计算机系统基础II之:Y86处理器
Weiquan Huang2-1 risc
- 程序员可见状态是指Y86-64的指令可以查看或者修改的部分
- 寄存器比X86-64少了一个%r15,因为需要有一个无寄存器的编码$F$
- PC程序计数器
- 条件码只有SF ZF OF(Negative Zero Overflow)
- 状态码
- 内存(小端法)
- 12种指令(V-value D-address)

每种指令比特数长度固定,由第一个byte确定其长度、指令类型以及功能,其中前4个bit确定类型,后4个bit确定功能
运算指令包括addp subp andp xorp等等,为上面表格中的OPq所涵盖
举例:addq %rax, %rsi为60 06,60表示addq,06 代表 %rax,%rsi
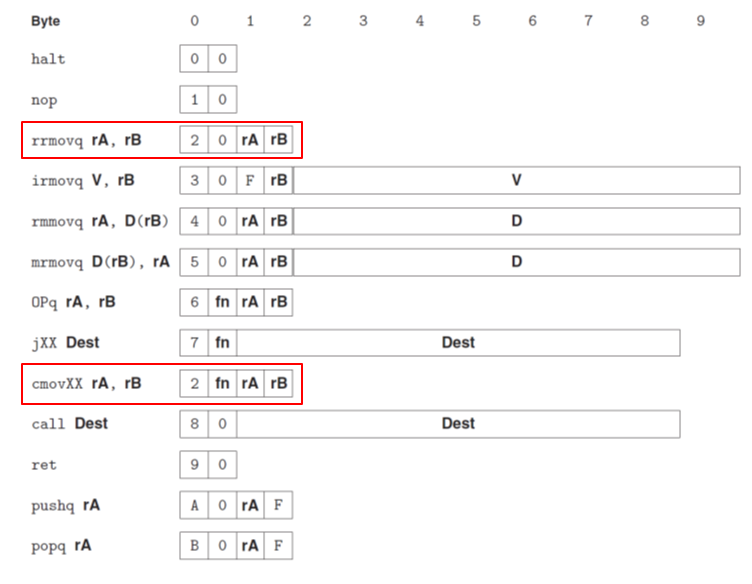

OPq的分支,注意只允许double register

movq的各个情况
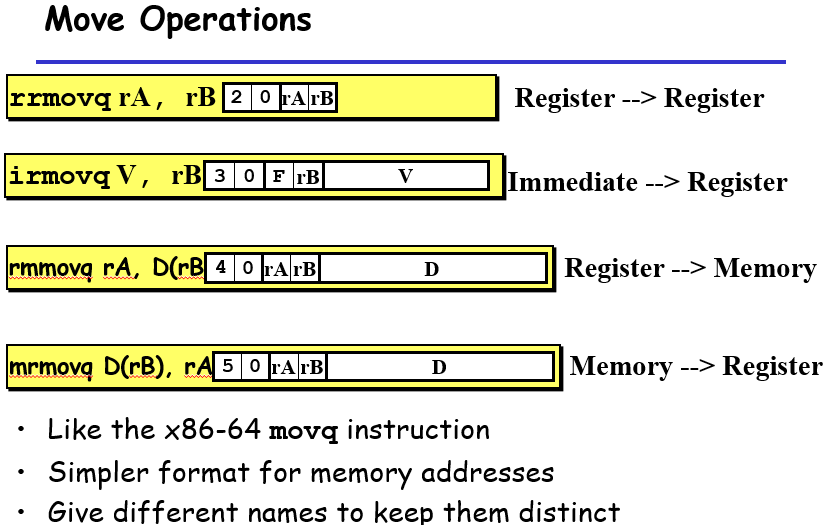
举例
条件move(double register)

跳转指令也是由第一个byte的后4bit确定跳转条件
Y86-64的栈跟X86差不多,往低地址增加,栈顶 %rsp 指向栈中的最低地址;然后是关于栈的操作:注意如果是pushq %rsp,先保存原来的rsp再改变rsp;popq %rsp是将栈顶的值保存到rsp内
call和ret,包括了很多的操作,比如更改rsp、将地址压栈、更改PC等等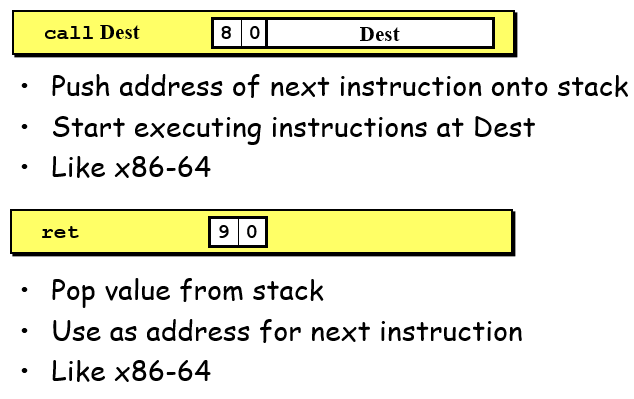
真实程序中的Y86汇编语言

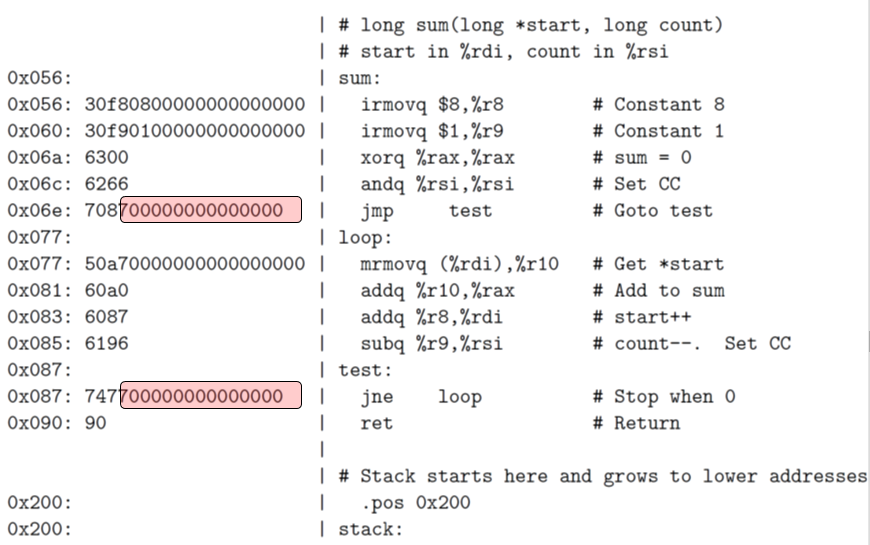
解析:
.pos 0表示声明此处内存位置为0x0,0x0是程序开始执行的位置,也就是说PC刚开始设置的值就是0x0.align 8表示8对齐,也就是说这里的地址如果不是8对齐的话会强制填充空位,直到遇到8对齐地址,比如这里的0x18array:这个是声明array的位置,作为一个用来代替具体数值的标签,比如这里的irmovq array,%rdi就是用这个标签来代替0x18,而左边实际的机器语言写得就是0x18stack是程序栈,此处将程序栈的栈头地址初始化为0x200,他可以向低地址进栈,这意味着栈如果太小容易与原来的程序指令冲突,如果太大会造成空间浪费- 这里的指令和二进制码的对照规则就是Y86的规则
模拟(simulate)Y86-64意味着将诸如内存之类的东西用C语言的对象来表示,然后写C程序来模拟CPU如何执行指令,进行数据的运输和修改的
理解软件与硬件联系之间的中介——ISA(汇编语言抽象、机器语言抽象)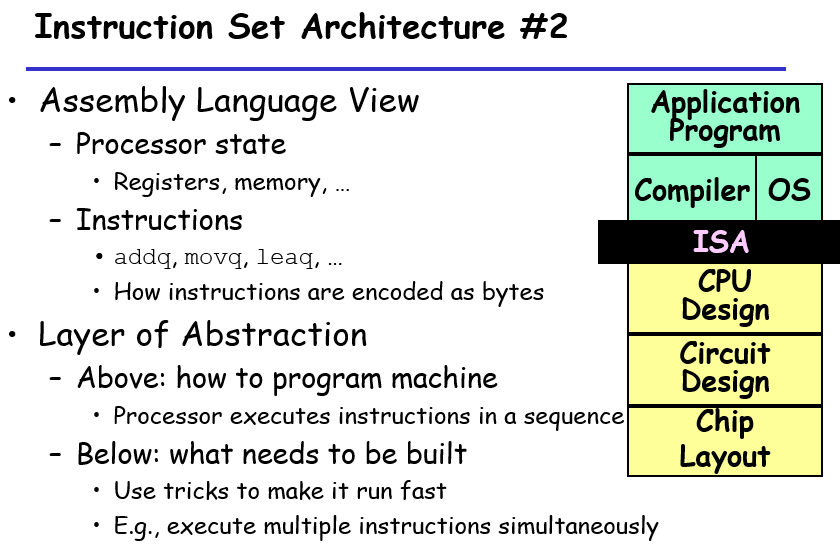
2-2 hcl
[[#目录)
数字电路逻辑门:输出是输入的持续性响应,意味着在输入变化时,输出会经过一定的延迟才会变化;C的逻辑表达式可以被部分求值(a && !a) && b,而逻辑电路没有部分求值的规则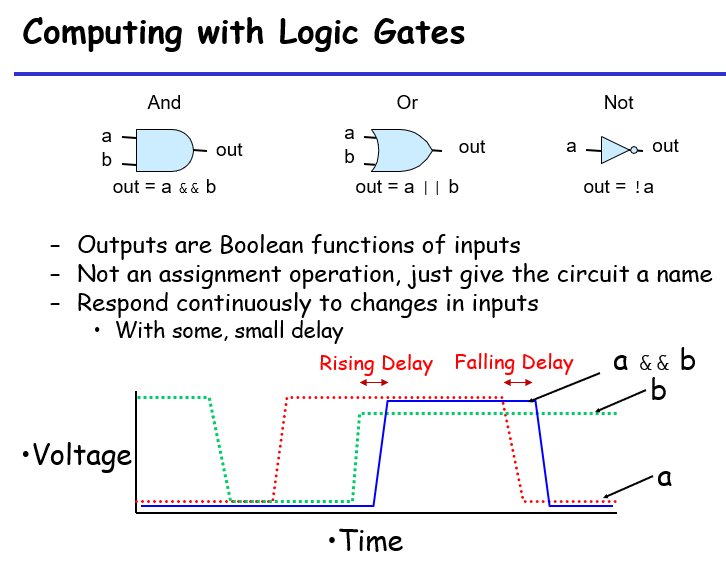
字级相等判定电路,bit级相等判定逻辑(a && b) || (!a && !b)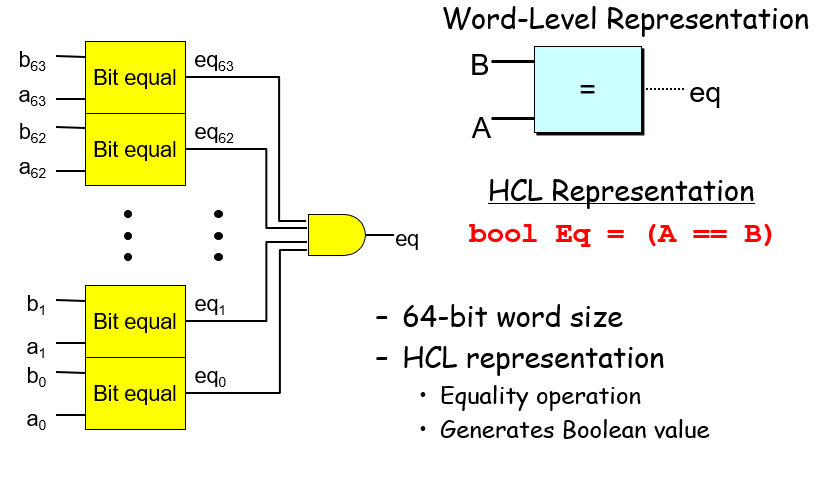
字级多路复用器电路,bit级逻辑为(s && a) || (!s && b)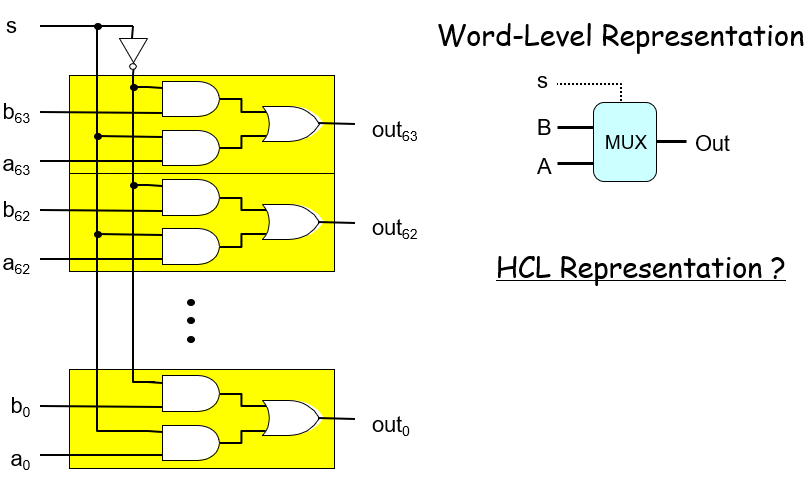
HCL的表达式为case expression 情况表达式,其框内的每个情况是遵循“第一个求值为1的情况会被选中”,有点类似于C语言的switch:.png)
单个位的多路复用器表达式,当s=1的时候选A,否则选B
寄存器时钟上沿数据存储原理:当Clock未发生Rising edge的时候,其输出端口O的值保持不变,而输入端口I的值不会触发O的改变;当且仅当发生Rising edge的时候,输入端口的值才会传到输出端口上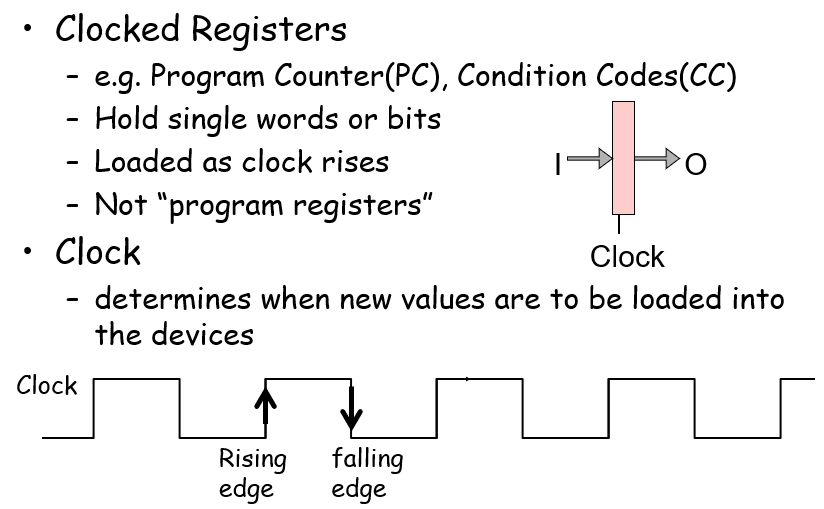
寄存器文件解析:有两个读端口和一个写端口,读端口会将寄存器文件中存有的数据写入读端口处的寄存器srcA,srcB,写端口会通过上面的寄存器时钟上沿更新规则,在时钟上沿的时候将文件里面的数据更新为valW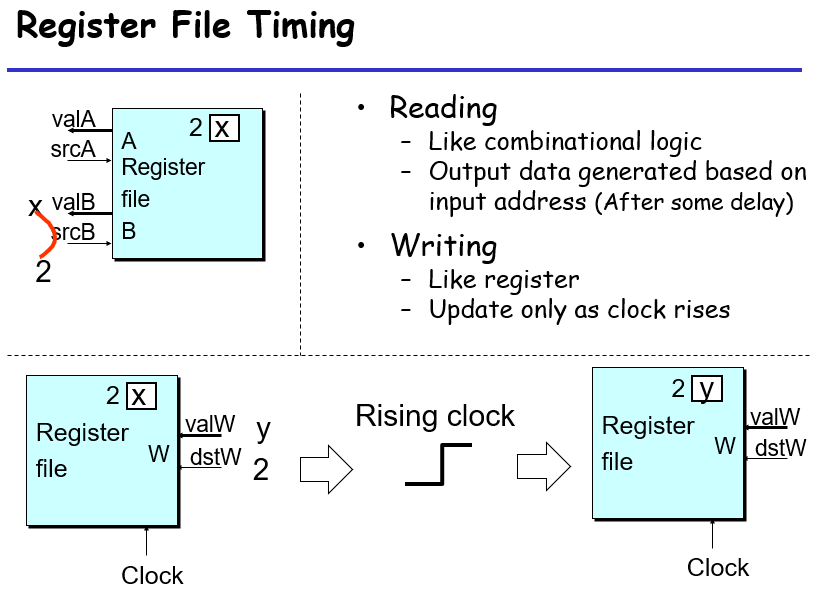
2-3 SEQ
[[#目录)
状态码:遇到错误后不执行,类似于Python
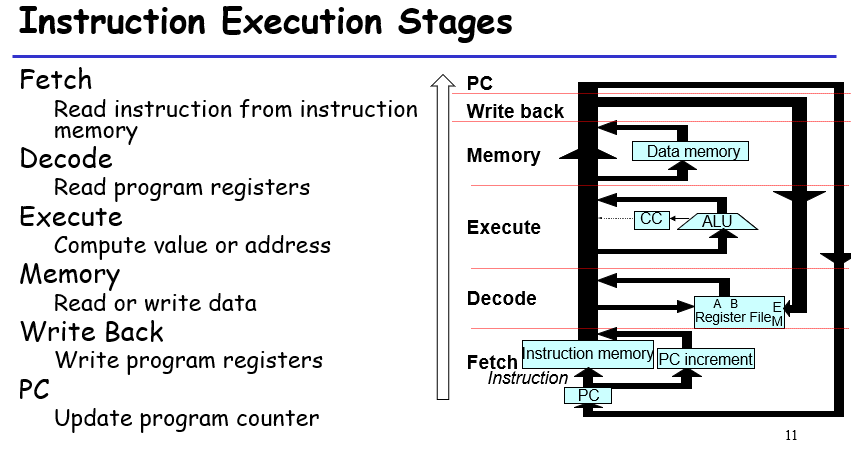
对每个指令的机器码分别执行:读取头一个byte,获取寄存器和立即数位置;获取寄存器值;进行计算,更新CC(如有);(如有)获取内存位置;写回数据;更新PC
注意:Instruction memory一次性加载10个byte,没用到的不读就行;所有的指令,无论是否需要用到全部的阶段,在流程上都需要经过这6个阶段
举例:
- 从PC上获取icode,ifun,rA,rB,valP(next PC),valC(constant)
- 获取存在寄存器上的值,给到变量valA,valB上
- 通过计算得到想要的值valE,同时根据情况获得cond, cc
- 通过valA, valC, valE获得内存上的值,或者写入内存,注意内存与valA有直接通道,故一般没有和valB有联系
- 将获得的数据valE写入寄存器中,所以有的时候会有valE<-valA+0的类似冗余的阶段
- 根据已有值计算PC
预留的空格意味着预留给其他指令的指令空间;同时这些指令并非依次完成的

一个cycle执行一条指令,在一个clock edge同时更新寄存器文件、内存、PC、CC的值,组合电路不需要clock edge即可流入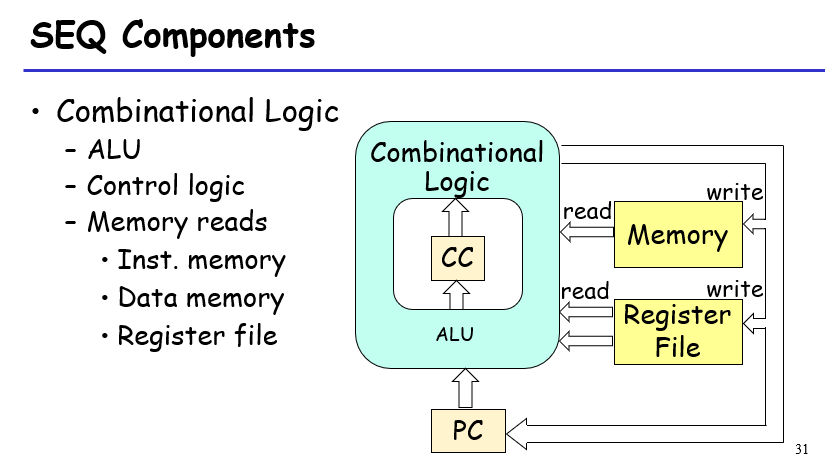
需要再解析一下:比如这边标的cycle 3,这里相当于目前5个非组合电路(寄存器文件、内存、pc、cc、program status)仍处在cycle 2结束后的状态,而ALU的产出已经到达5个非组合电路的门口等待输入;此刻只需要一个clock edge即可以完成0x00c: addq %rdx,%rbx的操作,将需要改变状态的非组合电路基于cycle 3的指令和cycle 3之前的状态进行更新即可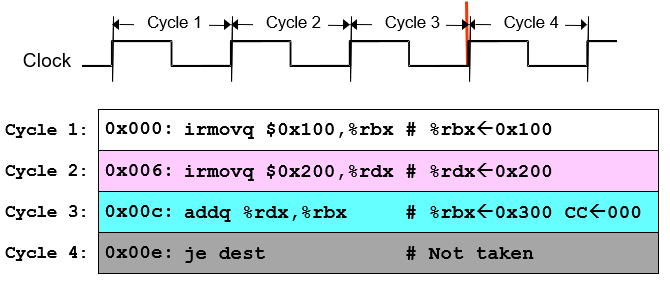
特别注意一下,步骤write back内,会保证后面的指令覆盖前面的指令效果
总结:
val B可能是自动添加的,比如像pushq popq这种需要rsp但是没有明说的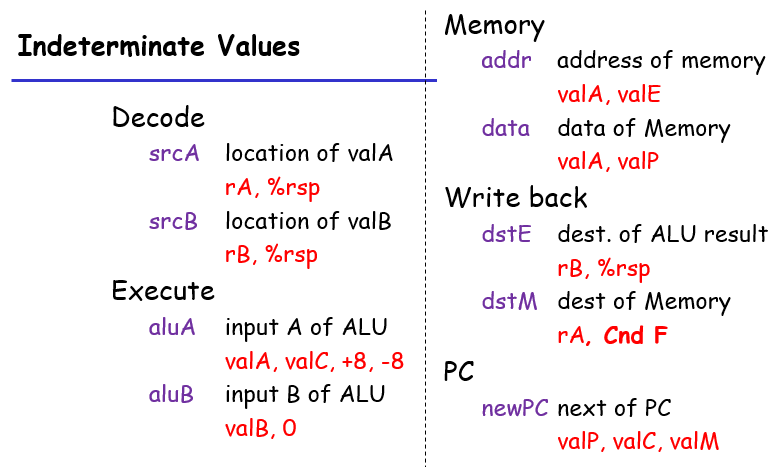
设计电路抽象: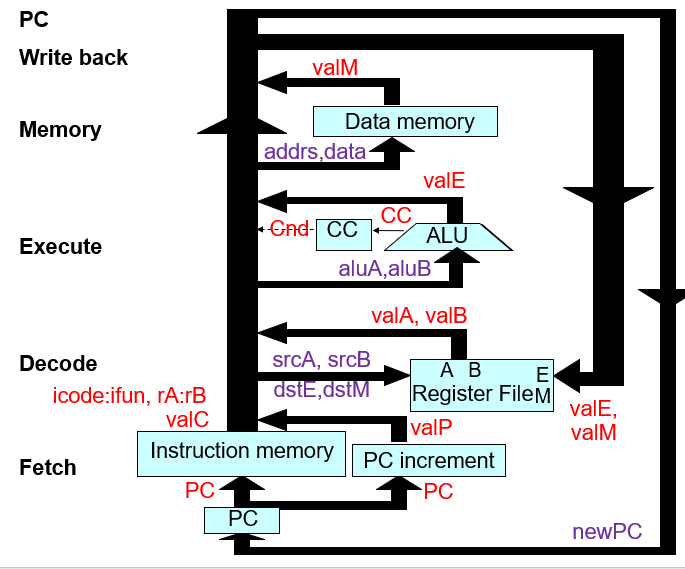
2-4 SEQ Implementation
[[#目录)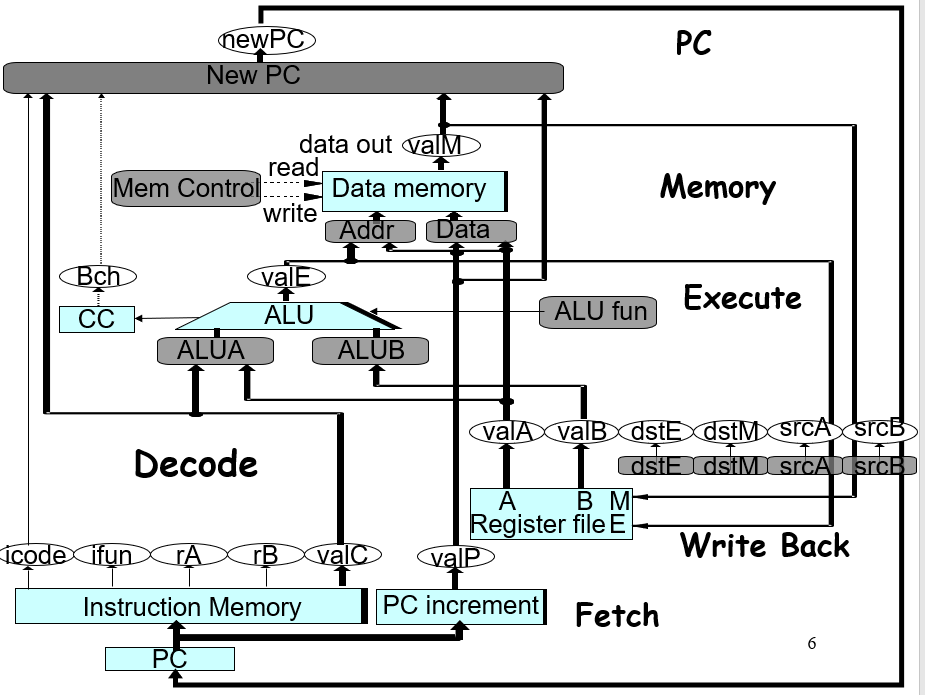
重点是灰颜色的组合电路部分的设计,如何产出正确的值
Fetch
必用的是icode ifun,icode会使用在PC的增量上,根据icode可知此指令是否具有reg imm;其他如ifun rA rB valC为可选使用项,无需使用时也需要经过整个执行周期,不过最后会被设置为不对CPU状态进行改变;instr valid只是会认为非0-B的icode为错误,否则即使是词不达意的其也将其视为合法指令;如果imem_error内存错误,那么会直接把icode改成nop(0x1)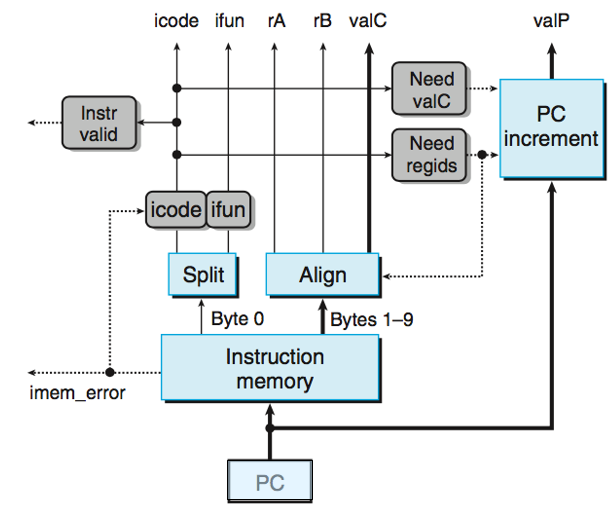
假设icode ifun的组合不属于合法的指令,实际上instr valid也会被设置为0,触发不合法的结算;imem_error是由instruction memory的内部电路逻辑来触发的
Decode & Write Back
灰色的部分是计算过程,也就是将要写入的值的计算逻辑;而蓝色部分是要写入的值,比如写入的srcA就是告诉register file,最后valA输出是取决于哪一个寄存器;以及dstE是告诉register file,最后写入的valE是输入到哪一个寄存器中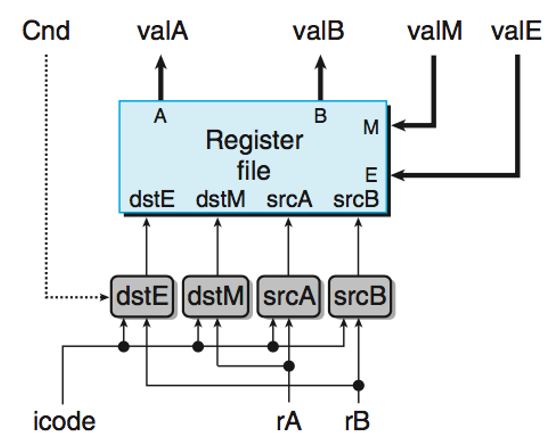
RNONE表示此处获取valA不需要寄存器
RNONE表示此处valE不需要写入某个寄存器
Execute
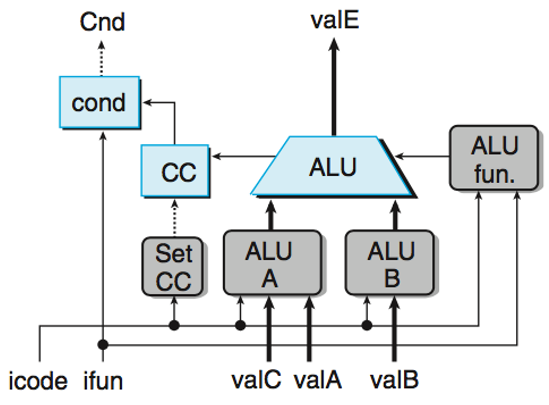
具体还是根据icode类型来确定两个ALU A/B是读进去(或者直接设置为)什么值,然后再参与ALU的计算
Memory
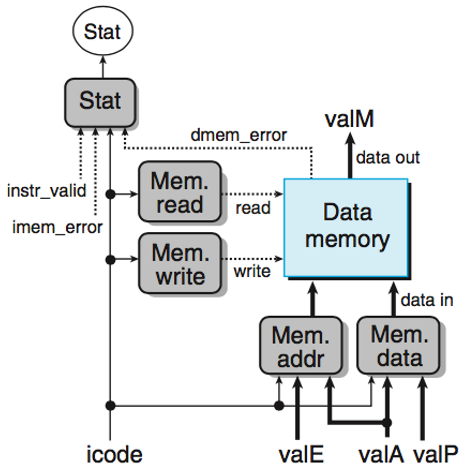
确定是否从内存中读值/是否将值写入内存
确定要执行操作的地址
PC Update
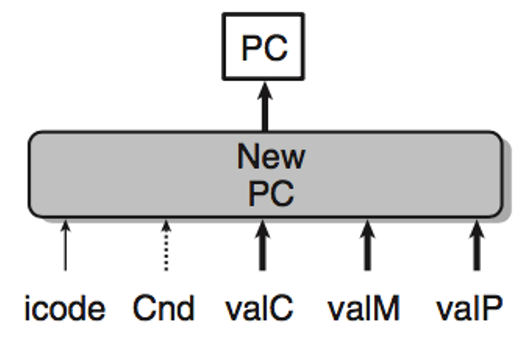
有些情况下新的PC是取决于写入的立即数地址的,或者栈上的一个值
2-5 Pipe
[[#目录)
流水线意在让多条指令同时在一个设计电路周期中运行,这样可以节省不少时间;实现这种想法,理论上来说需要在每个阶段添加“保存寄存器状态”的阶段,也就是说要让一个指令在执行的时候都保有自己执行前一个指令的时候计算得到的,且能够用在后续指令的状态值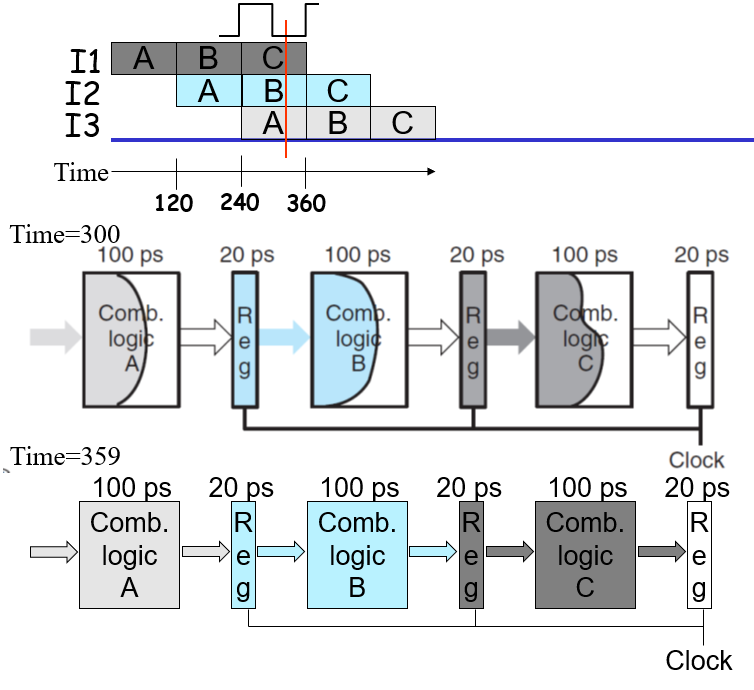
每个时钟周期上升的时候会写入寄存器值(比如361ps的时候,寄存器的值就会被前面的逻辑组合电路灌满),而在非上升阶段则是让指令在每个阶段那边跑
不过现实并不是那么美好,实际上一个300ps的周期并不可以完美地均分,而是要根据执行过程来进行切分: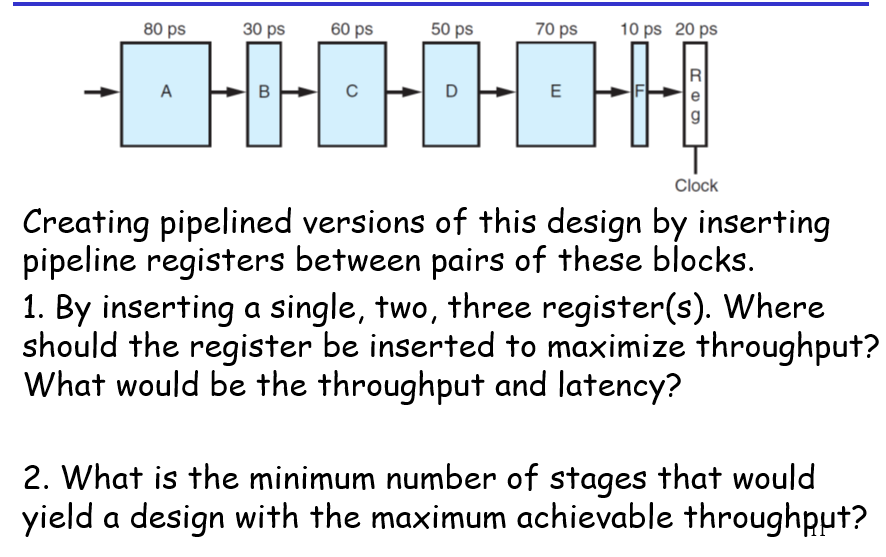
以及,并不是将整个过程分割的越多块执行效果越好的,即使整个计算过程可以分割成无限多块,但是由于寄存器存储也是需要时间的,所以变成了单条指令计算时长非常长,不过吞吐量倒也会相应地优化(分的太细就有点得不偿失了,在每个时钟周期内变成了写入寄存器文件的耗时为大头)
数据依赖和条件依赖
数据依赖:如果是流水线执行的话,前后指令有数据依赖,那么可能会出现在前面指令尚未更新(或者说,即使更新了,也没有更新到后一个指令依赖的寄存器区域)寄存器的值的时候,后面的指令就要用到这个寄存器的值了
条件依赖:如果是有条件跳转/数据传送指令的话,那么可能会因为前面一条指令的cc还没计算出来或者还没传到需要cc指令的寄存器,导致无法及时地进行正确的跳转;在这个时候就比较需要进行“猜测”
流水线实现
我去,这什么玩意啊?SEQ+模型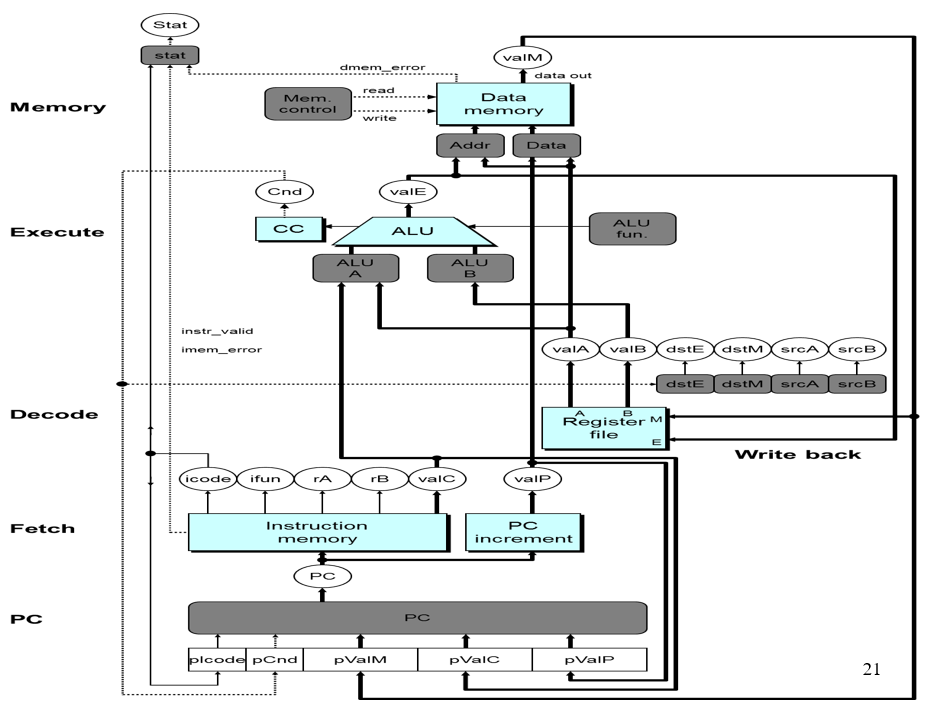
1,PC前移:由于PC在很多情况下都是由valP valC决定的,仅少部分情况下不可以立即由这两个决定(比如条件跳转、ret),所以可以将计算当前PC(通过前面的计算结果进行计算)的过程直接挪到Fetch的前面,这样子就不需要让valP在整个过程中做长时间的无意义的运输;同时,这边也展示出了,其实ISA里面说的PC寄存器并不存在,在流水线中PC是通过一个组合电路来计算出值的,是立即使用的;不过仍然存在其他的寄存器,程序员不可见。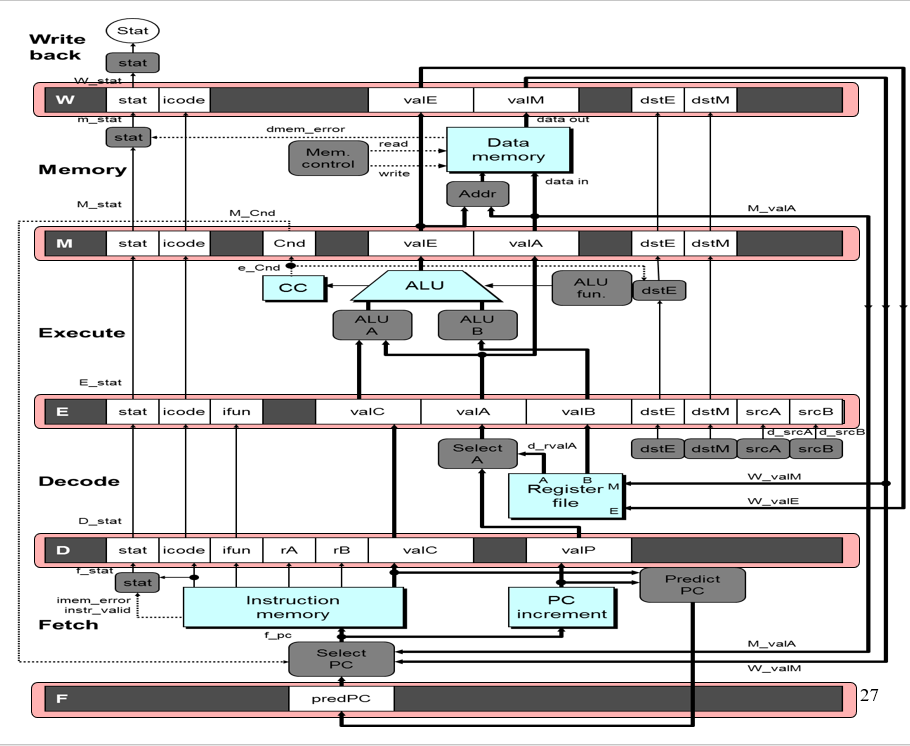
2,过程寄存器:用上面的思路将整个过程用寄存器拆分,每个过程的执行基于其之前寄存器的状态;值的命名有大小之分,开头大写的表示在某个阶段寄存器产生的值,比如:W_valM是写回W寄存器产出的要到Register file的, M_valA是内存M寄存器出来的要到select PC的;开头小写的标识是在阶段过程中产生的值,比如d_valA就是在decode阶段中由register file产生的值;同时在PC之前增加了一个predPC来获取要执行的命令的PC值;Select A其实是valA与valP的共用通道,因为这两个的使用基本是互斥的
实际的流水线硬件示意图: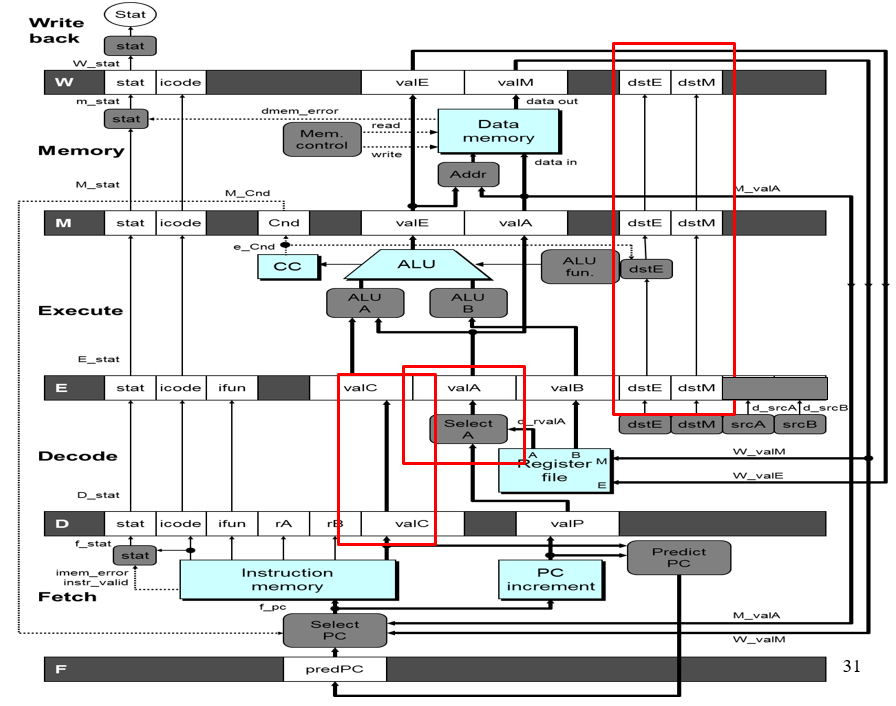
Hazards(风险)
以PC更新为例,有许多场景下,PC是允许在当前指令尚未完全执行完成的时候直接去更新的,这也符合流水线的要求;但是,如果是诸如条件跳转、ret指令的话,就有可能由于数据传送不到位而导致PC过早更新,从而执行到了错误的指令;这个时候流水线也不能停下来,只能去predict(也就是为什么那个寄存器叫做predPC);猜错了的话只能去还原状态了
conditional jumps猜他会跳转,ret摆烂用valP
只能通过返回值来进行可能的修复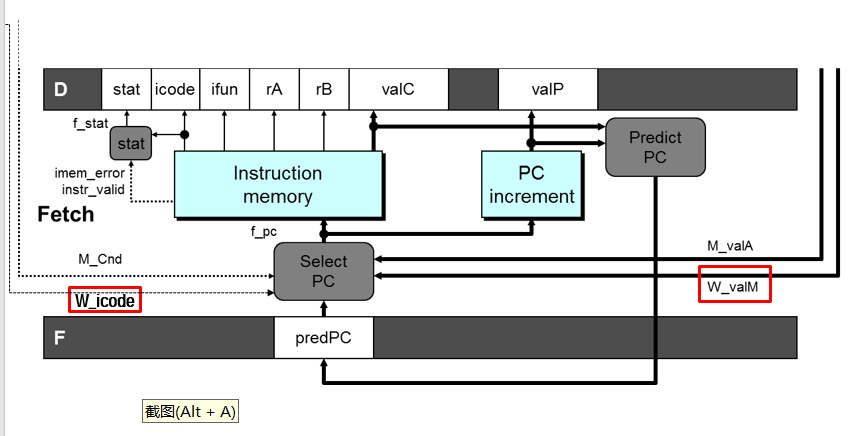
修复的hcl逻辑:
2-6 Hazard
[[#目录)
流水线执行指令的过程并不是一帆风顺的,在数据传送和使用的过程中,会产生一些冲突,导致后面的指令无法完全接收到前一条指令执行过后的结果,从而造成错误的计算、跳转等
首先,整个流水线中,5个寄存器以及register file、cc、memory都是受到同一个时钟的操控;在流水线执行的过程中,受到时钟操控的部件能够接收到信号,获得一个“暂停数据输入、输出nop”指令的功能,称为bubble
数据冒险
在这个情境下,irmov和add需要隔着3条指令,因为add指令目前应该在D寄存器前尚且不能进去,而irmov在E寄存器之前,需要让add能够计算正确的值,只有在irmov的指令效果传到了register file门前才允许add在下一个时钟上沿和这个irmov一起被触发;而从E寄存器门前,到register file门前有3步(E->M M->W W->register file),所以这边要么程序员手动写nop,要么编译器触发机制给你来个bubble,这样子相当于数据在D F寄存器停着不往前走,E M W执行空的nop指令,以此来避免数据传送的冲突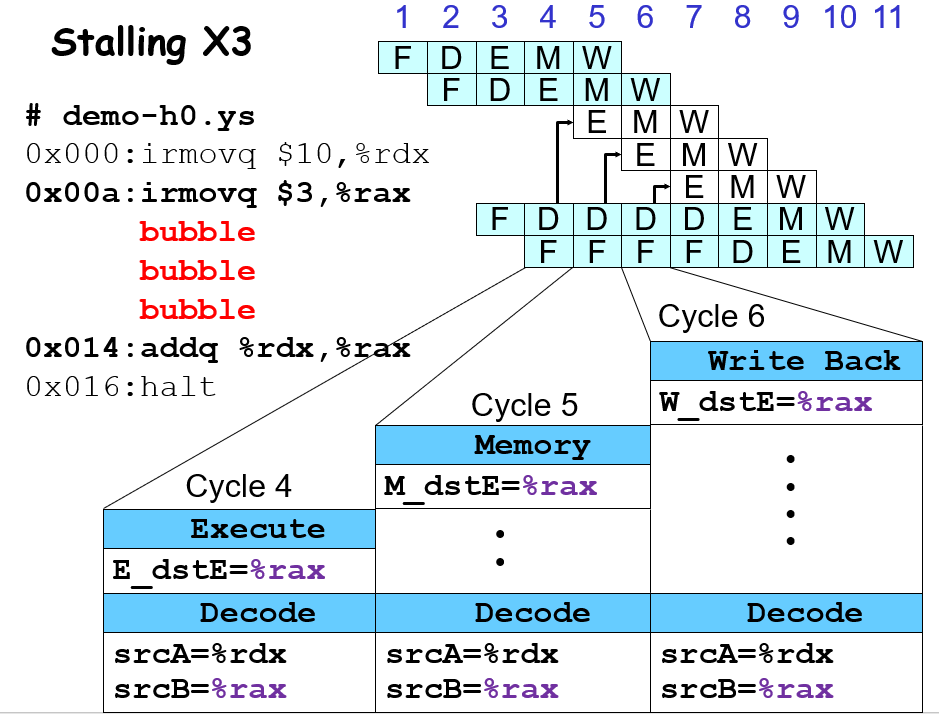
还能更快一点吗?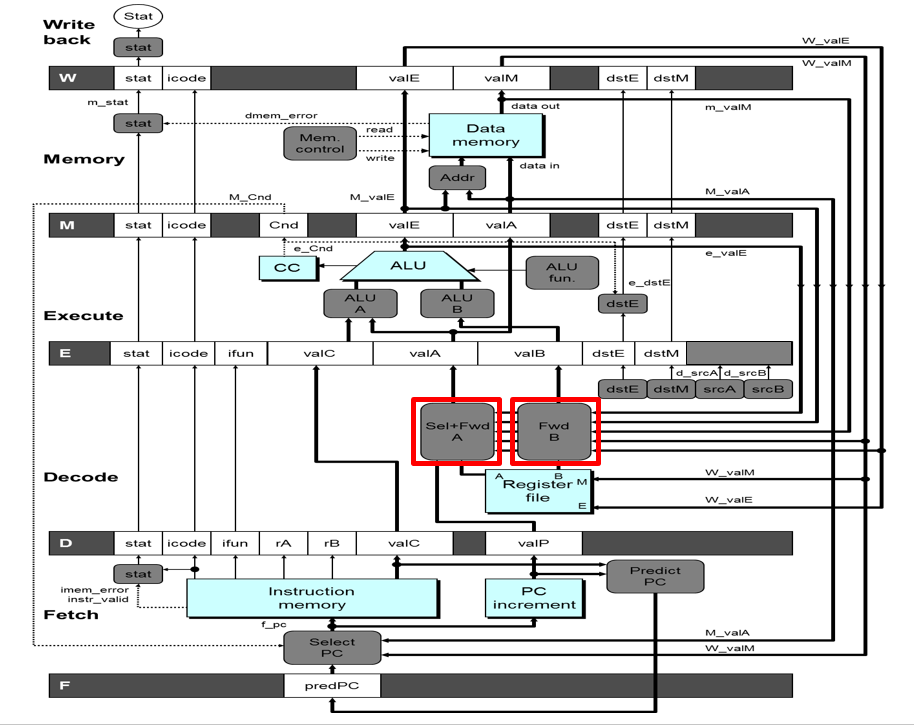
也不是不行,我们需要的是valA valB获取到对应寄存器的值,不过我们不一定非要从寄存器文件去拿,我们也可以在中间过程获取这个值,在写入寄存器之前先拿来用,这样也可以满足我们的要求:比如将W-valE W-valM拿来用,那么只需要2个bubble;如果将e_valE拿来用,那么可能可以不需要bubble,只要来得及将e_valE拿给Execute valB的入口处就可以了
不过这个就涉及到一个时间的问题,通常来看,拿刚从阶段分界处寄存器获取的值会比较保险,因为这些值会及时地填充到Decode阶段的逻辑电路,这样子能够保证最后流向E寄存器的值在时钟周期上升沿之前是预期的值
当然,如果这几个入口都对下一条寄存器的指令有影响,那么肯定是优先选择最靠近该指令的指令(在Exe过程产生值),优先级由近到远递减
当然,数据冒险有的时候必须加bubble,比如mrmov和add相邻,那么根本无法再Execute阶段获取到需要的寄存器值,那么只能等下一个阶段的Memory才能获取到值了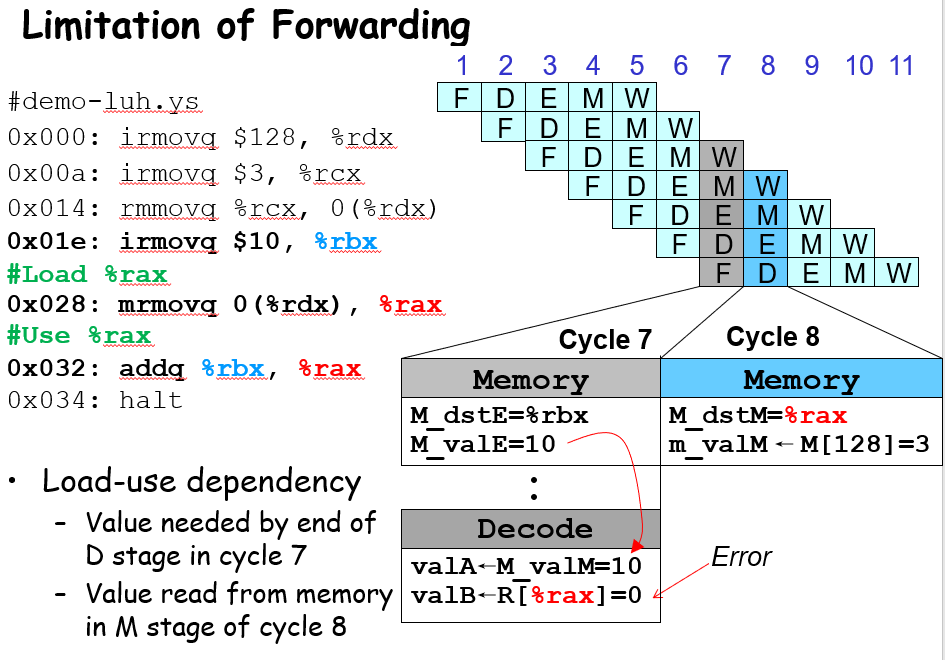
条件冒险
ret 指令到达D寄存器的时候,跟在其后面的错误指令在F寄存器;本身ret 对PC的更正需要等到其进入到write back阶段(W_valM传到PC selector)才可以运行;那么这个过程会有3条指令成功突破Fetch阶段进入到Decode阶段及以后,如果不及时处理会导致其修改寄存器和内存,所以需要加3个bubble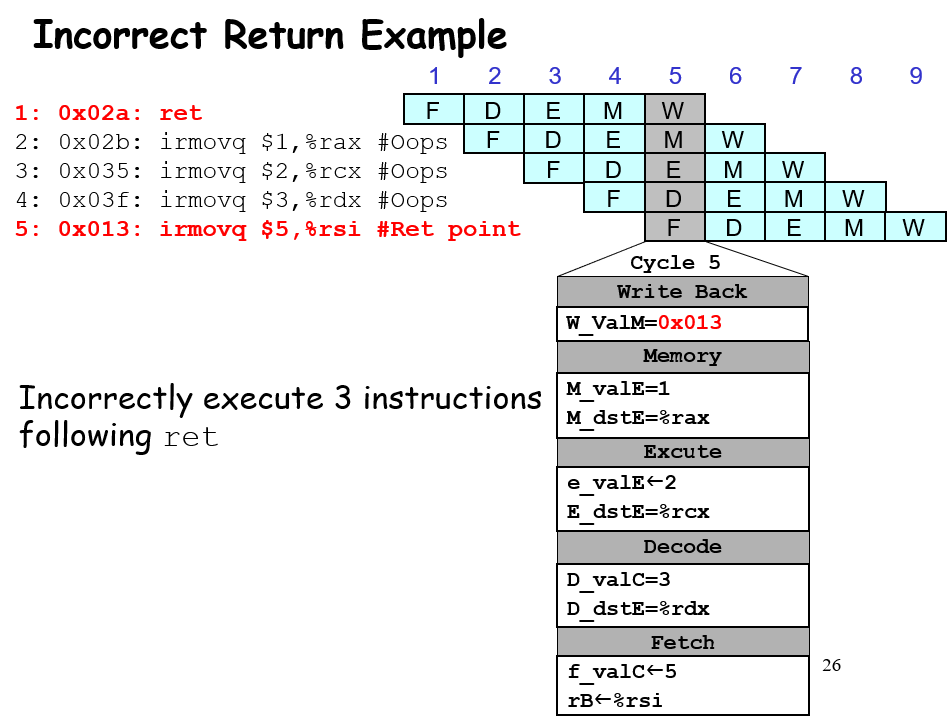
分支预测错误:分支预测错误的信息会在Memory阶段通过M-cnd和M-valA(实际是valP)传到PC selector来修正PC,此时后两个错误指令还在Execute Decode指令,在Execute处的指令尚未更改cc,因为还差一个clock上沿。解决办法是发现跳转错误的时候,将两条错误指令即将要激发的寄存器改为bubble,这样就不会触发更改状态
为什么不用e_cnd和E_valA呢?是不想吗?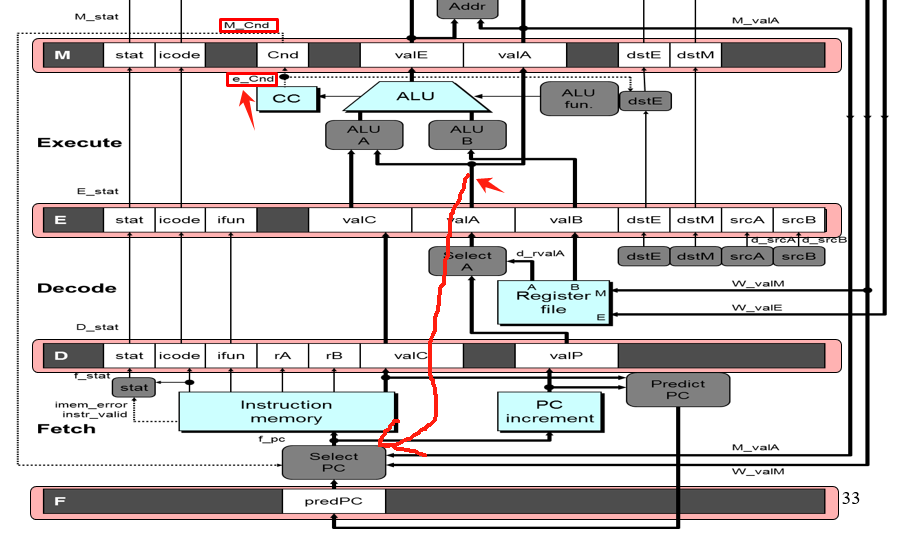
首先,e_Cnd已经在一个时钟周期的较为末端的地方了,他如果牵一条线也是签到Select PC处;那么由于instruction memory比较慢(访问内存某个地址的指令码),所以可能e_Cnd的作用还没有施加到这里,时钟周期就上升了,使用的还是之前逻辑电路产生的旧值,这样子意义就不大了,没有办法得到一个期望的提前修正PC的效果
Exceptions
在指令执行的时候出现了错误,需要去做一些处理;每条错误的指令会在Write back的阶段报错,不过发现错误的时机要么是Fetch要么是Memery;如下图在Memory阶段被检测到,检测到之后会让之后的指令无法造成副作用(修改状态),当然这意味着需要接一条线回去。前面的指令仍然执行
还有一种情况是,如果JXX到了错误的指令但是这个指令不会被执行,那么exception会被检测到,但是因为还没有到达Write back,所以暂时不会让CPU报错;后续会在错误指令进入Memory之前直接给这个指令插Bubble,那么这个指令不会改写状态,其状态码也变成了SBUB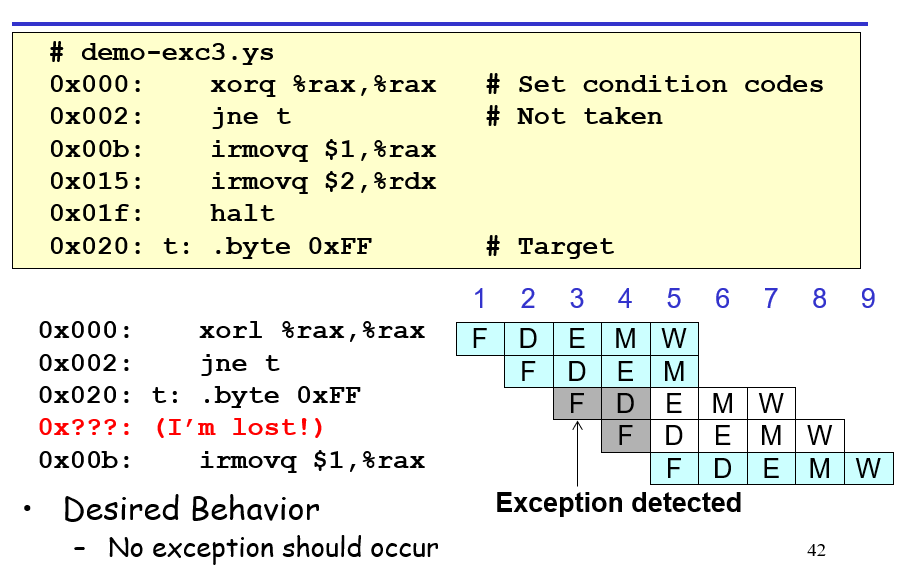
Write back阶段如果指令的状态码不是AOK SBUB,那么就会触发Exception
2-7 CPU Implementation
CPU实现基本上是前面几节思想的复盘,主要是这边将具体的线路统统展示了出来
Fetch
其实只是细化了一下前面的流程,比如F_predPC受到f_icode的影响,取f_valP或者f_valC;f_PC受到了跳转阶段的M_valA(实际上是valP,在不需要跳转的情况下传回来)、W_valM(ret回来的地址)的影响;f_stat则是根据指令的情况(是否错误、halt、imem_error)来设置,比如错误指令就会被识别然后设置为SINS,正常的就传一个SAOK就可以了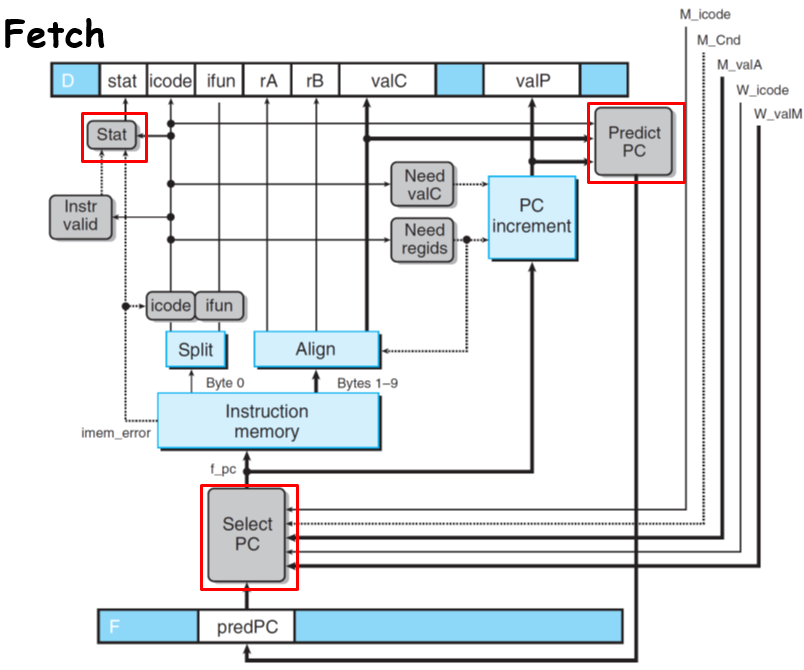
Docode & Write back
decode阶段主要是一个提前写回的线路,就比如之前提到的data hazard,由于可以直接在前面Execute阶段将计算出来的值写到FwdA FwdB,所以不需要加bubble;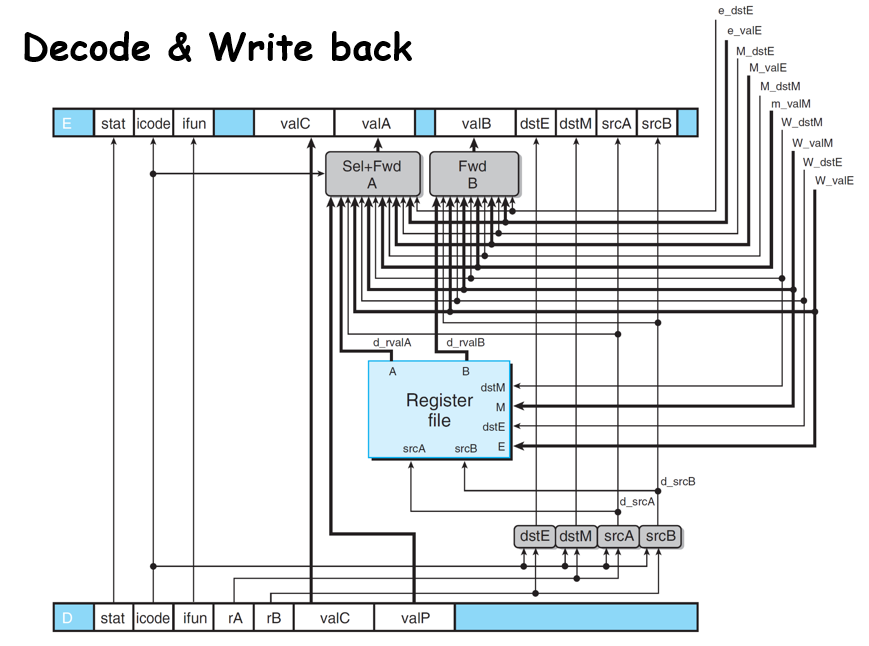
顺序问题:首先是写入离decode阶段更近的产出值,同样近的优先写valM: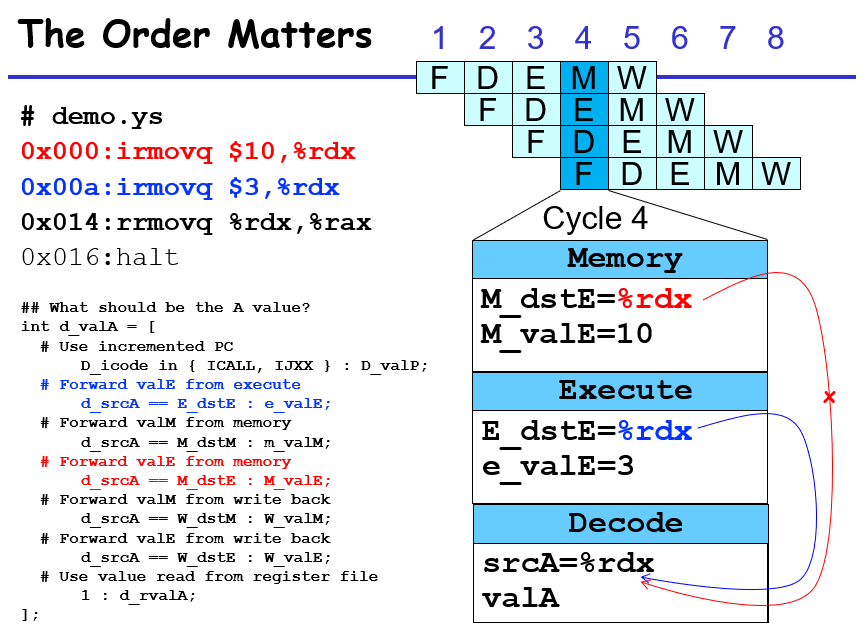
Write back除了传数据给其他的阶段以外,只需要承担一个更新全局program status的功能,即如果是SBUB则设置为SAOK,否则就按照当前到达W阶段的状态去更新全局状态,再看看需不需要Exception
Execute & Memory
Execute阶段只要是处理是否更改CC的问题,条件有:
1)OP指令更改CC;2)W_stat m_stat是正常的,而非错误的,这一个条件意味着前面的指令并没有出错,以及当前的OP指令有没有出错(因为此时OP指令已经到了Memory阶段了,而CC是和在OP在Memory阶段即将进入Write back一起接受时钟上沿更新的)
Memory阶段如果访问地址异常则设置m_stat为SADR
Load Use Hazard
这玩意其实是由于要写入寄存器的值在内存里面(load),但是下一条指令就要用到这个寄存器的值(use);由于这个需要用到的值顶多只能在Memory阶段被获取到,对于要用这个值的指令必须在Decode门前等一个周期,才可以在进入Execute前拿到预期的值,所以这边需要加一个bubble;这边除了mrmovq以外,popq也可能出现这种情况;同时要确定E_dstM是否在d_srcA d_srcB里面(要在M阶段获取的寄存器是否是要在E阶段使用、D阶段获取的寄存器)
Normal & Stall & Bubble
正常情况下,时钟上沿会导致门口的输入数据进入到这一层寄存器中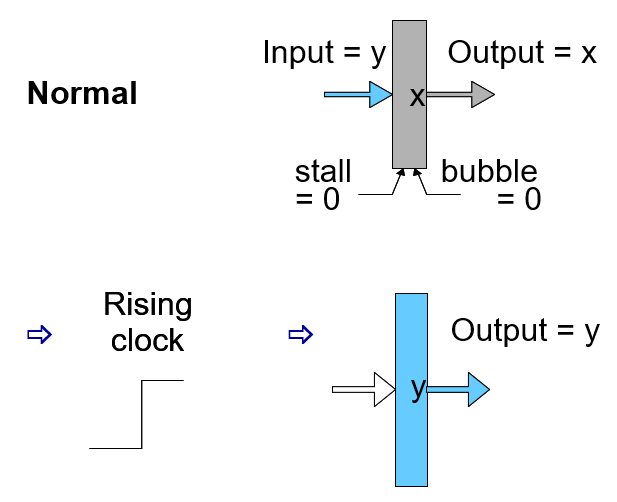
Stall意味着输入的数据不产生作用(没有进去),但是之前在寄存器的数据仍然在下一个过程中起作用;Bubble意味着不仅输入的数据没有进去,原来在寄存器的值也被设置为nop,相当于全部不起作用
就好比load/use,其在use指令即将到达execute阶段的时候,保留execute寄存器之前的状态,先让execute寄存器输出一个nop指令,并让load指令去前往memory阶段;然后load指令获得寄存器中的值并且将其送到decode阶段的时候,execute的bubble解除,decode和fetch的stall解除,程序可以继续通畅的运行
放弃不要的指令直接在其要进入D E阶段之前加bubble,然后F阶段正常运行,这样子后面的指令就会把前面的指令“推到沙滩上”;想要保留指令的才是F D阶段加stall,后面加bubble,这样子的效果是延期执行
更正: 对于bubble stall的理解应该更新一下,以jxx+ret为例,jxx在Execude阶段就可以检测到条件的异常,然后其可以挡住E D寄存器阶段指令的输入,也就是jxx在进入M寄存器的时候,此时的E D寄存器被插了bubble;此时ret在D阶段,流到E的数据被bubble擦掉了,而D又会流bubble将其清洗掉,这样相当于ret并没有发挥任何作用,对于这种默认情况不需要调整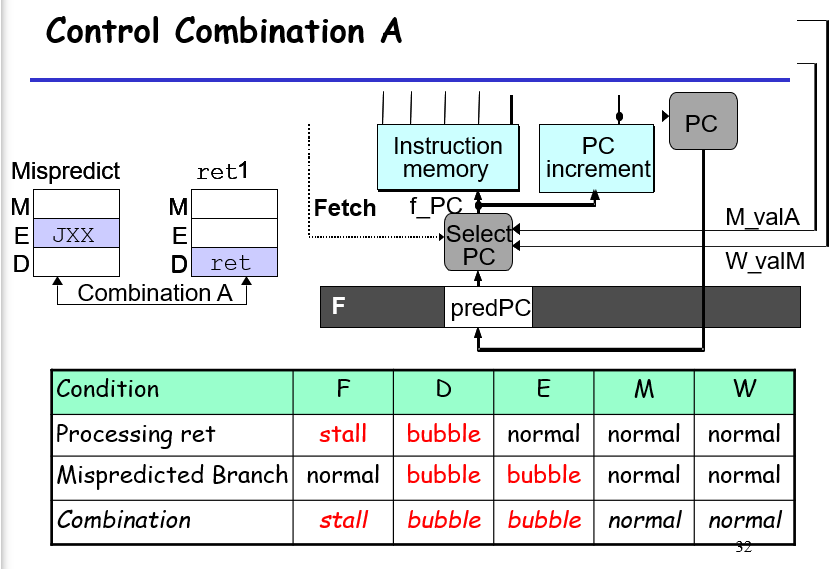
再来分析一下load/use和ret的冲突:这里的冲突主要是load在E而ret在D,此时load发现自己要修改的寄存器在ret中要用到(rsp),所以其在进入M之前会给E寄存器发信号让其变成bubble,同时让D寄存器stall住原来的指令(在这里为ret);而ret此时在D阶段,它的后一步操作是前往E并且给D寄存器设置bubble清除后续指令;这里首先D寄存器的stall bubble冲突了,而且如果采用bubble则会让ret指令直接被擦除,所以这边应对冲突的方式是在D寄存器只保留stall的效果
CPI
Fetch单个有效指令耗费时钟周期数,一般大于1.0,因为需要插bubble:
mispredicted,load/use,ret的平均插入bubble数加上1就是CPI的值,目前是1.27
可能的优化
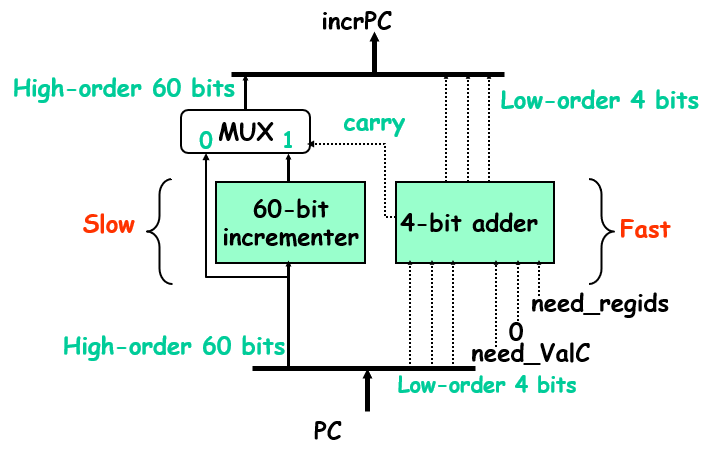
比如这里将低4位PC和60位高位分开计算,频繁变动的只有低四位,那么就可以在低四位不进位的时候执行高效的运算,节省时间