计算机系统基础II之:并发编程与锁
Weiquan Huang2-23 con
本节介绍了一些让web服务器能够并发的方法
1,创建进程
这里我们看代码,在父进程accept到请求后,子进程关闭监听fd,父进程关闭连接fd,这样子可以避免内存泄漏
1 | int main(int argc, char **argv) |
流程上就如图,开子进程来处理客户端的请求,父进程继续监听;这边需要注意一下,fd table是一个数组,调用accept之类的返回的是table的index,而实际table装的是(近似理解为指向file struct的指针吧,实际应该还没到这层),所以就算是父进程分配了另一个之前分配过的fd给别的子进程,而此前的子进程被分配了这个fd的仍然没有执行完毕,也不会出现两个子进程指向同一个file struct的情况;注意,不同的进程是可以继承一样的服务器端口的,但是往往子进程的这个端口不起作用,比如在bind阶段的信息并没有在创建进程的时候被复制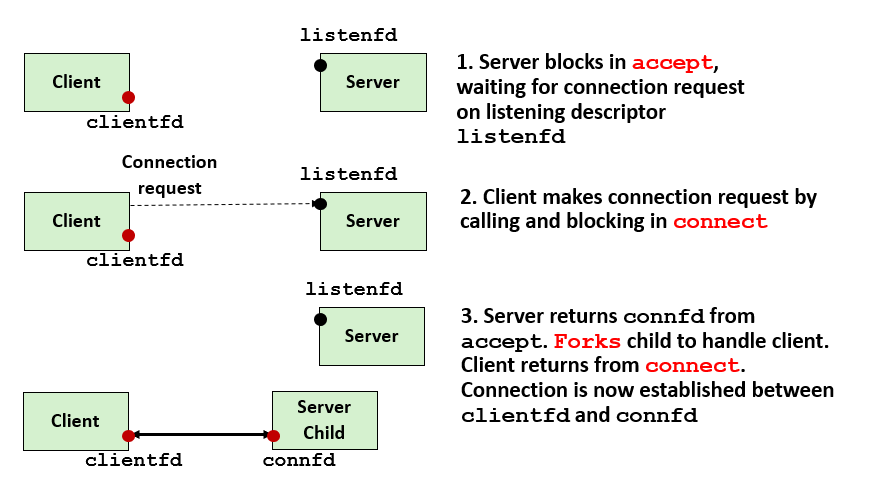
进程的优点与缺点:
- 地址空间独立,进程之间不会不小心复写其他进程的虚拟内存
- 进程之间通信不是很容易,机制有IPC,允许发送小消息到同一个主机的其他进程,比如
waitpidsocket等 - 创建进程比较耗费资源,因为要复制比较多的信息
2,创建线程
线程基础知识:
- 主线程和由其创建出来的线程并没有太强的“父子”关系,更多的是一个peer的关系,不过仍然是有一定特殊地位的
- 线程之间共享的信息比较多,除了data register, conditional code, PC, %rsp, stack是独立的以外,fd table, address space(heap)等都是共享的,所以在编程的时候要小心一点,因为这种程序不好debug(比如用gdb就有概率无法成功);stack不算完全独立,只是每个线程使用的是栈区空间的不同部分,用指针引用是引用得到同一个变量的(相同的虚拟空间,同一个进程共用)
- 线程之间的跳转与进程类似

线程相关接口:
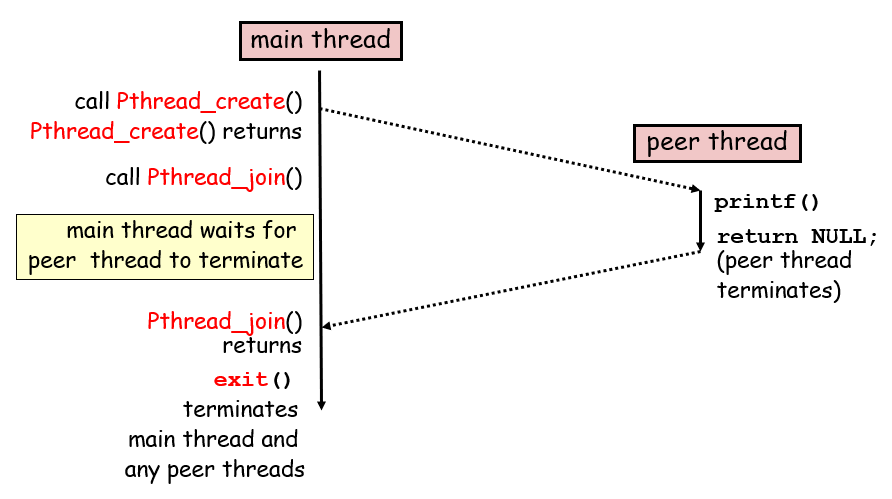
int pthread_create(pthread *tid, pthread_attr_t *attr, func *f, void *arg)线程可以通过调用这个接口来创建其他的线程,f是新线程要调用的函数,void *arg是存放f参数的地址,attr一般是对这个线程进行一些配置,ics课程不用管pthread_t pthread_self(void)线程调用可获取自己的线程idvoid pthread_exit(void *thread_return)peer线程调用会显示终止,main线程调用会等待其他对等线程终止后,终止主线程和整个进程,从thread_return拿到返回值;注意,当传进去的函数直接return,也会隐式调用该函数exit(0)对等进程调用了,那么该进程及其相关线程全部被回收int pthread_cancel(pthread_t tid)可以让某个线程终止同一个进程的对等线程,不过终止并非立即生效,而是等待其执行到了一个cancellation point取消点之后才会取消int pthread_join(pthread_t tid, void **thread_return)阻塞并等待对应进程终止,然后回收其资源,返回值通过第二个参数获取int pthread_detach(pthread_t tid)线程是可结合(joinable)的或者是可分离(detached)的:可结合的线程可被其他对等线程终止,等待其他线程回收他的资源,否则其资源不释放;可分离进程不能被其他进程终止,终止的时候直接由系统释放内存资源
代码分析:给线程传参数让他去调用处理客户端连接的函数,由于共享数据栈,因此需要用malloc来传参数,否则由于传参需要使用指针,如果用局部变量的话,会导致多个进程对这个数据的复写
1 | int main(int argc, char **argv){ |
3,I/O多路复用
int select(int n, fd_set *readset, NULL, NULL, NULL);函数:传入readset里面应该有的bit数量,以及需要监测是否准备好读的bit fdset;会等到有至少一个可读之后返回可读集合和可读数量
下面是一些操作fdset的接口
以下是示例的代码:如果键盘好了就读键盘(stdin),如果连接好了就执行连接的相关操作echo
1 |
|
并发编程实现服务器功能的思路:
- 用一个pool来存储已连接的descriptors
- 如果一个新的连接请求到来,就将其加入到pool里面
- 如果已连接的descritor有数据传过来,就读数据;读到EOF之后就切断连接
1 |
|
2-24 syn
理论上,在同一个进程的多个线程共用一个“虚拟内存”,虽然说用的是不同的栈等,但是只要你拿得到指针,随便一个线程也可以访问这个变量;包括一些定义在thread的函数的static变量,明面上主线程拿不到,但是你拿得到那个变量的地址,你照样是拿得到的
从汇编代码的角度看线程错误的问题:出问题的主要是Li, Ui, Si,因为如果两个线程在某个时间段在这个阶段“共存”,也就是某个线程尚未结束这个流程,另一个线程就进去了,这样就会导致,另一个线程在尚未写入新值的时候就将旧值取出,最后更新的时候就无法累加更新,而是重复更新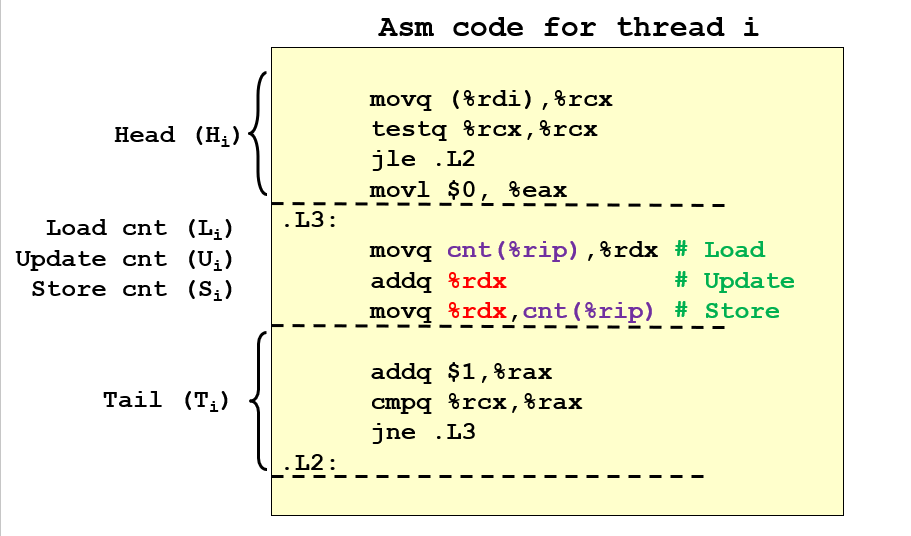
可以用进度图progress graph来标识这个过程,会触发不安全的线程问题的区域被称为临界区critical section;如果多个线程组合产生的轨迹线穿过了这个区域,那么就是不安全轨迹线unsafe trajetory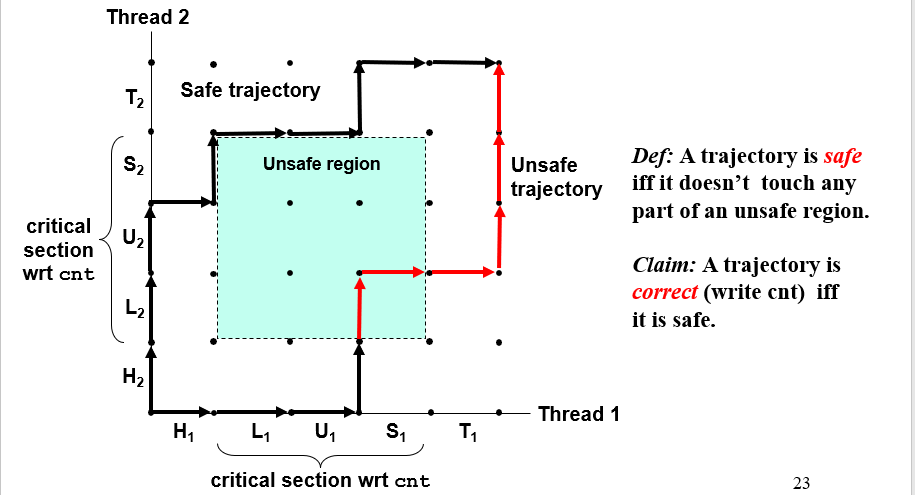
信号量semaphore
信号量是具有非负整数值的全局变量,只能由操作P、V来处理:
其主要的特征是,P V中的操作是原子的,比如P的测试、减1操作:一旦预测到信号量为非0,则将其减1,不能有中断;所以受到P V保护的操作相当于被上锁了,不会被中断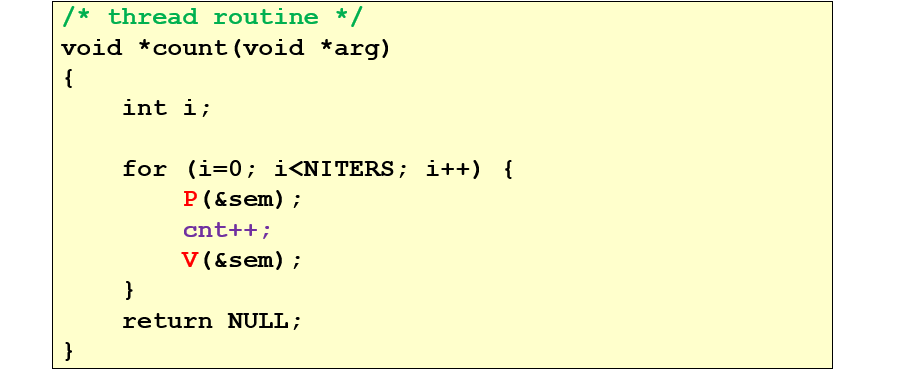
比如这里的cnt++,sem_init(&sem, 0, 1);将初始值设为1,意味着只能有1个线程能同时进入这里,第一个进入的将s设置为0,然后其他的就被堵住了,直到出去的时候将s设置为1,更新后的不安全区域如下: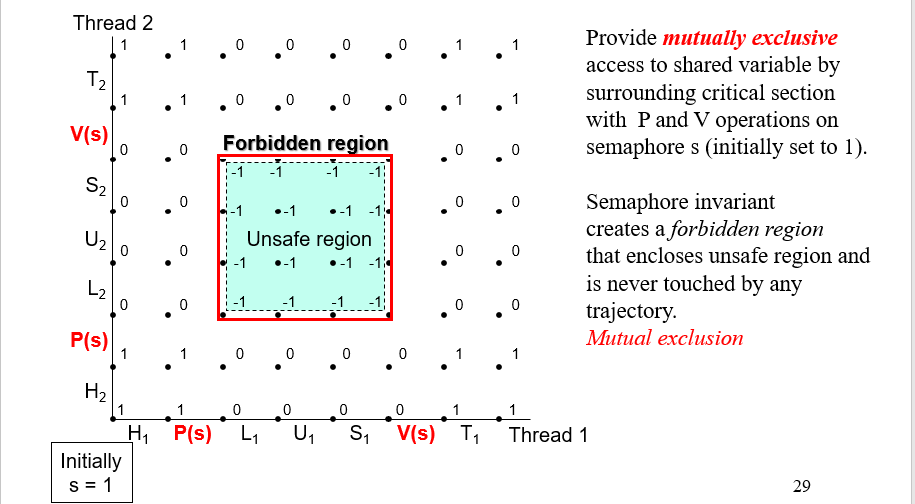
2-25 issue
mutex又被称作bianry semaphores,即只有1个线程能够同时进入被其保护的区域
生产者消费者模型
- 生产者等待buffer为空,然后放置产品在buffer上,然后告知消费者
- 消费者等待buffer出现产品,将其消费,然后告知生产者
buffer容量为1
初始为空,生产者需要生产;生产者将东西生产之后,empty == 0,full == 1 这样生产者会被阻塞,消费者能够消费;反之亦然,所以生成的输出应该是生产和消费符合逻辑的一对一的结果

buffer容量为N
单独存取一个物品的操作仍然是原子的,但是能进去的变多了,结果就会有比较多的变数,不再是buffer只能0/1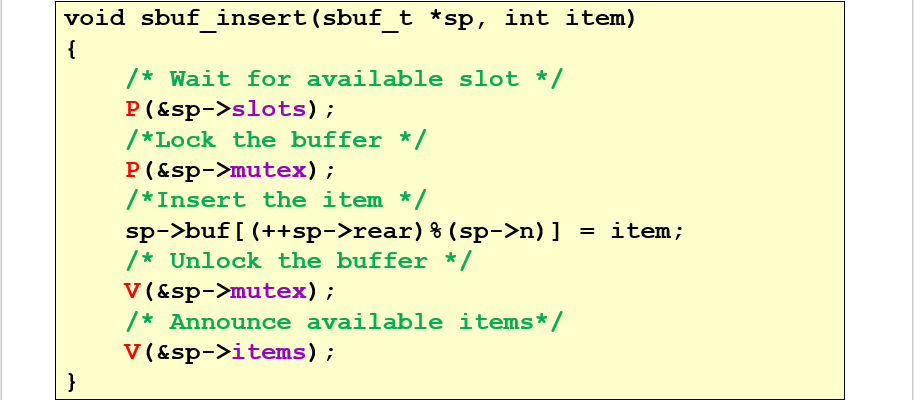
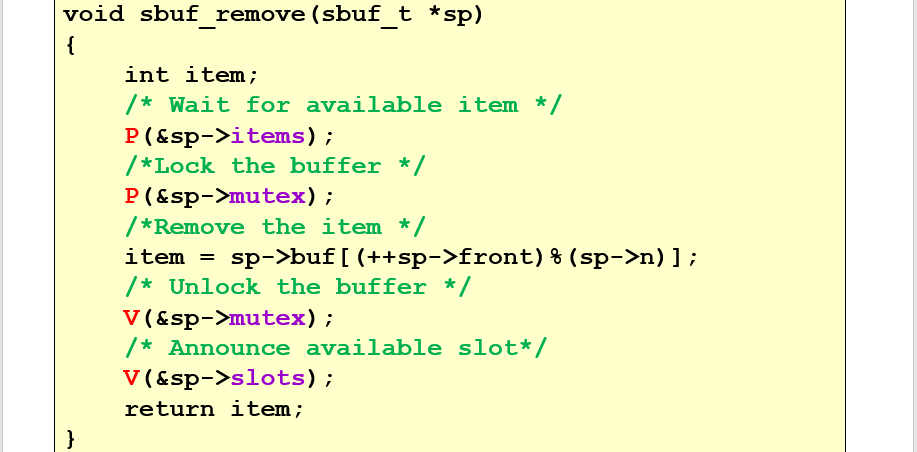
读者写者问题
第一类读者优先:
- writer只能有1个进行write操作
- reader可以有很多个,并发read
- 第一类问题中,reader优先于writer,比如如果当前有reader,就会阻止writer;没有reader,writer才有机会去write

第二类写者优先:
- 同时只能有1个reader/writer可以进入区域进行读写
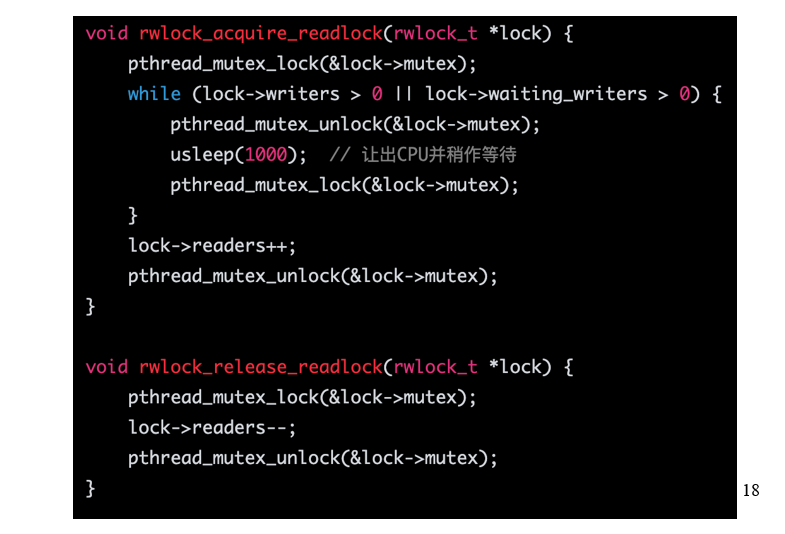
- reader需要等待writer和waiting_writer全部完成之后再进行,如果有writer再进入则需要让出位置给waiting_writer
- 对于读写者,他们能进入的条件不同,一个是waiting_writer+writer,另一个是writer_reader,其余的卡的方式是一样的

多线程服务器
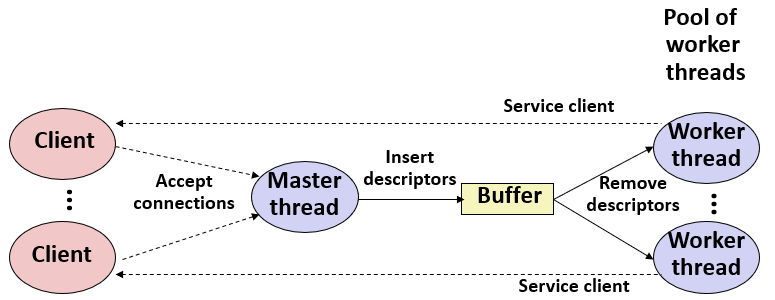
思路是在服务端开一个“线程池”,就是容纳一定数量的线程来接受任务;服务端主线程用来接受客户端的请求,将connection fd放入buffer里面,而线程池中的线程负责不断地从buffer里面获取任务,并执行;注意获取任务需要是线程安全的
在代码中还存在pthread_once这个函数,主要表示在多个线程中,这个函数只需要执行一次的意思,通常用于初始化
多线程与优化效率
带锁的多线程效率往往不如单线程,因为锁这种东西,比较慢,所以尽量不要用锁。一般可以通过将累加的结果放到数个独立的变量中,最后统一加到总和变量内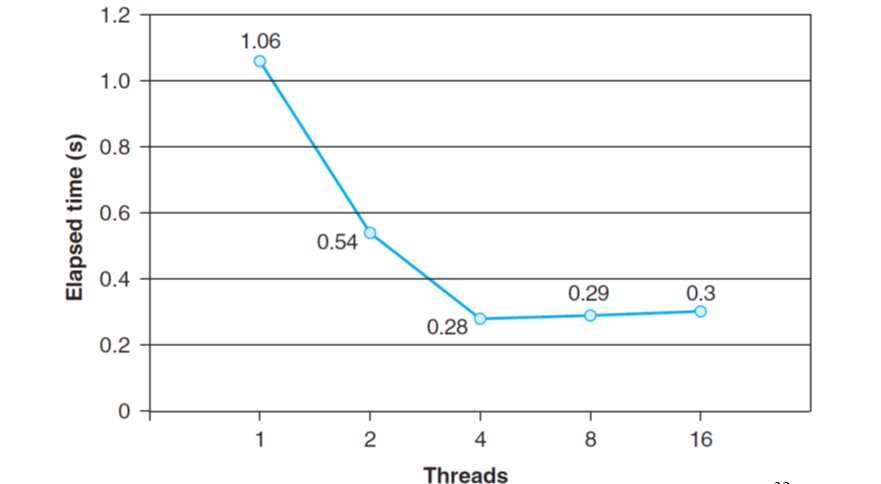
TLS: Thread local storage
比如thread_local int i = 0;,是一个生命周期与线程相同、每个线程各自独立的变量,不同线程之间不共享,可以避免线程冲突,达到线程安全的效果
Races
不同线程的运行顺序不同会更改一些共享变量的值,所以尽量让穿进去的变量是非共享变量,比如这里其实可以直接把i传进去,然后int myid = (int)vargp;,这样还是可以的
2-30 lock
第0种思路是block interrupt,在多CPU的多进程中无效,因为只能设置单个CPU的block vector,而且为了实现单核的多进程而采取block interrupt是很危险的,比如遇到了page fault就没法handle;而且如果在关闭中断的代码区写了无限循环,那么ctrl+C也停不下这个程序,他就独占CPU了。
第1种思路是simple flag,但是会有问题:
主要是在lock处,会出现两个等待中进程同时跳出while循环而进入锁保护区域的情况
第2种思路是Test-and-set锁,通过原子的设置控制锁的变量(通过别的硬件语言实现)来模仿第一种思路

- 如果当前有正在等锁的进程
flag[i]==true,那么继续等,放弃之前的抢占 - 如果没有,那就自己去执行操作,拿到Lock.flag的值,将自己对
flag的抢占设置为0,其他的进程可以设置 - 会导致starvation
解决starvation问题的方案:ticket lock,为每个等待者分配一个挂号,开锁解锁的时候也会递增,到时候会让对应的等待进程去进入锁保护区域
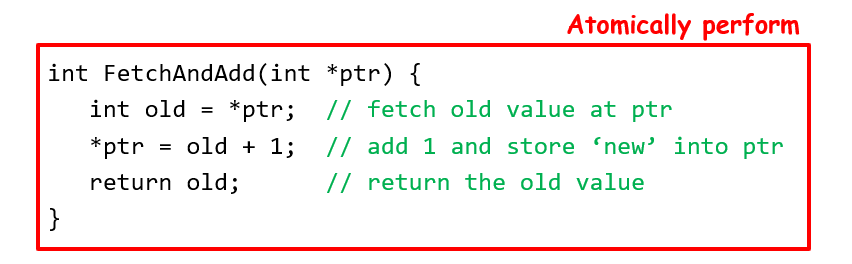
spin lock的问题就是,等锁的时候执行的是while空转,就导致了做没有意义的事情,这里引入一个系统调用yield进行讨论,yield会自行让出CPU资源,期望是不进行while等待转而放弃CPU;但是效率不一定高,因为如果线程数多的话也会造成过多的context switch
改进版:使用等待队列,等待过程中睡眠,由解锁函数进行唤醒;下面的实现,首先进入lockorunlock由guard管理,如果当前没有等待锁的进程,那么直接设置flag=1,退出;否则往队列中加入这个线程,解开guard后睡眠;在unlock的时候会将队头线程唤醒;这里的问题是,如果lock()的lock->guard = 0;被执行,而直接到unlock()函数,那么有可能在park之前unpack,这个lock就没法unlock,其他的lock只能进入lock->flag==1的分支;因此更好的方法是在queue_add后面添加一个setpark(),检测有没有unpack的信息

Linux futex
思路和上面的队列锁有点像




