计算机系统基础II之:代码性能优化
Weiquan Huang2-8 mio
对于一个程序来说,访问内存、调用函数都是不小的开销;编译器有提高代码执行效率的编译方法,同时也有一些地方在明面上能够做优化但是编译器出于自己的考虑并没有选择做优化
优化的情况:
- 一些简单的
get()函数直接转化成从寄存器中取值,相当于汇编代码中去掉了调用函数的步骤
编译器没法优化的情况:
- 一直调用一个返回值的函数,尽管很多时候其返回值固定,但是出于对这个值改变了的担忧,他还是会选择跑去函数里面取值(比如你在遍历一个数组的时候一直调用
.length()方法 - 传入的函数参数是指针,不清楚这些指针会不会指向同一处(这个是真的有歧义!);以及函数内部有对全局变量的更改,调用单次和多次的效果不一样

课本的例子中提到了关于函数调用和访问内存两种情况的性能损耗,不过如果函数调用中本身就含有访问内存的操作,那么这里主要的时间损耗其实还是内存访问

2-9 opt(modern processors)
现代处理器的结构: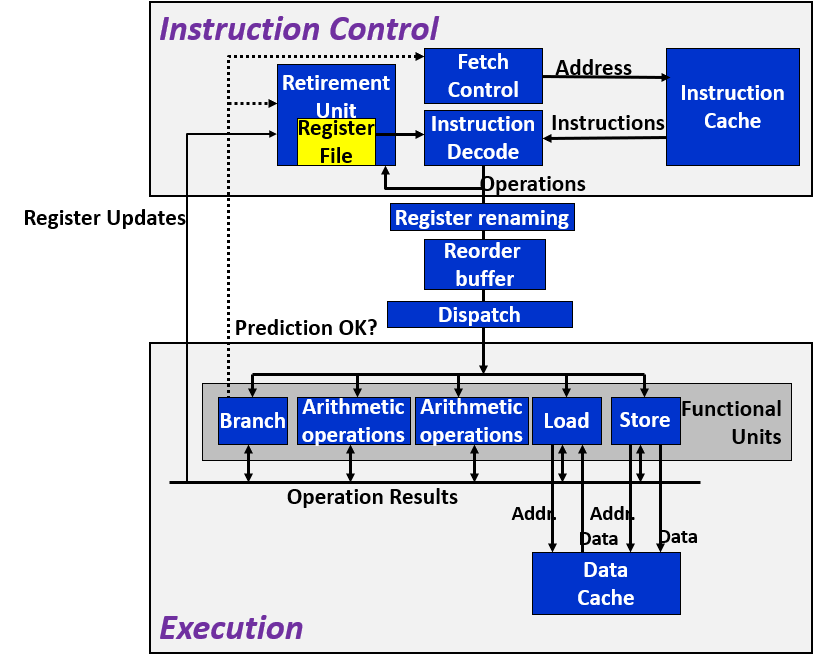
- cache 缓存:instruction cache存放有最近需要用到的指令,方便于ICU去获取需要执行的操作;data cache存放有最近需要用到的内存数据,方便load/store数据
- fetch control 取指控制:将要执行的指令地址输给指令高速缓存(instruction cache),由指令高速缓存取出指令给指令译码(instruction decode);取指控制受到条件分支预测的控制,会决定是否取消先前的预测
- instruction decode 指令译码:会将单条指令视情况分解成单条或者多条基本操作
- operation results 运算结果:由于指令退役后才会更新寄存器,所以为了确保多条指令执行的效率,操作结果可以在功能单元上互相传递
- load store 加载、存储:读写内存,内有计算内存的加法器
- branch 分支:确定分支预测是否正确,会将结果传给fetch control & retirement unit,进行取指的判断以及退役指令是否有效的判断
- retirement unit 退役单元:管理寄存器文件的更新,如果该指令遇到的分支都是正确的,而且其已经成功执行完毕,就会根据其结果修改寄存器的值;否则清空结果,不会对寄存器文件造成影响
寄存器重命名:
如果一个寄存器的值在一个指令序列中多次更改,则需要将其进行一系列的修改,而且为了区分老版本和新版本,需要对其进行重命名,具体来说不同阶段的寄存器如果被修改了值,就需要从%rax.0转变成%rax.1
功能单元的性能: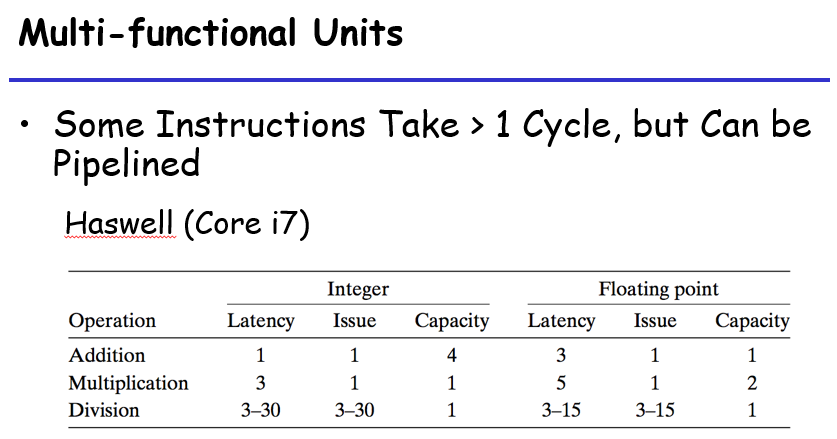
- Latency 延迟:完成运算需要的总时间
- Issue 发射时间:两个连续的同类型运算之间所需要的最小等候时间
- Capacity 容量:能够执行这个单元运算的数量
发射时间为1的功能单元被称为完全流水线化的,相当于一个时钟周期过后下一条指令又可以进入运行了;在这里发现除法器就需要等除法执行完成之后才可以执行下一条指令;另一个定义为最大吞吐量,是发射时间的倒数,处理器的吞吐量一般是capacity/issue
图解处理器操作的抽象模型
从数据传送的角度看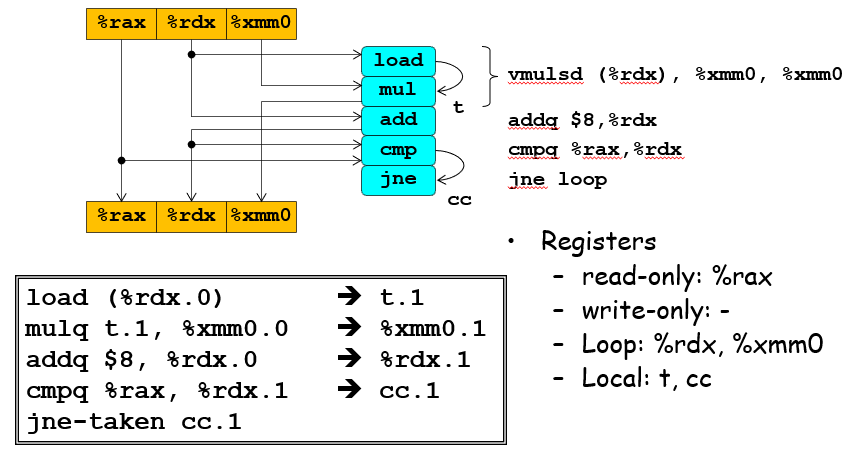
从指令之间传送数据的角度看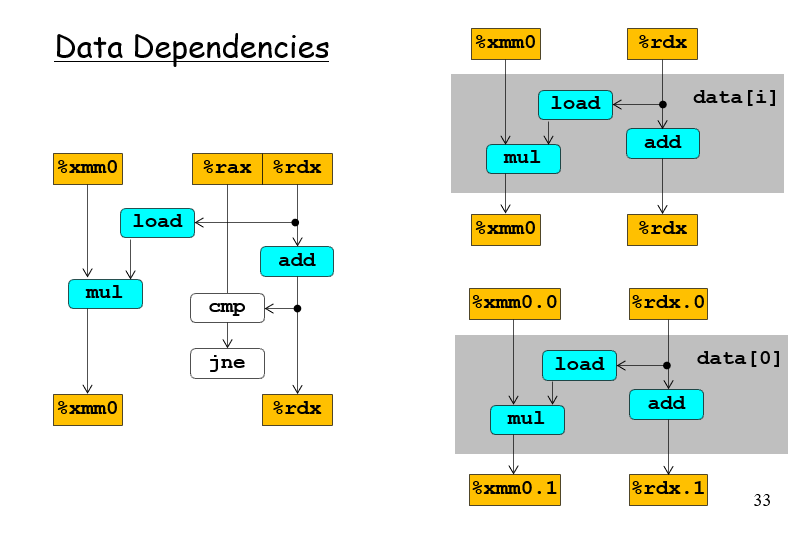
由于乘法的处理周期数很长,所以在上面的这个图中,实际上是mul这个计算指令作为关键路径,也就是说这个流程所需要花费的时间是需要根据这条时间周期最多的路径决定的;乃至于非关键路径可以运行超前于关键路径很多步
相同的语义,不同的执行流程
假如我们用两个临时变量来存储循环过程中的中间计算值,那么在底层运行中相当于用两个寄存器来存储中间计算值,在运行的流程中,相当于每两个项的相加可以并行运行,互不作为依赖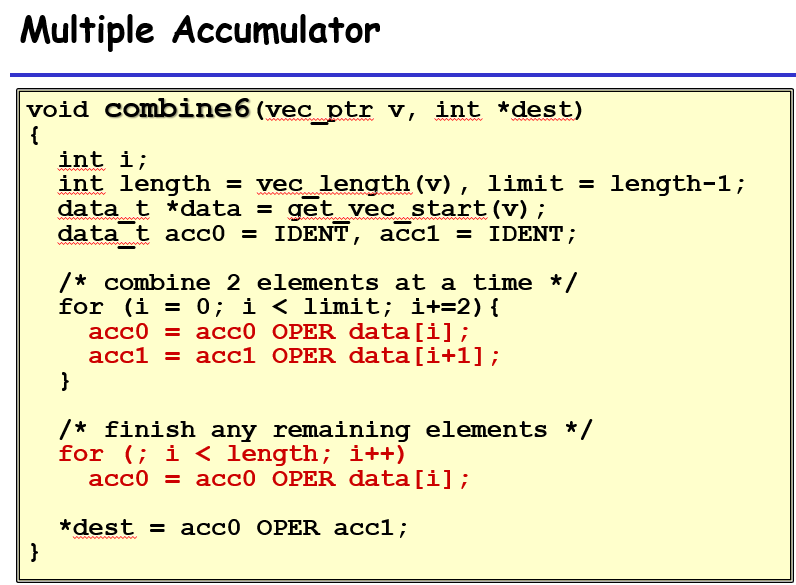
你看,这里就有两条线,因为奇偶数的两个流程互不干扰;相当于原来10个元素需要运行10个满的mul流程,现在10个元素只需要5个满的mul流程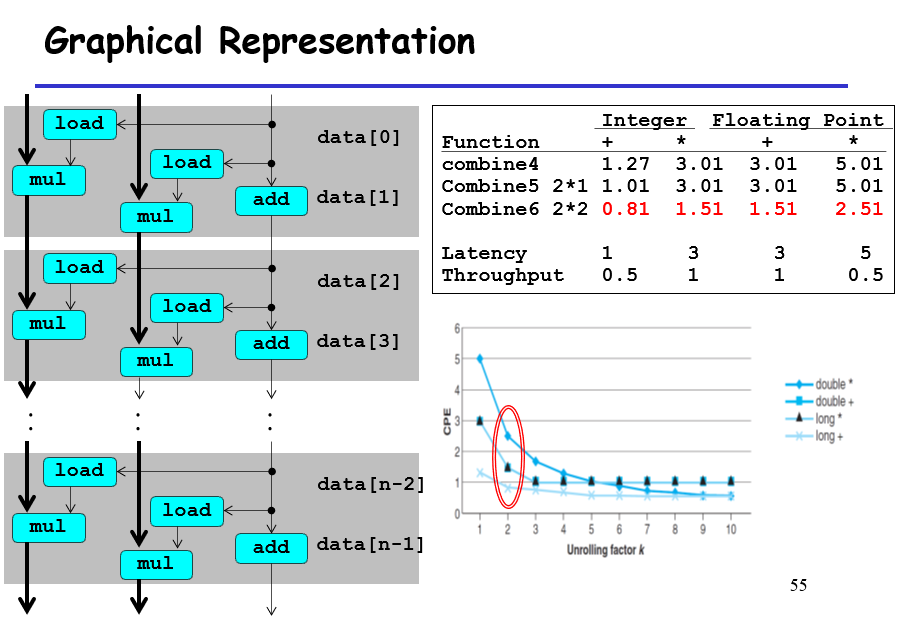
如果我们把临时变量的值设置为10个,那么在这个过程中,有2个mul单元,每个mul单元在一个时钟周期过后就可以接受新的输入,进行新的一次计算,不需要等待完全的mul内每个步骤实现完之后才再进行其他值的计算;计算得到的值依次写入到不同的寄存器中。这样子虽然不是一次将10个值计算出来,但是其实他们的计算间隔十分紧密。不过如果临时变量数大于寄存器的数量,那么多出来的临时变量会写入到内存中,内存读写会拉低效率
这种也是类似,load完全可以一步到位,关键路径就是mul需要等前一个mul的输出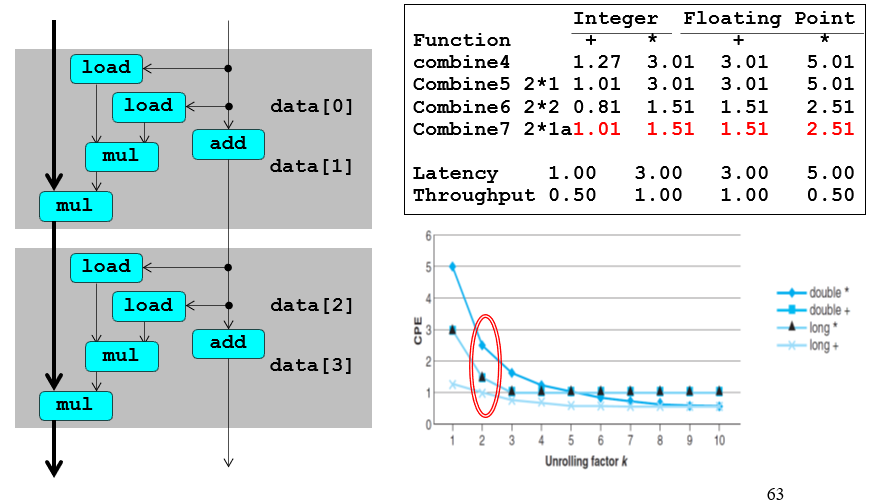
预测错误在现代处理器中会导致19个时钟周期的浪费,这对于我们编写具有高效率的代码也具有参考意义;如下,假设数据随机,则不使用分支跳转的代码运行时间更快(此处三目运算符使用的是cmov,相当于一个数电多路选择器,没有涉及分支预测,更没有失败惩罚);如果原数组相对比较有序,则使用分支预测则相当于减了一部分操作,提高效率
2-10 tuning
加载存储单元,用于暂时性地存储一些从寄存器要写到内存的值(store),以及暂时性地将一些内容存放以方便寄存器“从内存中获取值”。这样子是方便于在一些操作中降低存取内存造成的性能损耗。
同时,对于这个store unit,他还有一个很不错的点是,他可以存储乱序的某个寄存器的所有过程中的值,然后再依照先进先出的原则,将这些计算好的值写入内存中;在这个过程,可以保证计算值的过程是可以并行的,结果的写入是顺序执行的!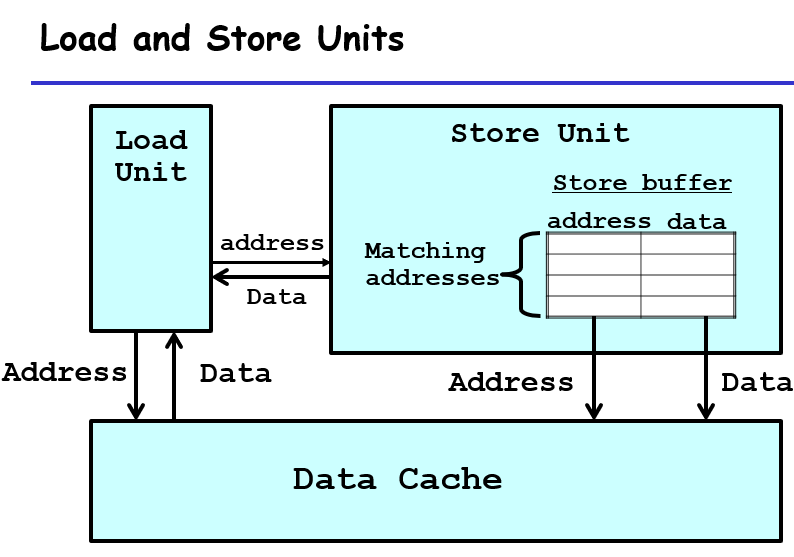
如果3这一条没被去掉,那么%rax是有前后依赖关系的,那么关键路径就是左边那一条;不过由于有load and store units,意味着s_data不需要写入load内,而是写到store unit里面,这样子对于%rax就没有依赖关系,这个过程中所有的%rax版本都会一次写完,赋予一个版本号,写入到先进先出的store unit,所以这里面实际上的关键路径是%rdx,%rax可以同步写完;也就是最后结果所看到的bound1、7的差距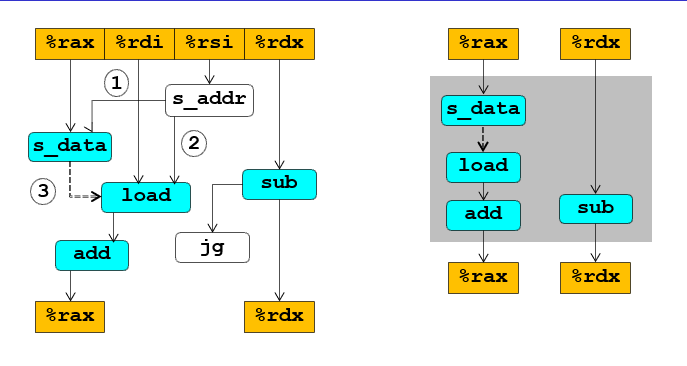
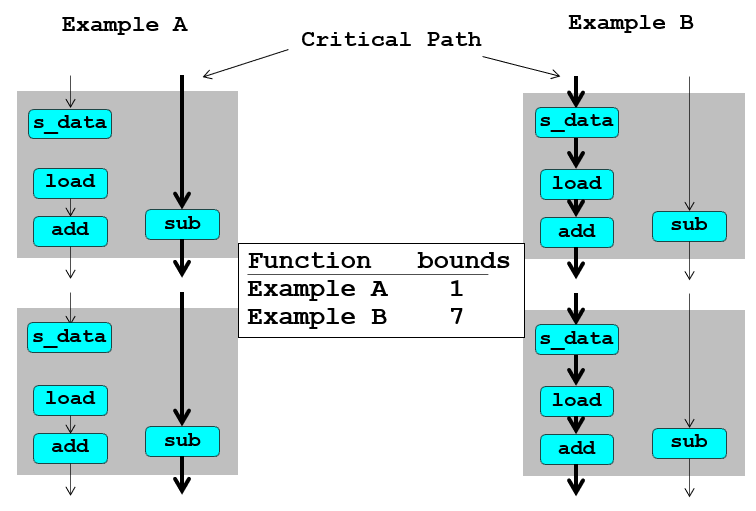
这两个比较的根源代码是这一段,写入相同内存就肯定有依赖关系,不写入就没有:
优化性能的策略
看起来好像很高端,实际上他想说的是,找到当前程序中耗时最大一部分(在目前的策略为函数),然后对齐进行优化;若当前最大时长函数运行时间占总运行时间之比为$\alpha$,那么先对其进行优化,优化了$k$倍就会让性能优化到原来的$1/((1-\alpha)+\alpha/k)$,对吧?所以优先对占比最大的部分进行优化,才能提高优化的上限
使用工具GPROF
通过随机采样的方式来测量每个部分的运行时间占比
然后优化这个函数sort_words
- 用自己的排序可能不如用C内置的排序
qsort - 存储用的数据结构也会导致性能不好
- 比如这里模拟的是从莎士比亚的文本中取词再查找,那么如果用头结点插入链表,则会出现“冷门词汇后进入、在表头”的情况,那么在查找的时候反而大部分词汇被放在较为后面的地方
- 尾结点插入链表也好不到哪里去
- 巨型数组,可以覆盖所有哈希值,但是如果哈希函数取得不好,不仅浪费空间(函数的结果有一定范围,部分空间浪费),而且效率也一般般(未解决冲突问题)


