RDMA入门记录
Weiquan Huangchp1 Intro
- 通过RDMA传输的数据,会直接跳过操作系统(CPU),从软件层直接到硬件层并直接发送(需要有RDMA网卡)
- 传输数据不需要经过操作系统,但是如果是为了传输而创建资源的过程(比如queue、连接、device driver),则需要经过操作系统
- RDMA会直接将数据传送给目标主机的对应内存地址,所以叫做Remote Direct Memory Access
- 普通的传输会先将数据复制到内存的某个buffer内,然后传到接收方的buffer内后复制到真正的存储位置;但是RDMA号称Zero Copy,也就是说不会进行buffer的复制,而是直接从对应位置获取数据到物理层,并且直接将数据发送到目标的内存位置
- RDMA的传输一方面具有TCP的可靠性和连接性,另一方面具有UDP的速度和可拓展性(scalability)
补充
- 跳过操作系统主要是跳过CPU,因为内核主要是通过CPU来进行管理的,而CPU在网络通信中充当的是一个copy的角色,比较浪费宝贵的计算资源(因为TCP/IP的封装需要内核,因此用户内存区域的数据会复制到内核内存区域,同时封装了TCP/IP报头的数据需要复制到内核的网络缓冲区,相当于做了很多次copy);RDMA封装报头通过硬件封装,主要作用是给CPU腾出计算资源
- RDMA发起的单方面通信,对方的CPU是不感知到的,但是仍然要具有能够访问对面内存空间的key
- DMA是一个用来分担CPU传输RDMA数据的中转站,用于寄存数据,便于RAM和网卡的数据交互
chp2 Basics
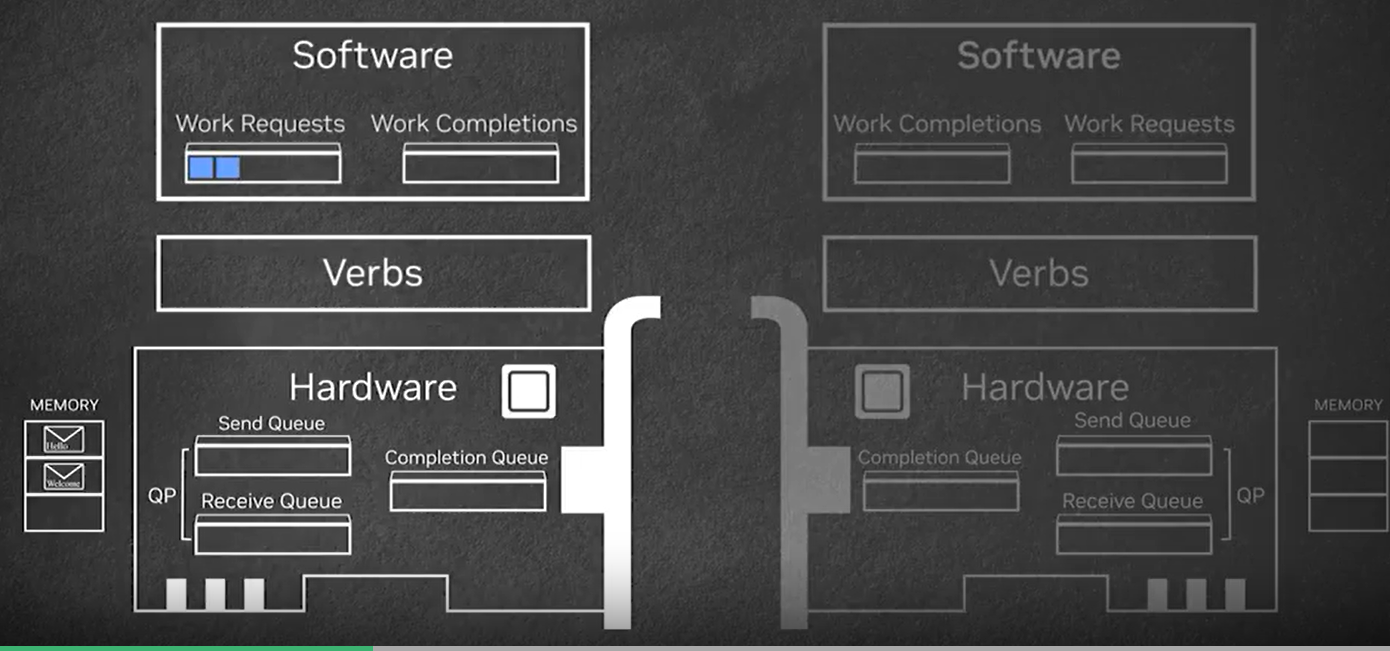
- RDMA的编程接口是Verbs APIs,具有request、completion、queue三种对象,request是应用层发给硬件的“指令”,completion是硬件描述完成request的情况,queue有request/completion/send/receive这4种,其中前两个存在于软件层,后两个存在于硬件层
- RDMA的数据传输流程见下图:首先软件向硬件的send queue发送request期望硬件发送数据给对方,request从send queue出去之后就会被执行,将在某个位置的数据直接传给对应主机,并向软件发送completion表示完成请求;接收方会发送接收准备相关的request,通过receive queue,这会使得数据传向指定的内存区域

- RDMA的内存管理除了具有ICS讲述的内存管理的一系列机制外,还有诸如“权限控制(本地/远端访问)”、“内存锁定”、“硬件直接访问内存”的附加功能
补充
- rdma 接收端的recv work request实际上是在接收端准备好注册了的内存资源之后就会去预先向接受队列中放入recv work request,这样这些内存空间可以直接被远程的sender写入内存中;内存被写入后,接收方会接收到通知,将recv request标记为完成,根据需要继续放置新的recv work request
- 专有名词:
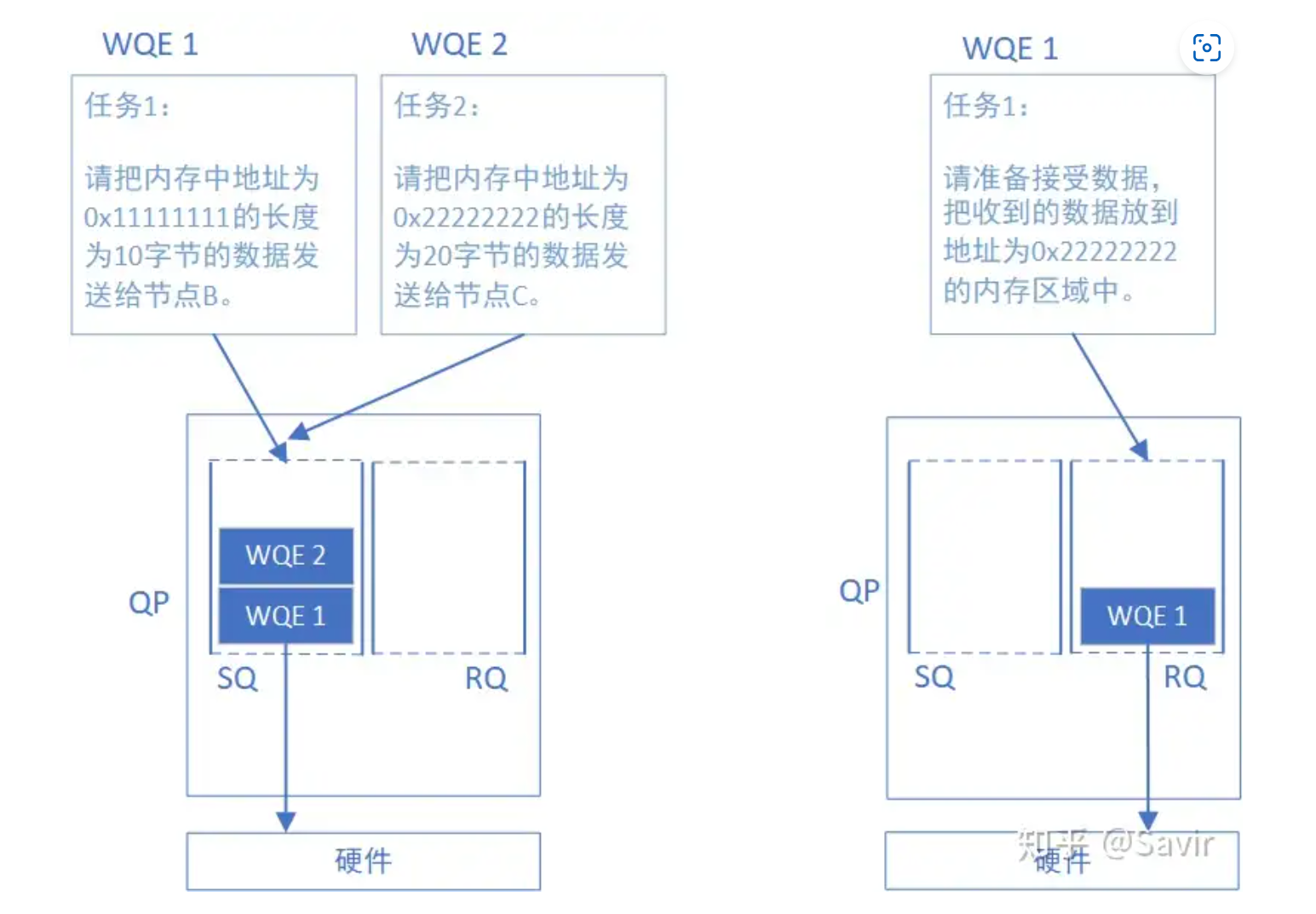
- work queue WQ 用于存放WQE,在内存上
- work queue enrty/element WQE 是软件向硬件发送的rdma数据传送指令,这种告知硬件的方式被称为post
- queue pair QP 指的是一对SQ和RQ
- send queue SQ receive queue RQ 都是WQ的一种
- RDMA技术中通信的基本单元是QP,每个进程可以有多个QP,每个本地QP可以关联一个远端的QP;我们用“节点A的QP3给节点B的QP4发送数据”来描述一次RDMA通信QPN是一个节点的编号number
- shared receive queue SRQ 共享接收队列,即几个QP共享同一个RQ的时候,这个RQ就是SRQ;由于RQ相对于SQ使用较少,而且消耗内存资源,因此可以通过这种方式来节省内存
- completion queue CQ 完成队列,其承载的单元为CQE,作为硬件发送给软件的WQE任务报告,描述任务被正确执行与否,以及错误原因
- 整个流程,注意硬件是需要在收到send request/write request之后才会触发将RQ内的WQE发送给硬件进行处理的动作同时注意如果是非可靠性传输,那么不会有ACK,同时发送端将数据传送到链路层之后直接生成CQE
- work request, work completion WR/WC 这是在API语境下的工作请求和工作完成,通过API下发WR/WC,驱动会发送WQE/CQE给WQ/CQ
- 根据AI的说法,接收方会先将自己接收队列的信息给发送方,这样发送方可以根据这些信息选择性的去发送数据,做到发送接收的目标地址一一对应
 QPN是一个节点的编号number
QPN是一个节点的编号number 同时注意如果是非可靠性传输,那么不会有ACK,同时发送端将数据传送到链路层之后直接生成CQE
同时注意如果是非可靠性传输,那么不会有ACK,同时发送端将数据传送到链路层之后直接生成CQEchp3 Operations
sendreceive一方面,接收方需要先由软件发送一个RR(receive request),让RDMA硬件准备好接收数据;另一方面,发送方会由软件发送一个SR(send request),让RDMA排队处理这个请求,具体是将内存对应位置的数据打包发送到链路层,并且生成一个completionwriteread他们是单方向行为,比如write是发送方单方面将数据写入到接收方的某个内存中(内存位置由发送方指定,接收方负责判断内存的有效&权限),以及read是发送方发送一个读取请求,而接收方负责从指定内存位置中返回数据给发送方atomic operations这是一种远程的原子操作,发送方向接收方发送一个操作某个数据的原子指令,接收方做出相应的操作,期间过程不会被打断,比如compare and swapfetch and add两种加锁原子操作序列
补充
- 单端操作指的是
writeread,以write为例,具体的流程如下:严谨的说,第6步的ACK只能保证数据报被远端网卡暂存而非发送了 - 单端操作需要能够访问远端指定内存区域的key,获取key一般是在send-recv过程获得,因为生成key总归是需要管理内存的CPU来参与的
- 事实上send-recv过程也需要CPU的参与,因为recv端分配接收buffer的时候需要告知CPU;而write/read才是真的不需要CPU的参与,也是传输大量文件所使用的操作(send-recv是用来传递控制信息的,write-read才是读写数据的大头)
- RDMA的可靠服务:使用了ACK机制、数据校验和机制以及保序机制,基本类似于计网中所学的TCP机制
- RDMA的连接:事实上连接就是一对QP互相具有对方的node和QPN,同时具有自己的一些QPC(queue pair context)上下文,用于存储自身QP信息;基于连接其实也就是基于QPC上记录的对方的QPN和node ip而已;而基于数据报的传送,一个QP不和别的QP建立连接,意味着他的数据可以发送给不同的QP,只需要这些数据自带报头即可
- R代表可靠,U代表不可靠,C代表连接,D代表数据报;因此有RC/RC/UC/UD 4种IB的基本服务类型
 严谨的说,第6步的ACK只能保证数据报被远端网卡暂存而非发送了
严谨的说,第6步的ACK只能保证数据报被远端网卡暂存而非发送了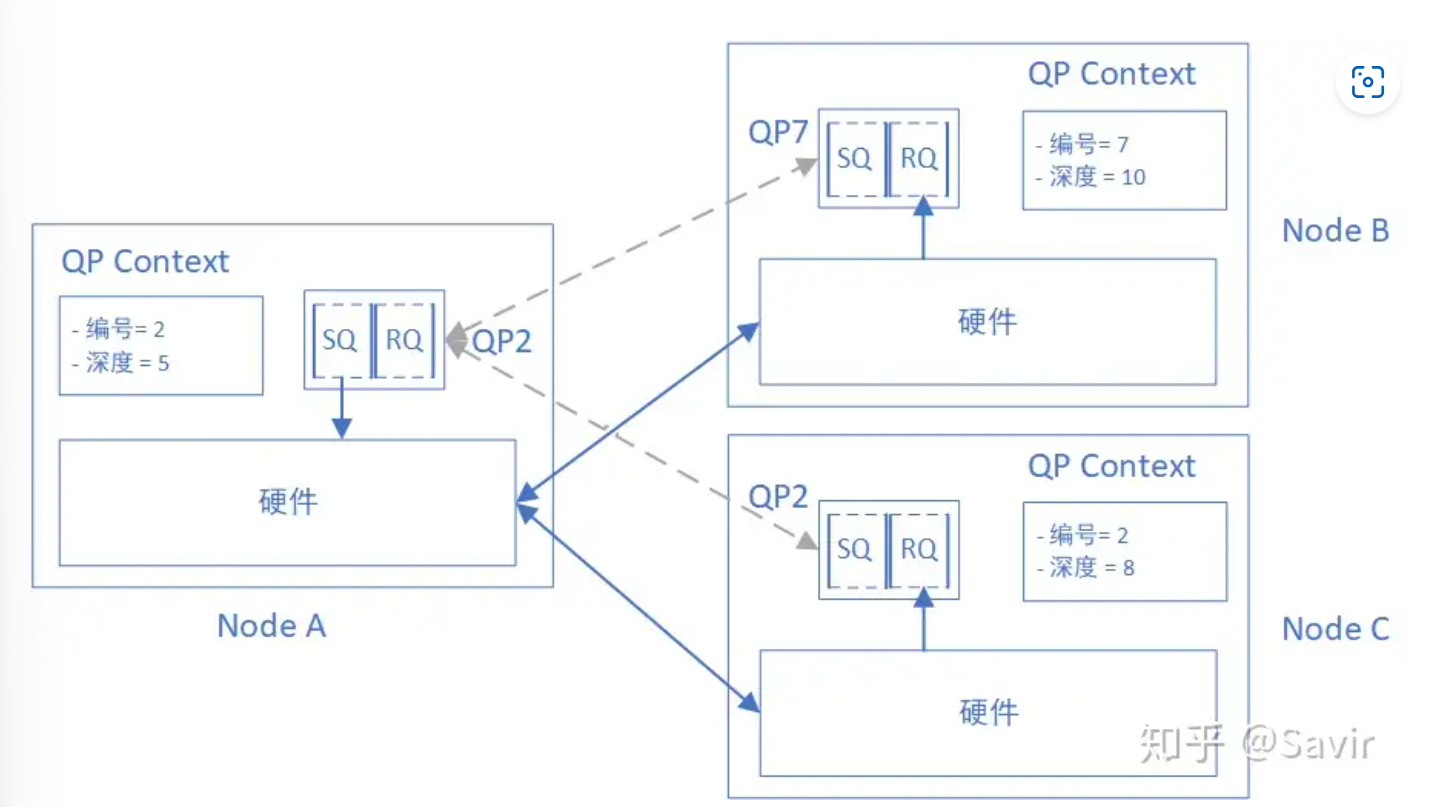
chp4 Fundational Code
- 注册内存
1 |
|
- 向send queue发送具有发送指令的work request
1 |
|
- receive,注意需要先分配空间再处理receive work request;同时支持一次性传入多个send/receive work request,这是通过send/receive work request的数据结构中蕴含了链表来实现的,在处理函数中会将链表内的请求一并处理掉
1 | //Post Receive Request |
- 查看completion的请求,completion会带上源请求的一些信息,同时会附带一些错误标识符号,具体的解释可以看注释
1 |
|
chp5 Connection
- RDMA建立连接需要获取地址信息,而地址信息又需要某种连接来交换这些地址;一种方式是out-of-band communication(带外通信),也就是借助不同的传输来交换地址,比如rc-ping-pong;另一种方式是communication manager(通信管理器),首先需要再连接建立之前交换MAC、IP、QP编号(类似于TCP端口)和数据报序列号等,同时还需要就MTU(Max Transfer Unit)达成一致等
- 而所谓的connection manager其实和TCP的连接步骤差不多,服务端
bindlisten,客户端connect,随后可以使用RDMA CM post send或者IBV post send来进行发送操作的编程

chp6 RCpingpong
- RCpingpong是一个用于性能测试的示例程序,可以测试连接的性能
pingpong_context是一个封装了RDMA操作所需的各个组件和状态信息的结构体,包括可访问内存区域ibv_mr *mr,完成队列ibv_cq *cqpp_init_ctx函数执行了初始化pingpong的上下文,比如- 创建一个
pingpong_context空间,并且分配一个可以用于send/receive的空间 ibv_open_device函数创建了一个应用程序和设备共享的内存空间,以设备作为参数传入,用途是应用程序和硬件设备的直接通信ibv_create_comp_channel函数用于创建一个completion_channel这可以让ctx和硬件通过一个完成通道来接受完成事件,而不是轮询地去查找完成队列ibv_alloc_pd函数用于创建protection domain,这可以确保内存区域的访问完全性,确定什么设备可以访问什么内存ibv_reg_mr函数用于注册内存,传入pd、ctx->buf、size、访问权限宏来注册内存以及确定访问权限,比如IBV_ACCESS_LOCAL_WRITE表示本地可写可读,但是外部设备无权限ibv_create_cq函数用于创建completion queue,可以设置队列的长度ibv_create_qp函数用于创建queue pair,可以设置send/receive的时间完成后的完成队列、容量、单次操作的内存块数量上限等ibv_modify_qp函数用于修改queue pair
- 创建一个
pp_close_ctx销毁的顺序和创建的顺序相反,因为销毁需要先销毁无依赖关系的项,比如先销毁qp再销毁cq是因为qp用到了cq- data path:数据如何传输
pp_post_recv将receive request发送给qp,传入context作为参数,以及传入要处理的buf数n,将context的内容封装到自定义结构体后通过ibv_post_recv传给硬件(work request的id可以设置为PINGPONG_RECV_WRID以及PINGPONG_SEND_WRID等pp_post_send将send request发送给qp,在定义结构体的时候设置了一些参数有一定意义:.opcode = IBV_WR_SEND表示可读可写.send_flags = IBV_SEND_SIGNALED表示completion会在成功发送后就之间创建main函数执行过程中,会先发送初始的send/receive request,同时不断监听cq,获取到完成的请求后检测其为send/receive,前者给scnt计数即可,后者需要根据outstanding receive work request和receive queue的数量比对判断是否要继续发送新的RR
- qp’s connection:qp的连接建立
- RCpingpong利用TCP来分享qp的地址,然后qp会互相连接
- 将本地qp和远程qp的信息封装到
ctx内,传入pp_connect_ctx中,将qp的状态设置为RTR(Ready to Receive) path_mtu是指最大传输单元,如果传输的数据超过了这个大小会被分解dest_qp_num是远端qp在远端的目的号码,类似于TCP port- 再将
qp设置为RTS(Ready to Send)状态
chp7 Memory Region
如何控制RDMA操作的可操作空间?如何规避单端操作下,发送端恶意采用关键内存的VA虚拟地址来破坏远端内存?MR的概念被提出
MR是一块特殊的内存,被注册了的MR才能被RDMA网卡直接访问;正常来说,VA到PA的转换是通过MMU和Page Table来实现的,但是要求RDMA不走CPU,因此对于VA/PA的转换需要在各自进程的内存中设置一块VA-PA转换表
控制HCA(硬件)访问内存的权限?通过local key和remote key来验证访问权限,local key验证本地的操作能否执行,remote key验证从远端传来的操作能否执行;在真正的RDMA通信之前,都会通过某些方式建立一条交换通信信息的链路并交换信息(建链、握手)
锁页机制:由于swap out机制可能会让注册的内存被换出,这样VA-PA映射关系就失去了意义,因为这肯定会导致映射关系的改变(该过程绕过CPU)。因此MR这块内存会被pin在物理内存中,完成通信才会让用户主动销毁这片MR
chp8 Protection Domain
保护域的作用主要在于,将特定的QPs和MRs设定在一个域中,只允许域内的QPs访问域内的MRs,如图,Node1的QP8无法访问Node0的MR1,因为首先QP8的数据会传送给Node0的QP3,而如果其想要访问的物理内存空间是MR1的空间,那么判定QP3和MR1不在一个PD中,就会拒绝访问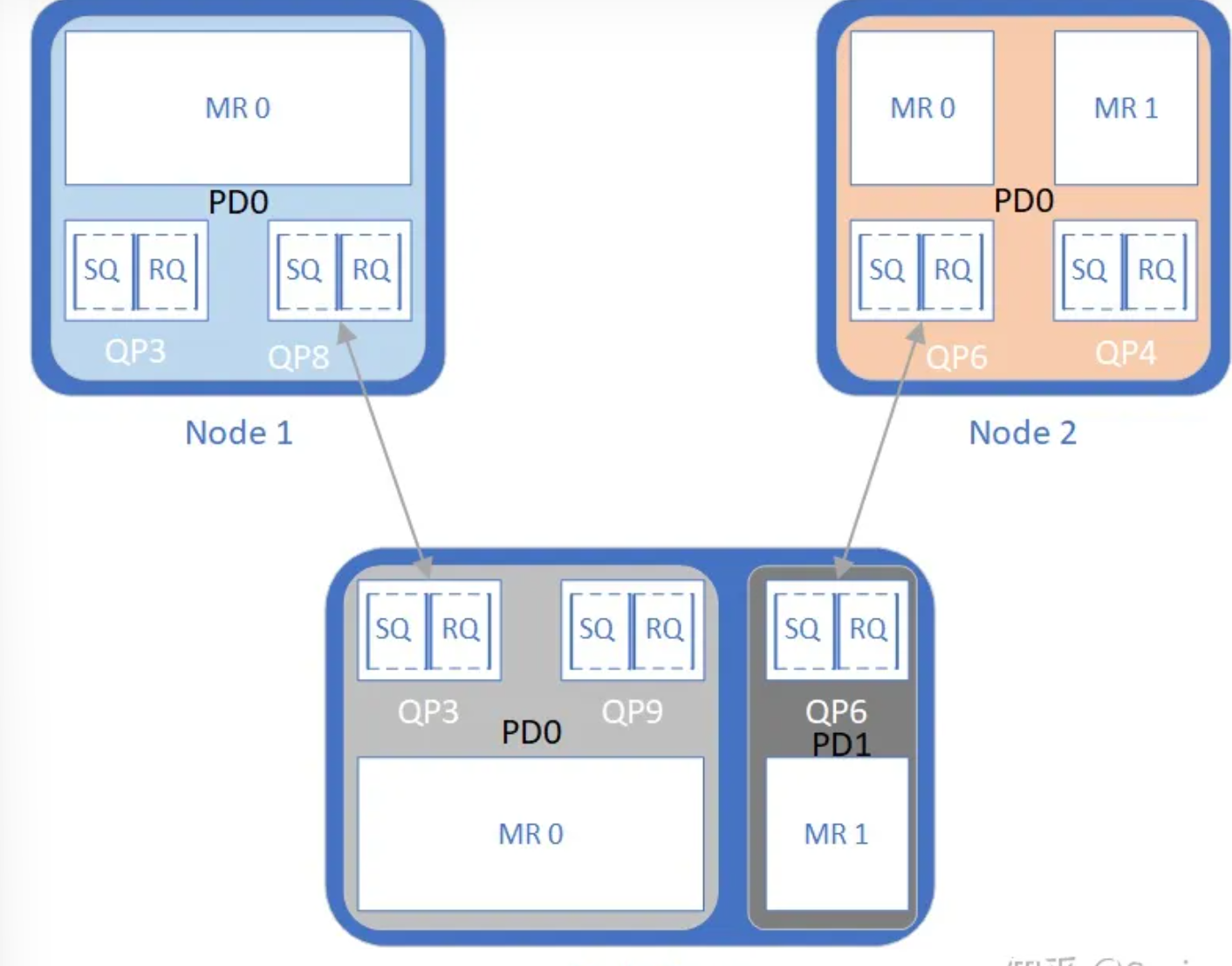
- IB协议中规定,每个节点至少要有一个PD,每个QP必须属于一个PD,每个MR必须属于一个PD
- PD在节点内可见,节点外不可见
- 创建QP和MR之前必须创建PD,然后传入这个PD的指针(或者称为句柄)
chp9 Address Handle
AH是存放目标节点信息的对象,在进行UD服务类型的通信之前,用户需要先为每个可能的对端节点创建一个AH,每个AH被创建的时候会返回一个索引给用户,用户在下发WR的时候直接传入这个索引,就可以附加上目标节点的信息了。在IB协议中,标识目标主机的是GID和MAC地址
创建AH的过程是内核态的,AH也受到PD的管理
chp10 QP
为什么需要QPC?在硬件中,QP的实体只是一段存储空间,只知道起始地址和大小;需要开辟一块QPC的空间,存储各个QPC的信息,方便查找对应QPN的QP的信息状态等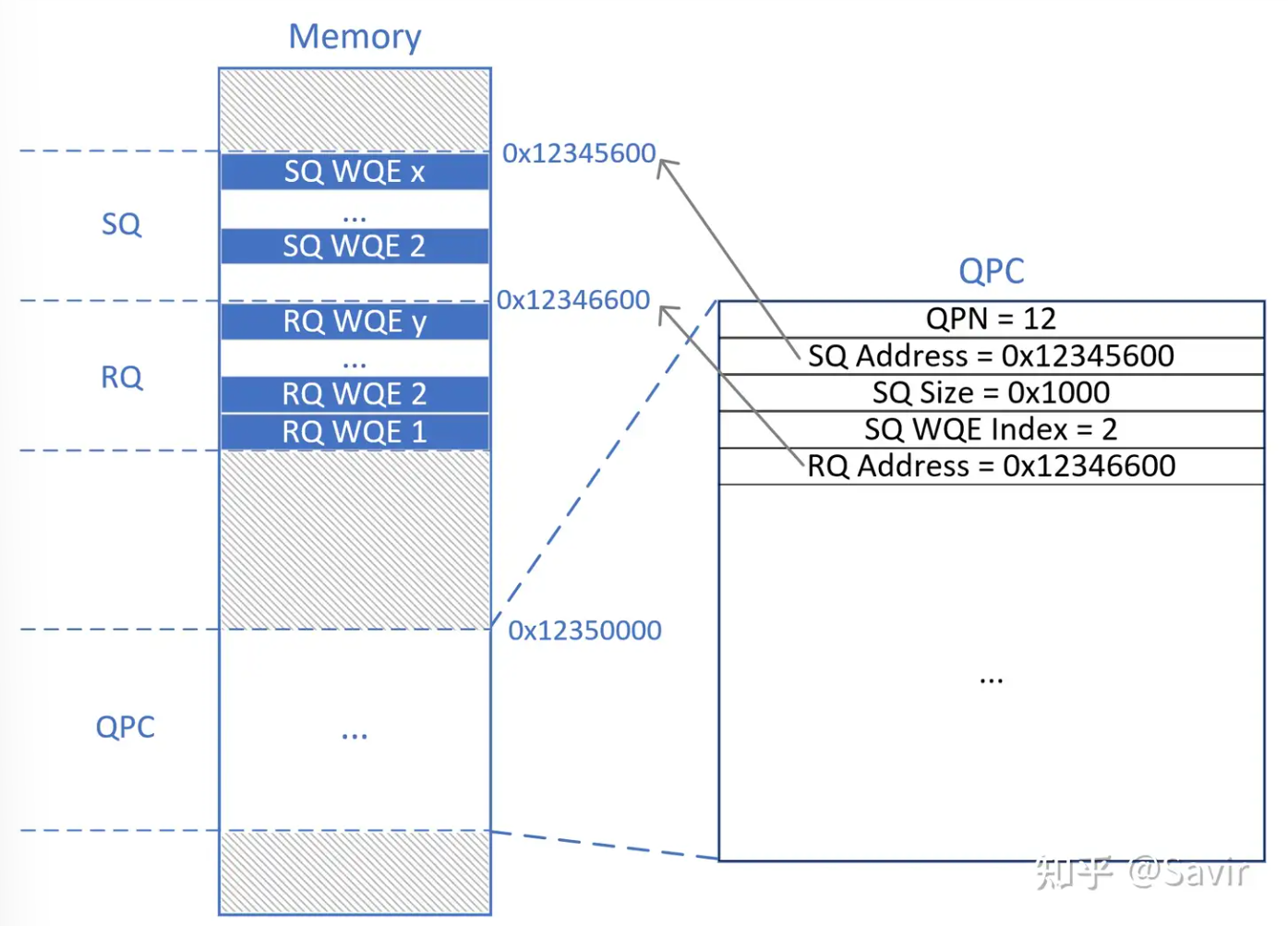
一个QP对上层的接口,有send/receive两种,send代表通信过程发起方的操作(包括send/write/read),receive就是recevie,发送请求的叫法为post send/receive request
- SQ Drain表示要处理完旧的WQE才会处理新的WQE
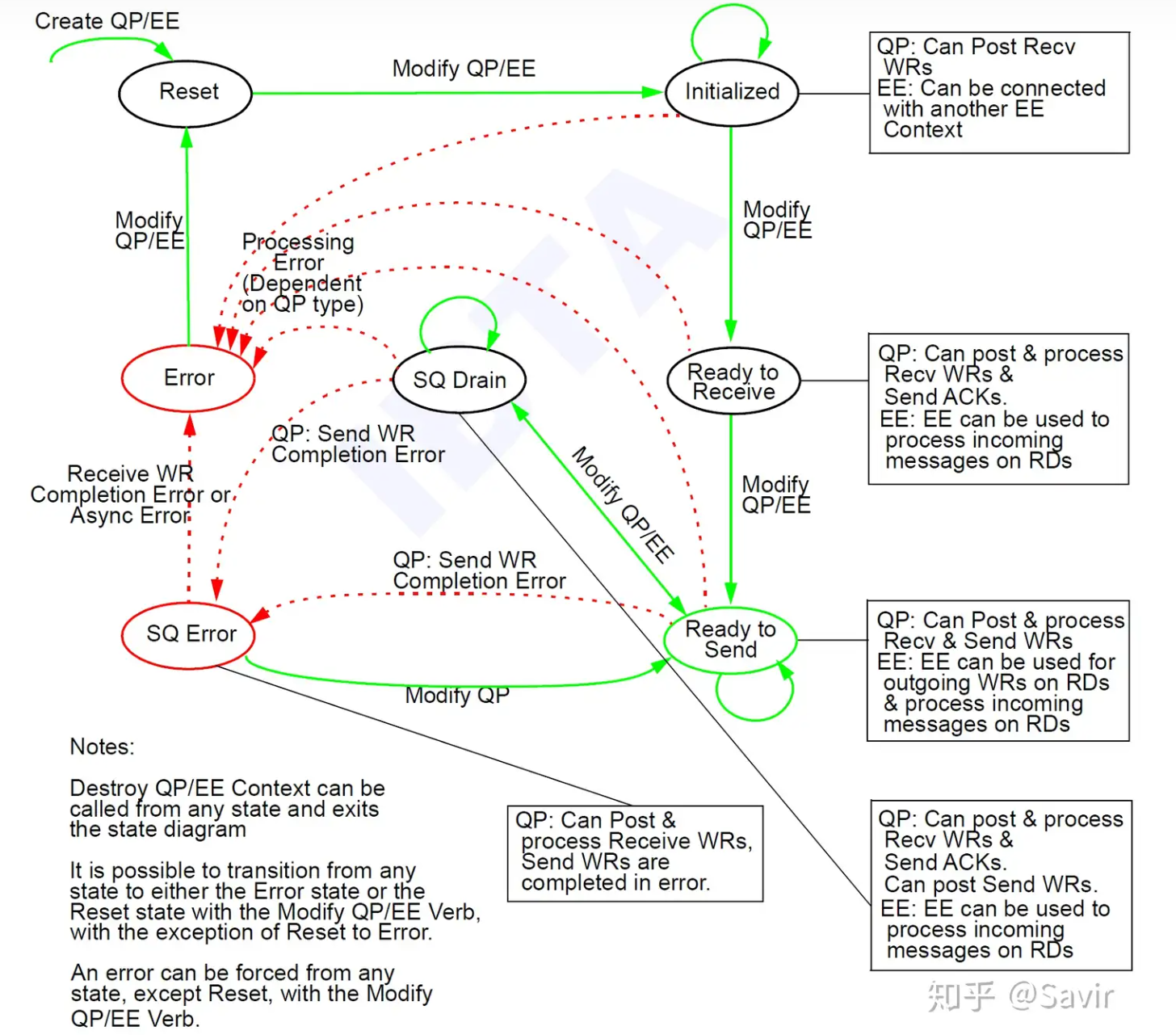
chp11 CQ
当一个WR对应的WC没有生成的时候,WR对应的内存区域的内容是不可信的,区域是被占用的,因为这意味着传输并没有完成。在RC的通信中,发送方需要接收到接受方的ACK才能生成WC;UD通信,则只需要发送出去就可以生成WC;recv操作则是成功写入后就会生成WC
- 一个CQ可以和多个RQ/SQ关联,而一对QP中的SQ/RQ可以各自关联不同的CQ
- 对于同一个WQ的WQE,会按照WQE在WQ的顺序先后生成CQE
- 对于WQs之间,不能保证生成并放入CQ的CQE的顺序的
- 同样也需要CQC(context)来记录信息,方便硬件查找
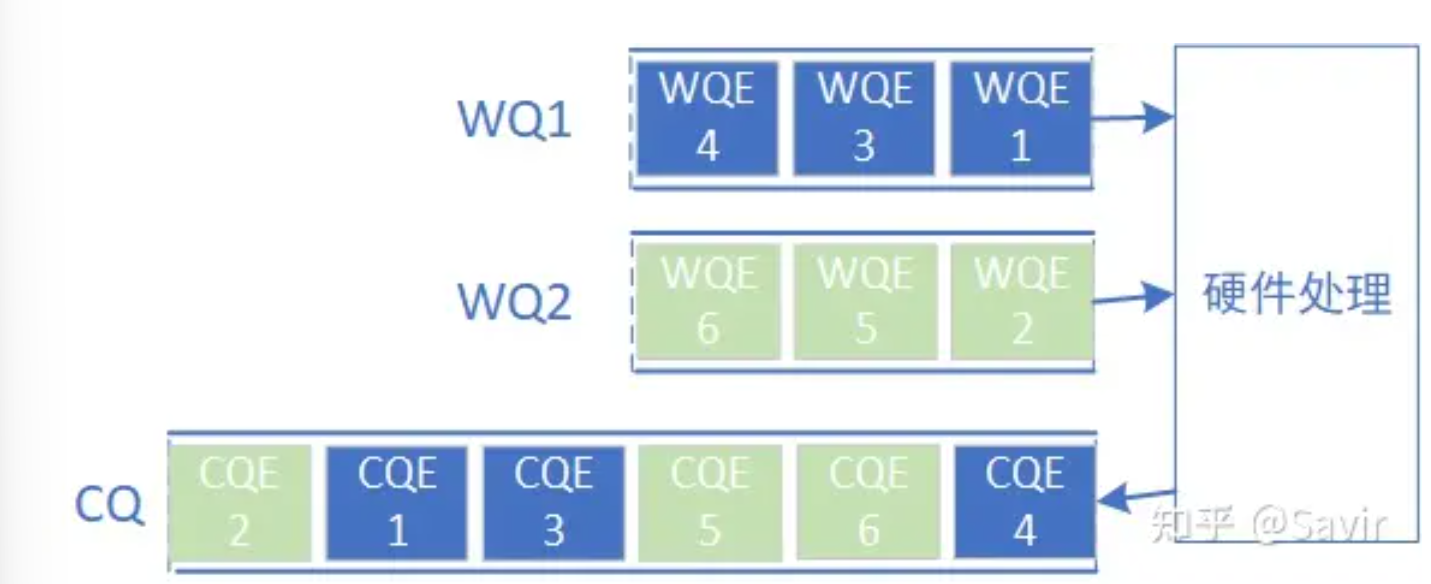
IB协议的3种错误类型:立即错误immediate error、完成错误completion error、异步错误asynchronous error
- 立即错误:立即停止操作,返回错误给上级用户;比如post send的时候传入非法操作码(ud write),立即退出post send流程,回收WQE
- 完成错误:通过CQE将错误信息返回给上层用户;比如WQE长时间没有接收到ACK,因为WQE到达了硬件,所以硬件会产生对应的CQE
- 异步错误:通过中断事件的方式上报给上层用户;软件一直没有取出CQE,过多的CQE导致CQ溢出,没有从CQE中得到信息,IB就会调用事件处理函数
完成错误:可以是sender在本地检测到的,或者在ACK/NAK中检测到的;也可以是receiver在本地检测到的。都会将错误信息添加到CQE中

理解软件何时以及如何接收到来自硬件的CQE?
- 中断模式request completion notification:网卡收到数据包之后立即打断CPU,让CPU先去处理网卡的数据包(每个RDMA网卡都会注册一个事件处理函数来处理异步事件)
- 轮询模式poll completion queue:网卡收到数据先存到缓冲区,CPU每隔一段时间去将缓冲区数据带走一波进行处理
- 现在一般根据业务的需求量来动态的确定使用中断模式还是轮询模式
chp12 SRQ
SRQ主要就是为了解决由于RQ不被经常使用导致的内存资源浪费的问题,在常规的RQ中,为了预防比较坏的情况,软件都会向QP中的RQ发送足量的接受WQE,而这些WQE不仅本身占据空间,而且他们所蕴含的内存区域也被视作是不可被其他操作占用的,而且这些空间也很难说会被用到很多。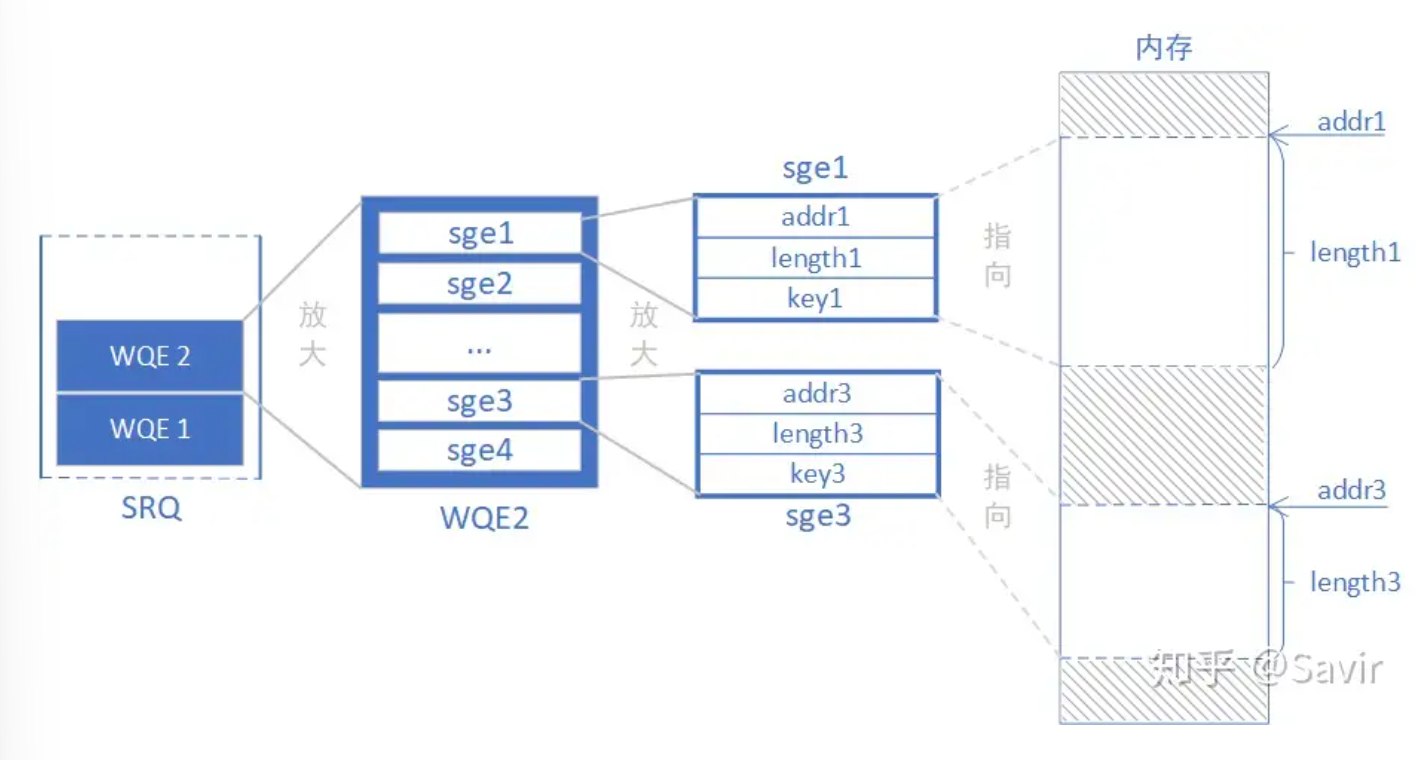


和RQ的区别就在于,与之关联的QP都会通过这个SRQ来发送WQE
chp13 Memory Window
可以理解为Memory Region的子集,也是用于数据的获取和访问,但是提供更为灵活的权限控制,本身也是绑定在一个已经注册的MR上
首先访问一块远端的内存,需要远端内存支持来自远端的访问(Remote Read/Write),还需要访问者持有Memory Key才能访问这段MW/MR,Key分为L_Key和R_Key
MW的作用主要是提供不需要陷入内核态的属性修改,由于MR是内核管理的,因此其修改的时候是需要经过内核态的
权限之间的关系
bind将MW关联到MR上,并且生成Key,配置读写权限;有MW绑定的MR不能取消注册;方式:post send bind MW WR或者bind MW(前者的封装)invalidate用于无效化R_Key,分为Local invalidate和Remote invalidate,区别是本地将R_Key取消,还是远端将自己所用的访问本端的R_Key取消

MW的类型(遇到再学)
chp14 Verb API
12. RDMA之Verbs - 知乎 (zhihu.com)
控制层面经过了多次陷入内核态的函数调用后,数据层面就不需要通过陷入内核态的调用了;陷入内核态主要是上下文的切换、权限等的更改,比较耗时
chp15 prp prepare study
UD RC DCT
UD相对于RC的加速并没有UDP对TCP的加速来的明显,因为TCP/UDP经过了软件层,那么握手的耗时确实比较长一些;UD的优势主要是,一组QP可以自由地向不同的QP发送读取请求,而不是像RC一样QP-QP绑定链接
- UD的MTU(Maximum Transfer Unit)比较小,导致需要在接收端重组的频率比较高,需要programming effort
- UD的目标定位头部还是比较大的,40B
- 不保序
- 会丢包,无保证机制
chp16 programming tutorial
Home · jcxue/RDMA-Tutorial Wiki · GitHub
Example 1 RDMA send/recv
创建RC类型的连接所需步骤
- 本地获取IB设备,打开IB设备,创建基于设备的
context - 创建
protection domain,获取RDMA网卡设备的port等信息(attr) - 注册
memory region,基于pd,需要手动管理;允许on demand page,因此不需要强制pin(机制不清楚) - 利用设备中的
max_cqe等信息创建cq,基于max_wr创建srq - 基于
cq和srq创建qp,指定链接方式为RC - 连接
qp:以服务器端为例,连接并且交换信息的时候使用socket通信,获取远程RDMA设备的qp_info,将自身和远端各自配对的qp发送给远端(有个rank属性用来标识自身信息,可用于标识连接信息并确认向哪个socket发送),将自身的qp设置为Ready to Send状态
解析服务端的pingpong操作
- 服务端创建“客户端数量个”线程用于处理和客户端的连接
- 服务端预先
post_recv,并发送一个带有提示对方信息的post_send提示对方请开始请求,随后poll_cq,每次接收到recv类型的完成则计数、继续发post_recv并且发回一个post_send来做pingpong;最后统计到了一定数量达到warmup状态开始计时,达到结束状态结束计时,告知对方结束,并关闭连接 - 已经可以确定RDMA在接收到一个
send请求时会触发recv的出队,由recv来给数据分配空间,将空间信息传给send的ACK和cqe,以告知双方应用进程
以前的RDMA硬件不支持处理page fault,无法换页,因此需要将memory region给固定在物理内存上;现在的RDMA硬件支持处理page fault,可以换页也就是on demand paging,因此不需要强制pin;注意在RDMA one-side操作上远程OS与CPU是无感知的,因此远程的软件不会参与page fault的处理
Example 2 RDMA write
相比较于send/recv,write操作需要提供raddr和rkey,用于远程虚拟地址定位和远程认证;由于write属于one-side操作,对侧无感知,因此对侧需要监控即将要被写的虚拟内存区域来进行接收到信息的确认
新优化方法:selective completion
在发送post_write的时候,设置SEND_SIGNALED会使得时间完成后生成completion,否则默认不生成;然而每次都生成其实意义不大也会增加开销,而每次都不生成,则会导致send queue没有能够出队的wqe,因为只有产生了completion的wr才能够被出队;而只要某个wqe出队了,那么在这之前的都会被出队。所以要选择性完成,比如1000次一个有signal的
Example 3 Opt Tech
常规下,ibv_post_send返回只代表wr被发送到了RDMA设备的send queue(MMIO方式),而wr维护了指向所欲取内存的地址,执行命令的时候需要通过DMA方式将数据传送到RDMA设备并发送(DMA>MMIO)
message inline
将小规模的数据附带到WR中,硬件支持的WR大小不确定因此需要软件自己试错并指定,指定WR的send_flags为IBV_SEND_INLINE
实际上优化效果一般
message batch
可以给wr设置一个链表,第一次通过MMIO传输wr,后面通过DMA传输message和剩余的wr
实际优化效果:高并发不好,低并发好;batch size不是越大越好
Example 4 SRQ
在创建qp的时候指定srq就会让他的rq被指定到这个srq中,关于节约内存的好处不再分析(知乎文章有);通过发来信息的rank来确定对侧是谁(因为共用srq就没有单独的连接信息,所以需要指定来获取对侧信息)
Practical considerations
UD or RC?
UD相对于RC的速度优势并没有UDP相对于TCP的明显,其最主要的优势在于一个qp可以向多个qp发送信息;然而UD具有不少的shortcoming
- MTU的限制使得UD需要切分大数据,需要一定编程工作
- Global Routing Header比较大,占空间
- 无序
- 不可靠
因此一般不用
polling imcoming messages when using RDMA write
作为write操作的对侧,监控到哪一片区域被写了还是很重要的,不能老是蹲点守候,因此需要设置write操作的ibv_send_wr.op_code为IBV_WR_RDMA_WRITE_WITH_IMM,这样就可以生成completion并且被应用程序读取了


