计算机系统基础II之:内存体系
Weiquan Huang2-11 ram
SRAM在访问速度、传送数据量、信息存储持久度、以及信息抗干扰(主要体现为干扰后能恢复原来的状态)优于DRAM,但是太贵了
内存控制器会将行列信息分布传送到DRAM内,这样子对于addr的引线就只需要两条(0-3就是00-11,如果是一维数组直接输入下标,则需要0-15即0000-1111,引线的条数就是bit数);一个超单元其实涵盖了8个bit;这里就是先传一个row,DRAM将对应行的信息传到行缓冲区,然后传col,DRAM将缓冲区中列的内容传给data引线(共8条)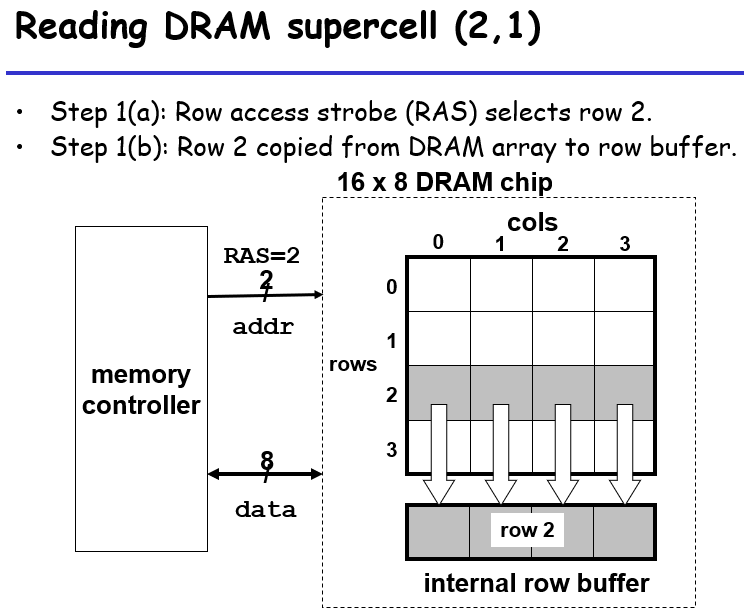
这里一个内存模块(memory module)有8个DRAM芯片,每个超单元存一个字节,一次可以取8字节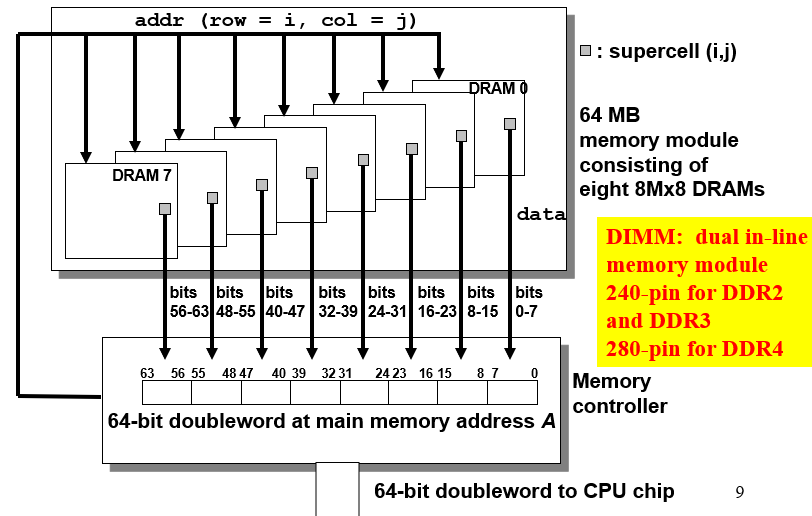
总线(bus) 是携带地址、数据、控制信号的并行管道的集合,通常总线被许多设备共用;读事务从主存传送数据到CPU,写事务从CPU传送数据到主存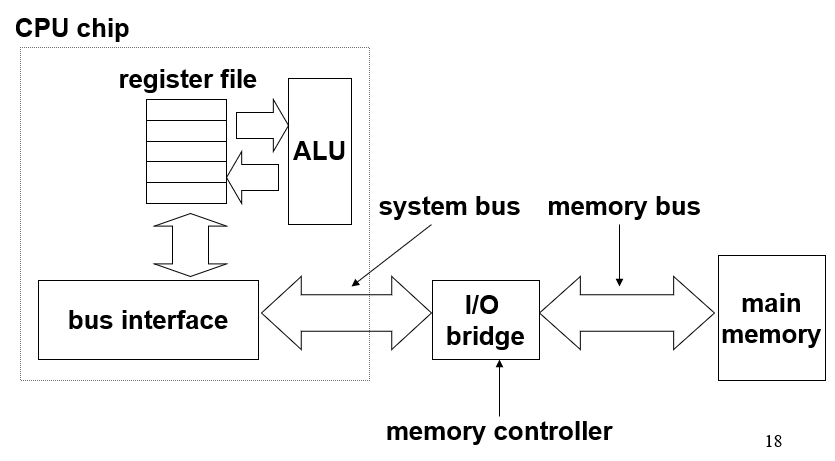
考虑一个movq A, %rax,分为三个步骤:
1,CPU的总线接口将需要的地址传给主存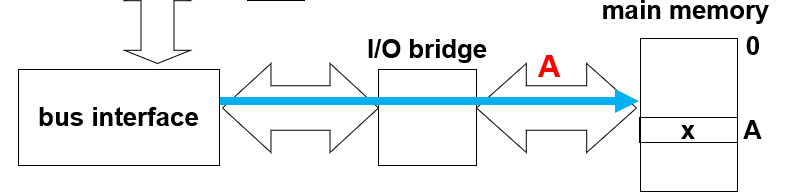
2,主存将对应地址的内容传给总线接口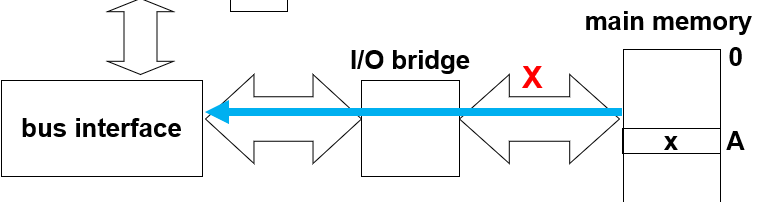
3,总线接口数据传给寄存器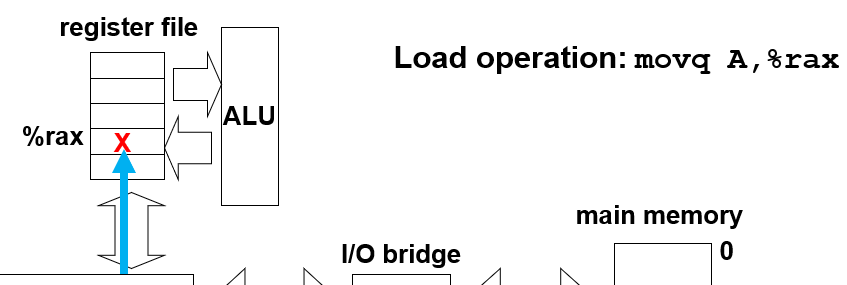
如果是movq %rax, A,则是先总线接口去找主存对应地址,然后将寄存器内容写入总线接口,然后数据从总线接口到主存对应位置
古早圆形磁盘
有多层,一层两个面,一个面有很多个道track,一个道有很多个sector;不同道之间的数据容量并非严格按半径线性变化,而是一个断层型的变化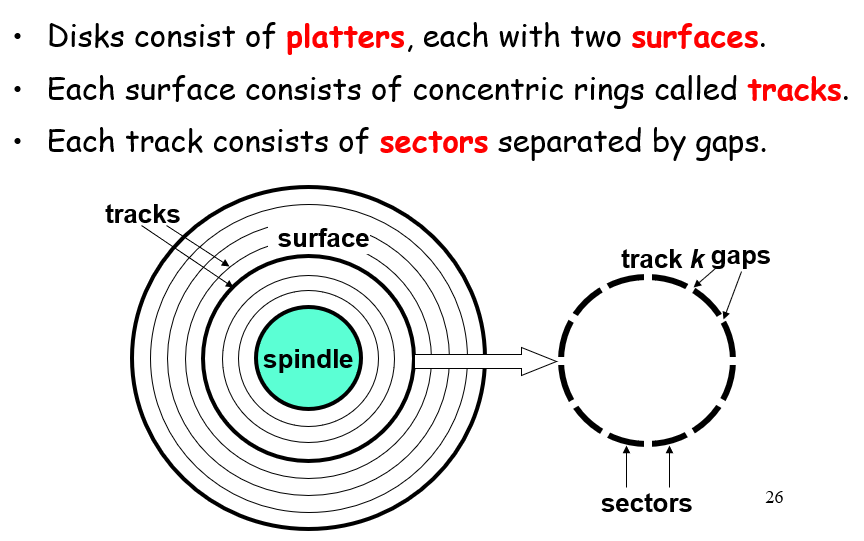
计算大小直接:#sector*#track*#platter*#disk
这种磁盘,为什么随机读取比顺序读取慢很多?因为如果要随机读取,磁盘头是需要旋转到别的track上的,旋转需要时间;需要先到数据所在的track,此时磁盘暂停转动,到了之后再转动
SSD固态硬盘
固态硬板更新一个page的数据,需要将其所在的block全部擦除,这是其性质导致的;因此,顺序存储可以在一个空白处写好顺序的数据,然后统一写入,这样每次擦除更新的数据量就比较多;随机存储就有可能在偶尔几次更新就需要进行block的擦除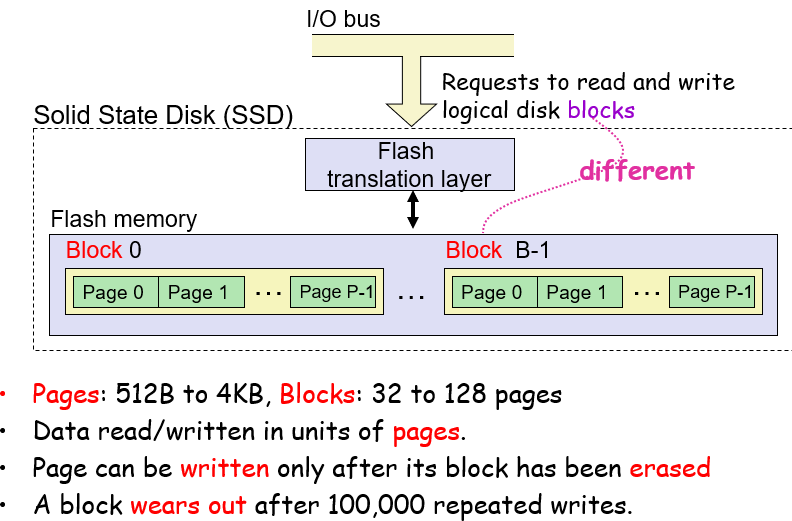
CPU如何从磁盘读信息?
- CPU给磁盘发送一个请求,让他把数据给内存,请求发送完毕后CPU自己继续接下来的任务而不需要等待数据传送(类似于JS的异步函数)
- 磁盘将数据读给内存
- 读到内存里面后,磁盘会发送一个信号,中断当前进程,转而处理数据获取,实现从内存中获取数据,保证了进度
2-12 locality
局部性
时间局部性:同一空间短时多次被引用;空间局部性:相邻空间短时被频繁引用;对于遍历数组,时间局部性低,因为同一个位置不会被多次引用;但是空间局部性高,因为每次步长为1
存储器层级结构
在大部分情况下,存储器层级结构是一个金字塔型的结构,数据多而访问时间慢的在底层,上一层是下一层的数据子集(在空间不紧张的时候是子集,如果空间紧张可能缓存从底层取出数据后,数据会被删掉,避免重复);上一层是下一层的子集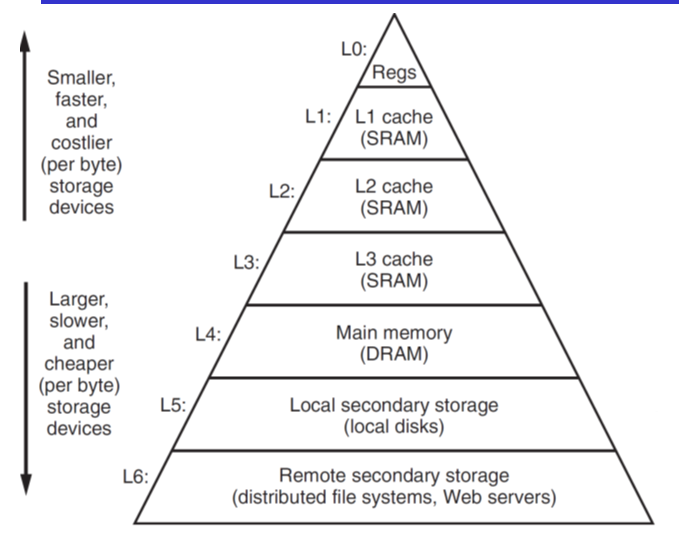
对于第k+1层的数据,传到k层的时候,他们之间的数据传送大小是一样的,数据传送后会放在对应的地址;其存储数据是线性的,关于分块,其实可以理解为其有多个地址位置,每个地址位置都对应一个块;相邻层之间的数据块大小一致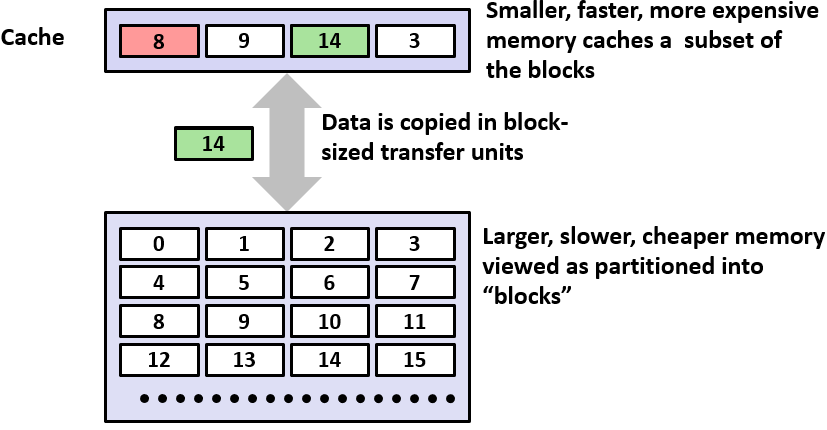
数据从上到下进行请求,如果缓存内有想要的数据,则缓存命中;反之为不命中,不命中有3种情况,冷不命中(缓存为空)、冲突不命中(基于缓存替代策略与数据存取顺序的冲突,导致每次都无法从缓存中得到想要的值:比如第一次取9,但缓存中为13,此时把13->9;第二次取13,但此时没有13,则9->13…依次往返)、容量不命中(由于总的数据存取范围大于缓存范围,必有不命中的情况)
高速缓存存储器
往CPU和主存之间插入缓存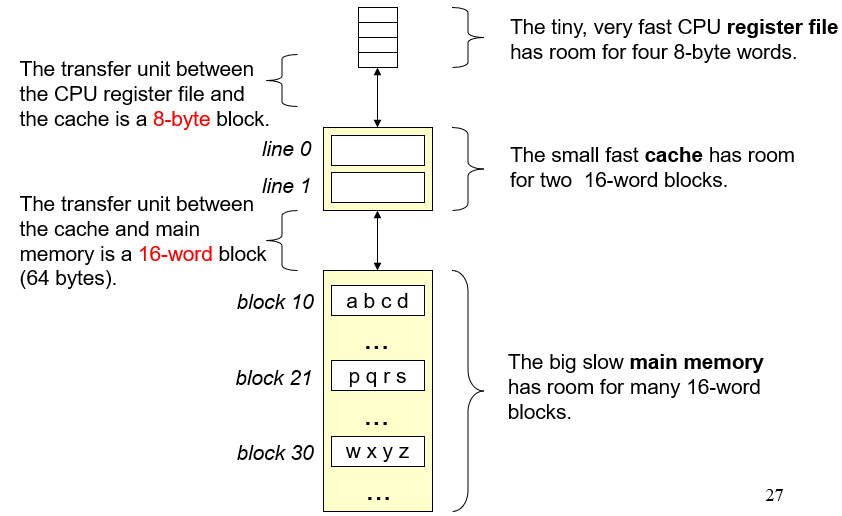
缓存结构总览
一个缓存有S个set,一个set有多个line,一个line内有一个valid位表示该数据是否有用、t个tag位标识数据、b个bit位用于存放数据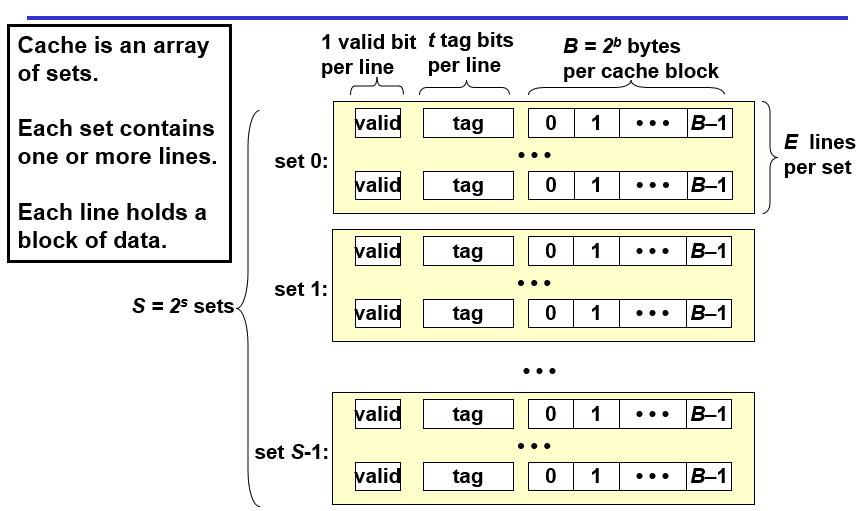
如何通过缓存获取到对应地址的内存数据?
首先,一个地址数据会被分割成3个部分,$s=log_2S$表示的是数据可能会存在缓存中的第$s$组;从这些位获取到对应的组别后,通过tag位的一一对应关系来确定这个set里面包含的数据是否有这个地址所需要的数据;如果有则表示命中hit,会继续根据地址中的block offset偏移量来获取到对应line的cache block的某个位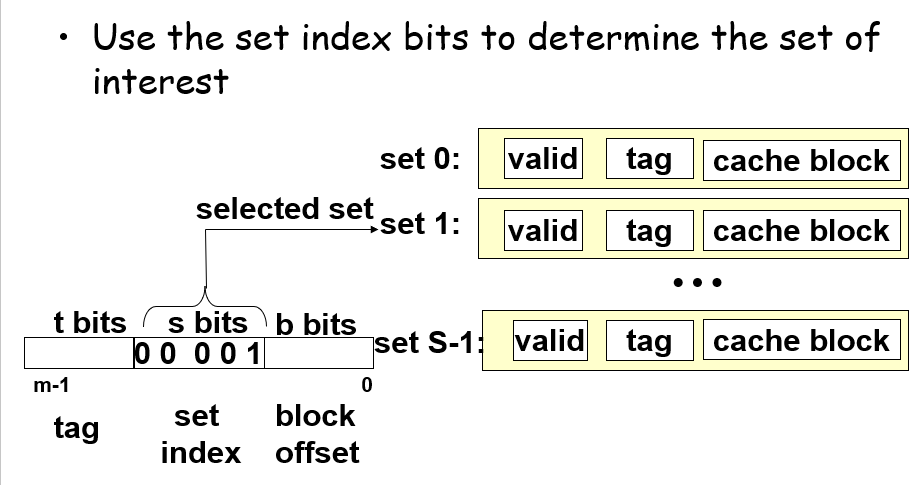
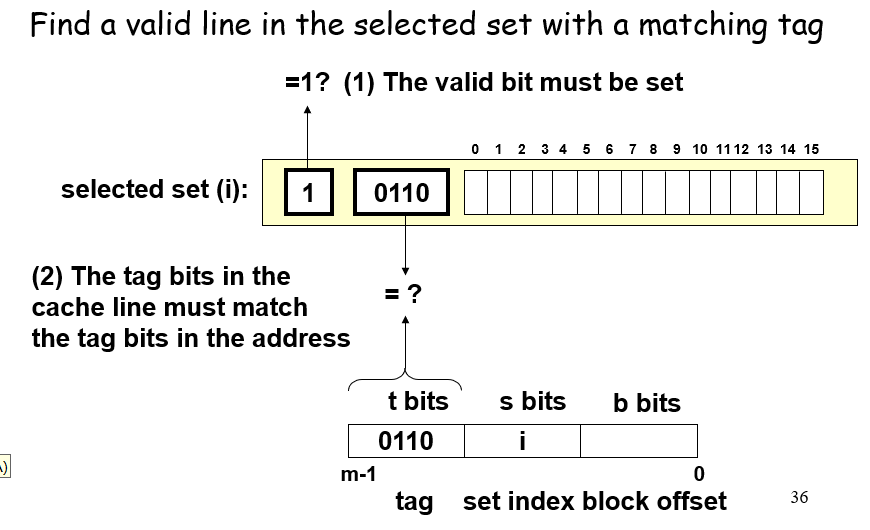
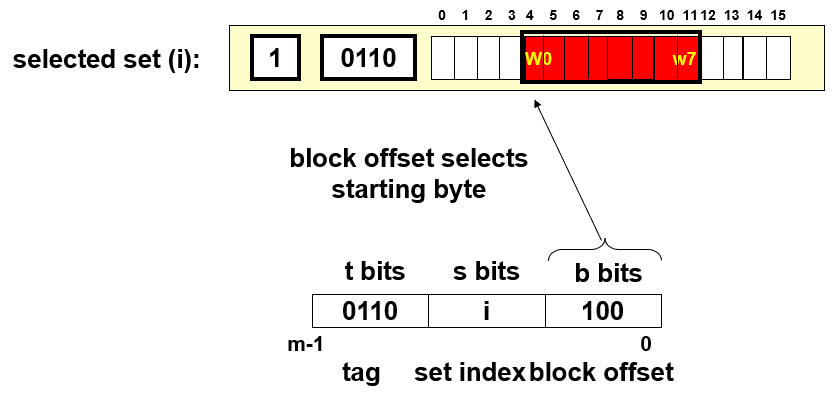
下面是一个例子: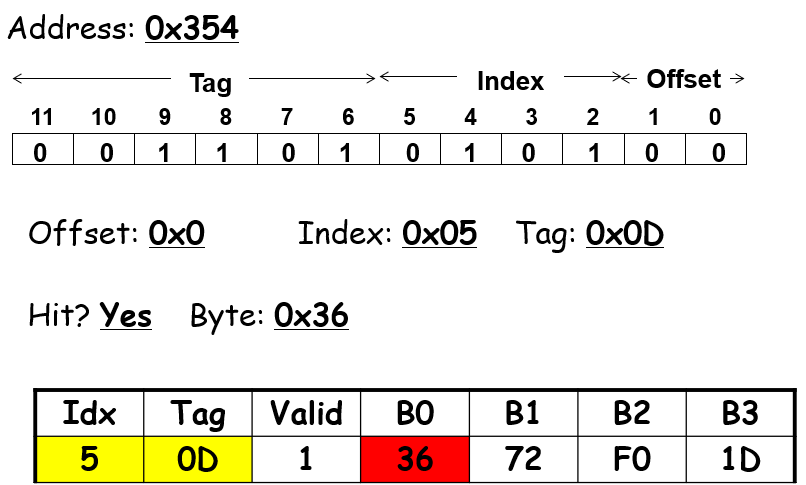
命中了当然一切好说,如果没有命中呢?
没有命中会将对应set的line给换掉,换成从内存中获取的本次所需要的值,给他加上valid tag位
$E=1$的被称为直接映射高速缓存,比较容易出现冲突不命中,主要是因为set相同但是tag不同
- 第0个为冷不命中
- 第1个算是命中了,偏移量为1
- 第2个为冷不命中
- 第3个冲突不命中
- 第4个冲突不命中(重复出现)


课本上的例子:
他这个的意思是说,如果一个块的大小为16字节,那么读x[0]会读到x[0]~x[3],但是紧接而来读y[0]又会因为冲突而复写set0对应的缓存数据,然后读x[1]的时候又冲突不命中了,依次循环往复,高速缓存形同虚设;一种解决办法是,给x开空间的时候开到x[12],但是这种方法比较反直觉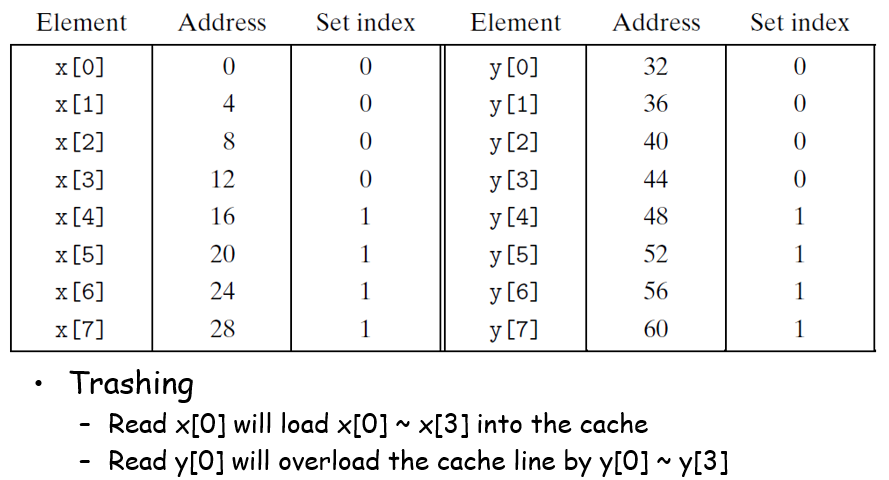
为什么用中间的位来作为set位?而不是用高位?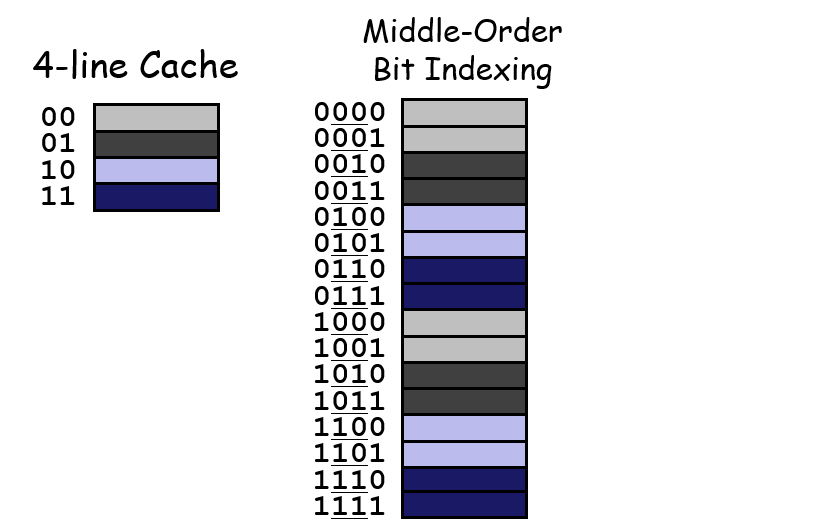
主要是为了让cache能够被充分利用,如果是设置为高位的话,数据量较小则无法充分利用每个cache
这种只有1个set的有效地避免了冲突不命中,对缓存空间利用率高;但是硬件实现较为困难,以及容量满了之后决定数据复写的位置需要一定设计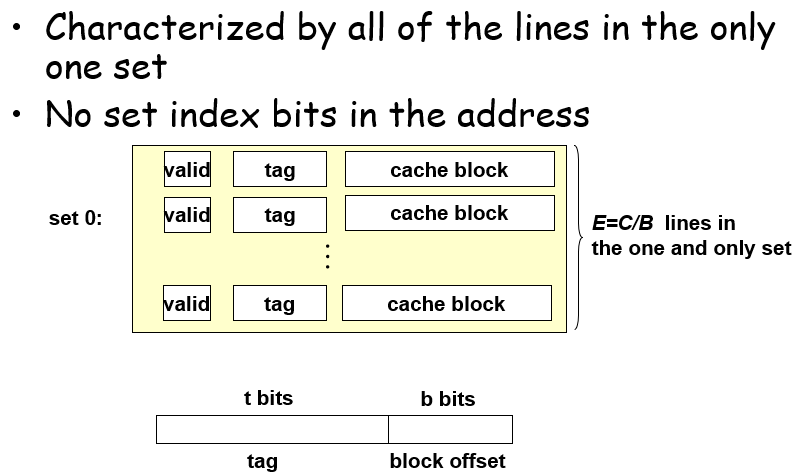
2-13 mics
针对写操作,缓存也有一些特性:
写穿:直接写入内存;写回:写到缓存中,等缓存被顶替的时候再讲起写到内存,避免了频繁的对内存的操作
不命中的处理方法:可以取出数据后再在缓存中改写数据;或者直接在内存中改写数据。命中和不命中的两种方式各自一一对应
寄存器与内存之间的架构:一共有3层缓存;数据和指令分开缓存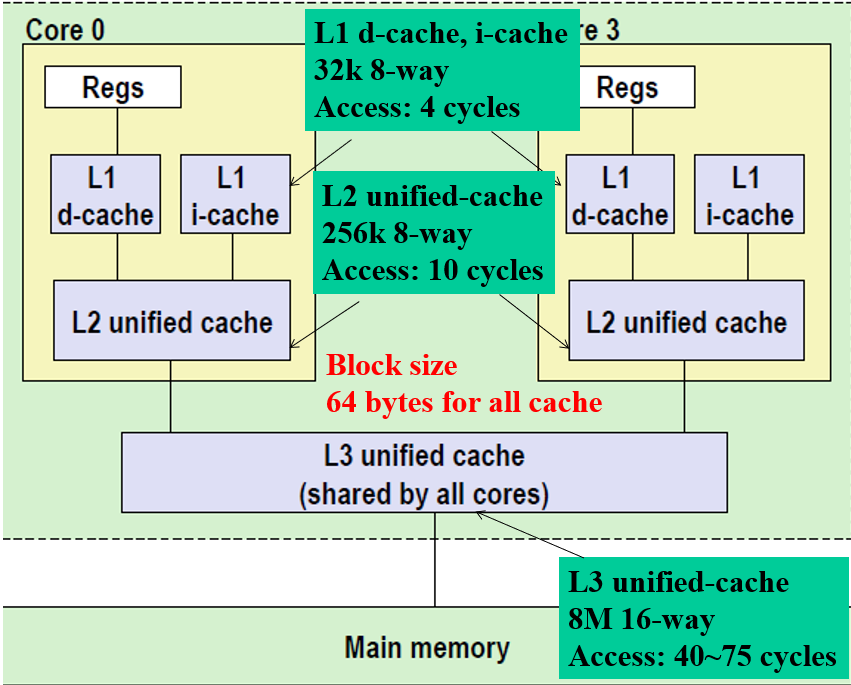
使用不命中率作为评估缓存性能的指标,原因在于不命中率对于数据存取的性能影响占比极大:
缓存性能较好的代码?
以矩阵乘法为例,b[k][j]的冲突不命中在n较大的时候非常明显,由于缓存中一个块顶多就64byte,对n>8就意味着每次都会冲突不命中,非常难绷
具体来看冲突不命中的概率问题:数组A每四次发生一次不命中,数组B每次都不命中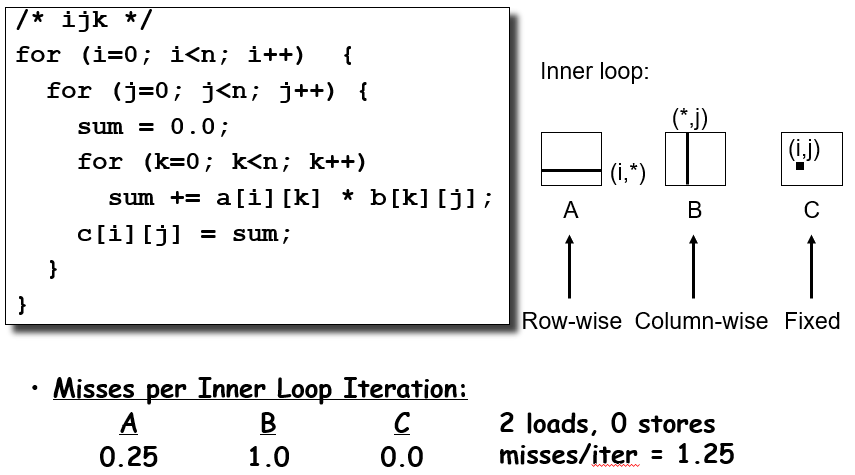
有一些牛人发明了十分巧妙的对cache友好的算法!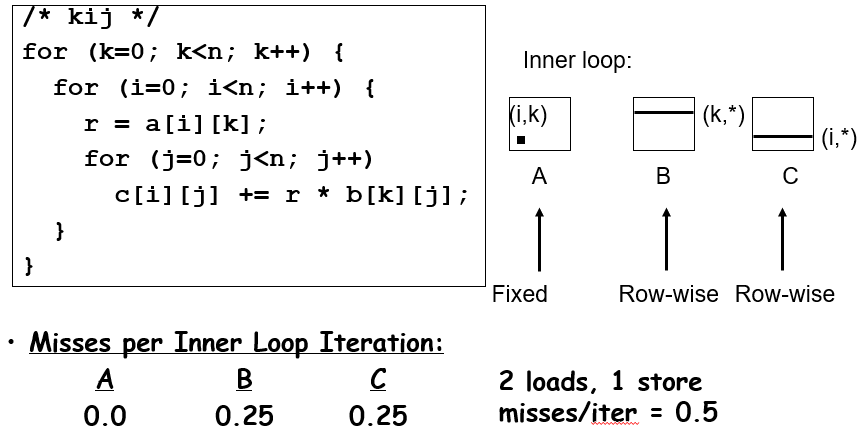
CSAPP封面——内存山
这里执行的是一个数组在规定步长下的遍历操作,测试前有提前执行过一次该函数作为预热,防止冷不命中干扰实验数据
- 步长越短,发生冲突不命中的概率就越小,运行速度就越快;当步长大到每访问一次数据就会一次不命中的时候,其运行效率就差异不大了
- 每次取的数据块越大(你也可以理解为数组长度),那么运行速度的下限就越低:比如长度为32K,那么所有数据就都会在L1层被命中,存取L1层就会比较快;超过32K,那么L1层目前存的都是数组较为末尾的数据,而L2层内数据则都可以命中,那么其访问数据的下限就取决于L2,因为L1是会冲突不命中的;超过256K的同理
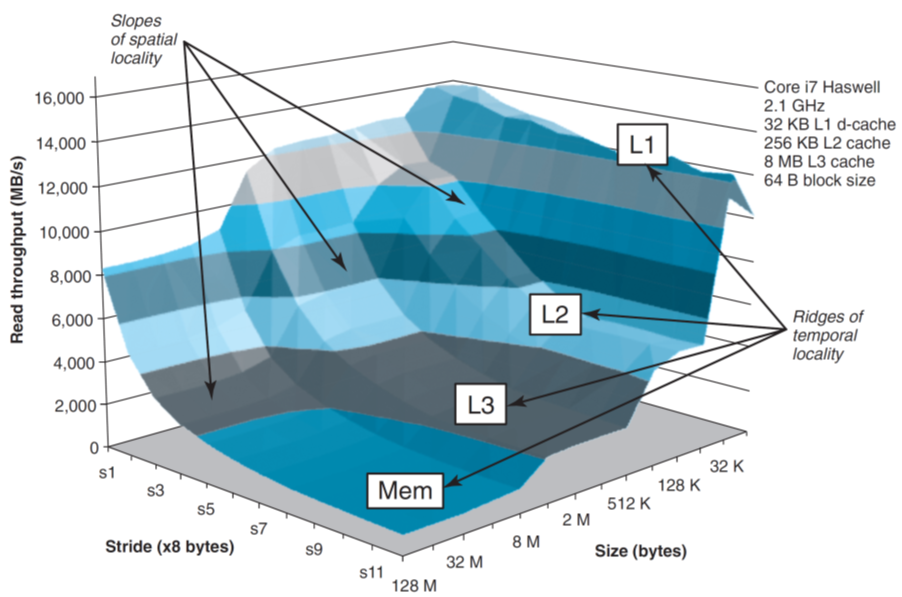
补充
各类存储结构的特点:
- SRAM:可以无限期地保持在两个不同的电压状态之一,只要有点,他就会永远保持它的值,当干扰消除的时候,电路会恢复到稳定值;用于缓存cache
- DRAM:被干扰后永远不会恢复;比较便宜,所以用量比较高(“典型地,一个桌面系统的SRAM不会超过几兆字节,但是DRAM确有几百或者几千兆的字节”);用于内存
- SSD:远快于磁盘,慢于内存;抖动不丢失数据,可用于移动手机
- Hard Disk:容量大,速度极慢
- 目前SRAM在优化性能,DRAM在优化容量,价格都在优化


