国家顶级域.cn .us等,每个域下面可以划分为若干子域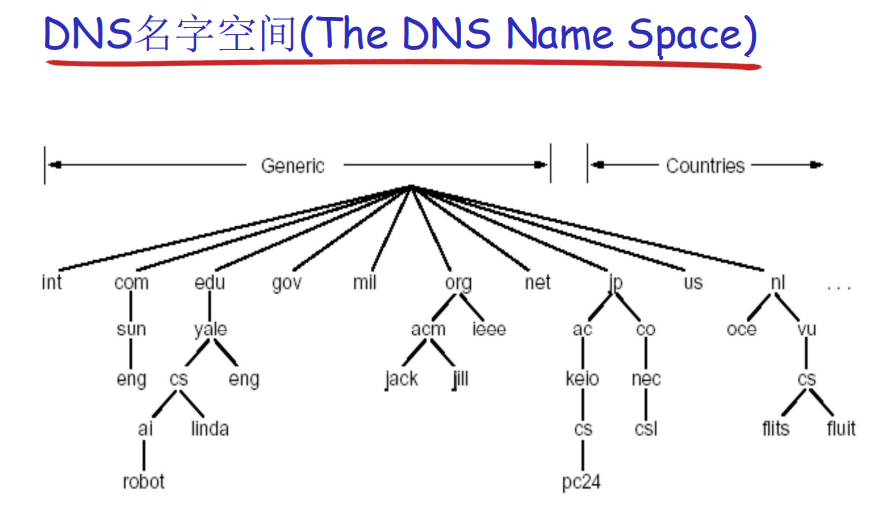
同时,域名这种东西不只是有主机有,一个域也可以有域名;一个域的主机可以不在一个网络,一个网络的主机不一定在一个域(域不是物理的)
名字服务器与DNS服务器
- 名字服务器:每个域(zone)都有一个名字服务器,维护它所管辖的区域的权威信息,可以被放在域外,这些权威信息由各个权威DNS服务器提供
- 权威DNS服务器:组织机构的DNS服务器,提供组织机构服务器可访问的主机和ip之间的映射;顶级域(TLD)服务器作为顶级域名(通用/国家)的权威DNS服务器;可以认为权威DNS服务器也是一种名字服务器
区域名字服务器维护资源记录
| Domain_name | TTL | Class | Value | Type |
|---|---|---|---|---|
| 域名 | 生存时间(长期或者限时) | 计网范围下为IN | 根据Type而定 | 见下表 |
| Type | A | CNAME | NS | MX |
|---|---|---|---|---|
| Name | 主机域名 | 别名 | 域的域名 | 邮件服务器域名 |
| Value | IP | 规范名 | 域的权威服务器的域名 | 邮件服务器名字 |
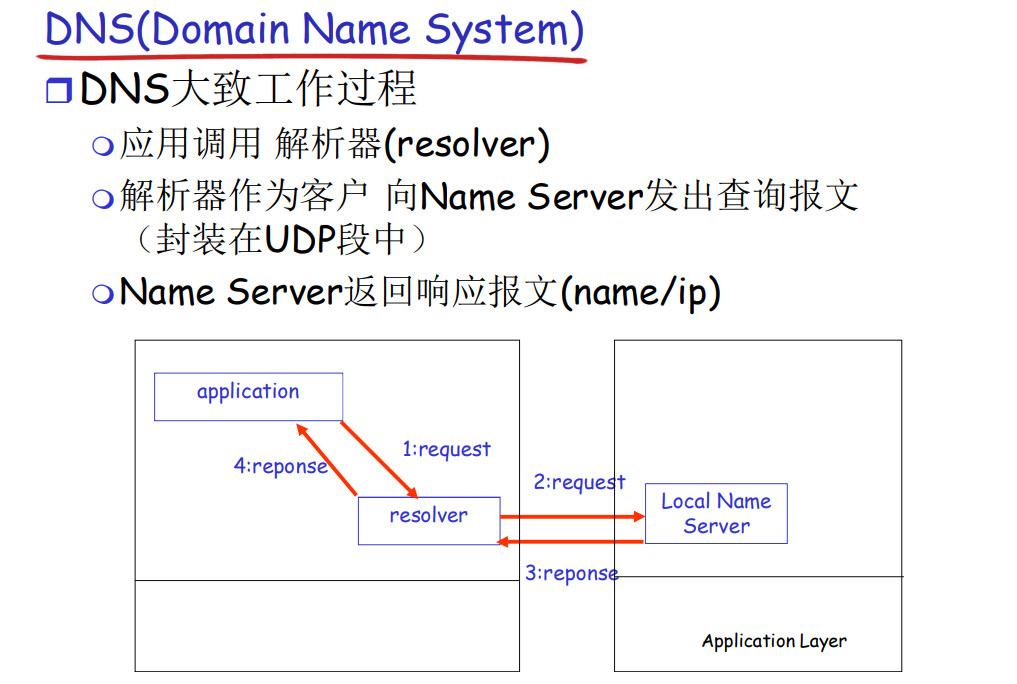
解释一下local name server是就近的名字服务器,不是本地的意思
现在的问题是name server怎么解析的?
- 目标名字在local name server内,可能是因为这个名字本身就在这个域内部,或者这个名字曾经访问过有个缓存在里面
- 递归查询:从本地DNS上溯到根服务器上,然后从根服务器往下查找;这个的问题是根服务器负担比较重,因为根服务器要发送向下的查询请求,还要向起点转发查询结果
- 迭代查询:向根查询之后根返回一个“你应该向谁查”的NS地址,最后由权威名字服务器给出解析结果,这样就是起点不断向不同的NS来请求,根服务器的负担就没有那么大
一个DNS协议的报文需要涵盖ID,这样是方便于DNS服务器执行转发查询请求的时候可以流水操作,因为有ID标识每个请求的归属方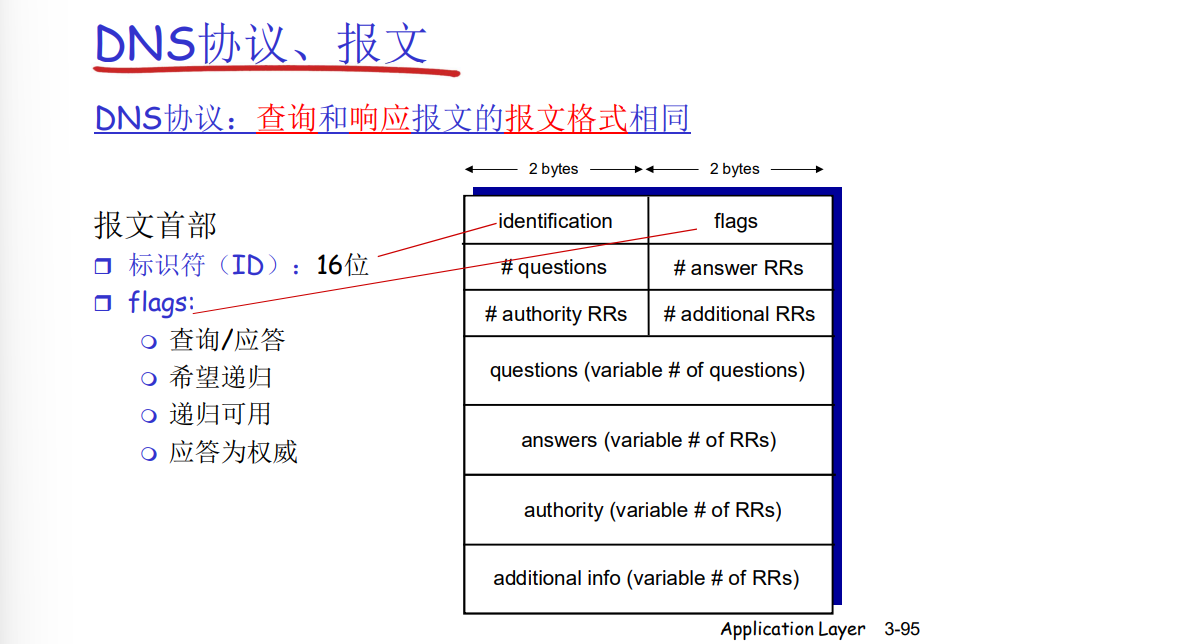
如何新增一个域? 向上级域的名字服务器添加:指向新增子域的域名 和 域名服务器的地址,即一条NS一条A
总体来说DNS比较健壮,不容易被攻击
chp2-6 P2P
在文件分发的需求中,使用C/S架构和P2P架构的区别:
- C/S架构的流量速度下限为$max{\frac{NF}{u_s},\frac{F}{d_i}}$,其中前者是多上传任务的时候服务器的带宽占用情况和传输速度;由此可见该架构可拓展性一般
- P2P架构的流量速度下限为$max{\frac{F}{u_s},\frac{F}{d_{min}},\frac{NF}{u_s+\Sigma{u_i}}}$,第一个是服务器第一次向peer节点发送的速度,第二个是单个peer节点的下载速度,第三个是P2P系统对所有文件请求的总的上传能力的速度;比C/S模式更适合文件传输系统的构建
P2P的结构分为非结构化P2P和结构化(DHT)P2P,结构化指的是每个节点是有一定数据结构(环、树)的,以下是 非结构化类型 的介绍:
- Napster:中央服务器维护资源目录,peer节点作为客户端和服务端,在中央服务器的导引下进行音频的上传和下载服务
- 当节点的Napster客户端上线的时候,会告知中央服务器其IP、所有资源的信息,标记其已经上线了;下线的时候也会告知中央服务器
- 问题:中央服务器单点故障、性能瓶颈,可能的侵权问题
- 结局:被唱片公司告了,判决拔网线终止提供服务
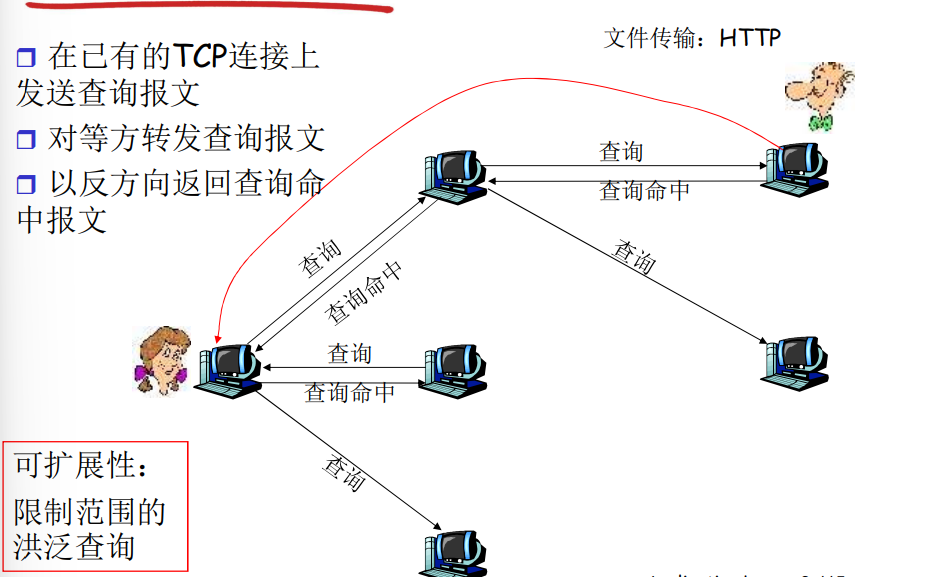
- Gnutella:全分布式架构无中央服务器,通过图数据结构构建网络关系,获取资源的方式是先向邻居节点查询,如无结果则由邻居节点出发继续向外传播查找请求,最后一层层将获取到的资源所在对象转发到源节点
- 对等方上线并加入的流程为
- Gnutella客户端在下载的时候会给一个比较可靠的10个节点,帮助其寻找网络的节点
- 上线的时候基于可靠节点先建立一个连接,然后通过这个可靠节点向其他节点发送ping报文
- 其他节点收到ping报文后响应pong报文,上线节点选择一些pong过来的节点作为邻居节点
- 为了避免重复请求节点的情况发生,通常可以采用标记已请求节点等方式
- 结局:效果不好,速度慢,没人用
- 对等方上线并加入的流程为
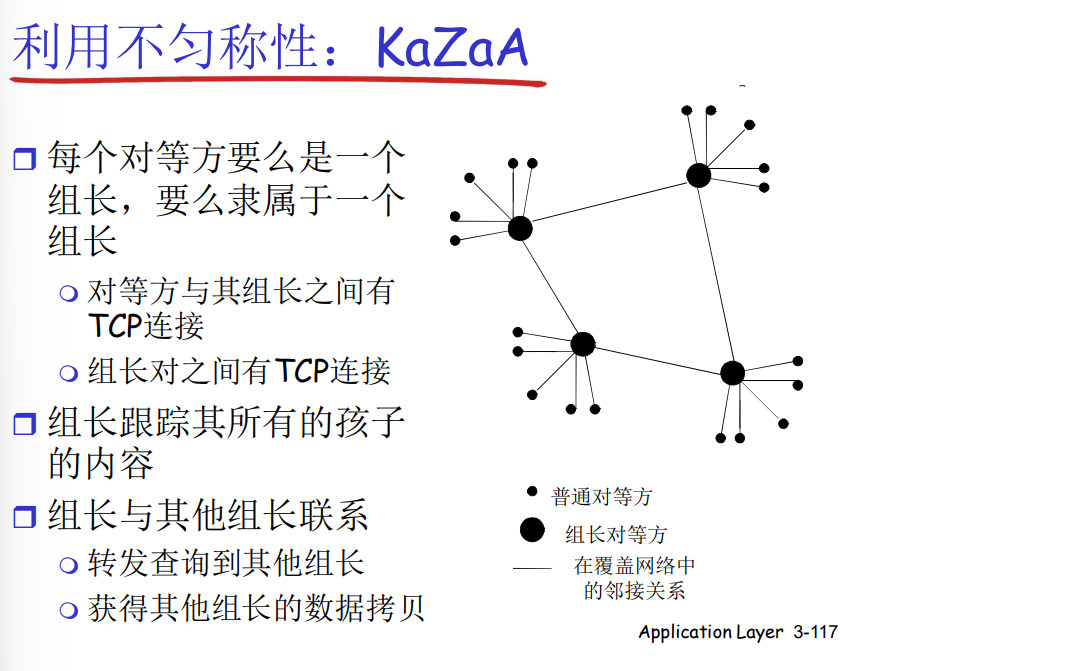
- KaZaA:是集中化目录和完全分布式的结合体,通过组长和组间的关系,分别采用集中化目录和完全分布式的架构来实现P2P架构
- 每个文件具有一个描述符(描述文件信息)、hash码(唯一标识),客户端可以基于描述符进行查找所需的资源,再通过选择hash码来定位并请求特定的资源(向拥有文件的对等方发送一个带hash码的HTTP请求
BitTorrent
这也是一种非结构化P2P架构,文件被分为一个个256KB的块,分别存在不同的网络中的peer节点中,每个节点维护一个对于该文件的bitmap,里面用布尔位来标记自己拥有文件的哪些块
- 新节点加入torrent:一开始没有块的时候随机向网络中节点请求若干个块,并且向跟踪服务器注册,获得peer节点的列表;拿到基本盘之后去请求比较稀缺的块,这有利于整个系统的可用性(稀缺的块拥有者少,下线概率较高),以及有利于自身成为香饽饽
- 一个peer节点可以上传和下载文件的块,对于一个服务方,他会在2/3周期内将传输资源优先给“周期内为其提供良好上传服务”的节点,在1/3周期内随机选取节点进行优先传送,这主要是为了鼓励用户不仅要下载还要上传的机制
- 一旦peer拥有了整个文件,他可以选择立即离开或者继续利他地为其他节点提供上传文件的服务
结构化P2P介绍相对简单,举了一个环状例子,一个环状网络每一段弧有一个组长,请求按照环结构请求各个组长,随后再向具体的有服务节点进行传输请求
chp2-7 CDN
视频文件过大,不适合传统的文件传输方式,因为要确保一个实时的播放
视频
- 定义:固定速度的图像序列,一张图片是一帧(frame),一帧由若干像素组成
- 编码压缩方式:时间冗余(临近帧相同位置相同像素坐标可进行压缩编码,比如只记录前后帧的差异)、空间冗余(相同帧临近位置相同像素坐标可进行压缩编码,比如记录某个颜色在几个相邻像素中重复)
DASH(多媒体流化服务,Dynamic, Adaptive Streaming over HTTP)
- 服务器端的视频是分块、不同的分辨率各有备份的存储的,通过manifest file(告示文件)来提供不同块的URL
- 客户端先从总服务器端获取告示文件,再通过其中的URL获取视频块所在位置,获取视频块
- CDN(Content Distribution Networks,流媒体加速服务),由CDN供应商提供CDN缓存服务器(不在网络核心,目的是和客户端距离更近,分担流量),用来布局于众多的节点上,内容提供商(ICP)租用CDN供应商的服务将视频块分别缓存在其名下的众多CDN缓存服务器中;用户先从ICP处获取manifest file,然后导引到CDN的就近的服务器,开始下载视频块;视频块支持一边下载一边观看上图展示了通过CDN服务提供服务的ICP视频提供商,用户端的请求流程
- 内容提供商视频一经上线就要添加到cdn缓存服务器中
- 从页面连接获取到该视频的URL 6Y7B23V
- 从local dns服务器查找该URL所在主机,找到ICP方的权威dns服务器
- 提供一个指向cdn服务商的URL,请求重定向到cdn服务商的权威dns服务器
- 根据算法分配一个就近的cdn缓存服务器,之后就从这个服务器获取视频块即可
 上图展示了通过CDN服务提供服务的ICP视频提供商,用户端的请求流程
上图展示了通过CDN服务提供服务的ICP视频提供商,用户端的请求流程chp2-8 TCP socket编程
再学一遍感觉理解更加深刻一点,之前还是网络基础太差了
TCP socket编程是通过先建立TCP连接,并且获取到连接所对应的socket值,再对socket对应的TCP连接进行read/write操作,即可进行应用层面的数据传输
服务端/客户端过程:
- 服务器创建欢迎socket,与本地端口捆绑,使用
listen函数定义请求等待队列的长度,使用accept函数进行一个阻塞式的等待连接请求行为 - 客户端创建连接socket,隐式与本地端口捆绑(因为不是很重要),指定服务器的IP和port之后通过
connect函数来发送连接请求 - 服务端接收到来自用户端的请求之后,由此基础上新建一个对应于该TCP连接的连接socket,用来标识该TCP连接并以此为基础通信;客户端socket此时也成功标识到了该TCP连接;两者可以通过
read/write系统调用,将socket视作文件fd来进行读写 - 客户端/服务器关闭连接,服务器程序继续等待新的连接
数据结构sockaddr_in:
1 | struct sockaddr_in { |
数据结构hostent:
1 | struct hostent { |
现在看就看的很懂了^_^
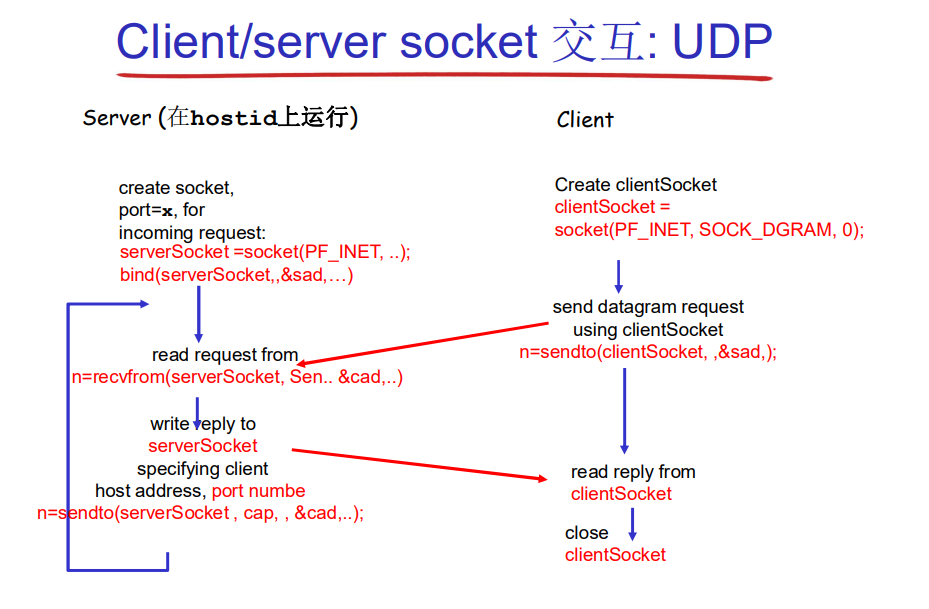
2-9 UDP socket编程
udp不需要建立连接,在编程上的体现是建立套接字后:客户端不需要connect函数而是直接sendto中传数据报datagram和服务端IP+port即可;服务端只需要recvfrom等待客户端发出来的东西并且保存其位置,随后将响应发给他就好