计算机系统基础II之:虚拟内存
Weiquan Huang2-17 malloc
malloc函数概览,要求多少空间就开多少能用的空间,不过事实上是有一定的多余空间的——必须开的是地址8对齐的空间,因为type *p=(type *)malloc(sizeof(type)),在实际使用的时候,为了保险起见,能够让空间能够存放uint64_t类型的数据,所以强制8对齐地址,这会导致一定的空间浪费
拓展堆区空间的函数sbrk(int),如果开空间成功,返回原来的栈顶(堆区空间的可伸长的末尾),参数可以为负,表示收缩空间
优化堆区空间内存的性能:
- throughput是指存取数据的速度,比如1秒能够存/取多少数据
- utilization是指空间利用率


碎片:内部碎片与外部碎片
内部碎片是指给数据开空间的时候,为了让数据满足地址8对齐,或者为了加上内存数据块隐形链表指针,导致的已使用但是并非用于存储数据的空间;外部碎片是指,在内部总空间足够,但是没有一块连续的能够存储预开空间大小的空间,就会产生外部碎片
堆区内存块的结构
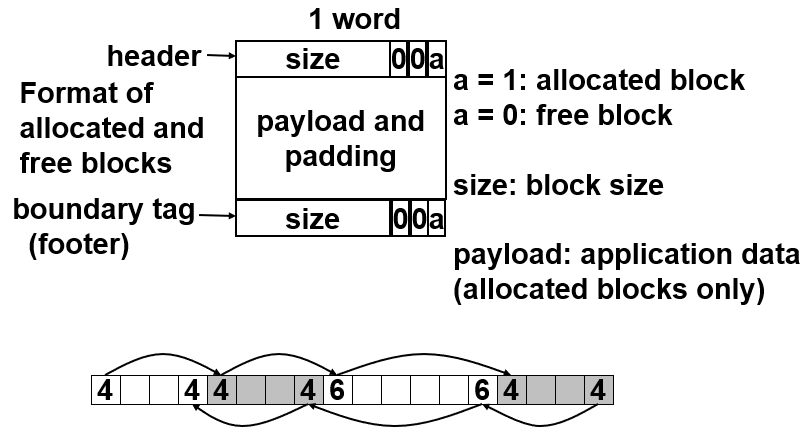

回答一下这五个问题:
- 在数据块之前/之后加4byte用来存放size和a(是否空闲)的信息;注意size是整个块的size,单位是bit,这样用来标识这个数据块的大小
- 在标记位置,前进size,可以到下一个数据块,查看是否空闲
- 一般尽量去找那种与预存数据空间匹配的空间(减小空间的浪费)
- 将空间分块,每一块都有头尾标记
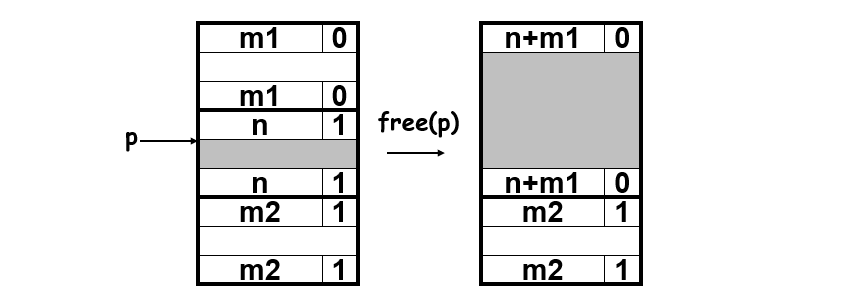
- 每次使用的时候都通过头尾标记来合并可以合并的空闲空间
澄清误会:size-a并不是表示小端法的存储方式,只是表示size为高位数据,a为低位数据;由于size必定是8的倍数,因此其低3为必定为0,在低1位放置一个bit用来存放是否为空闲的信息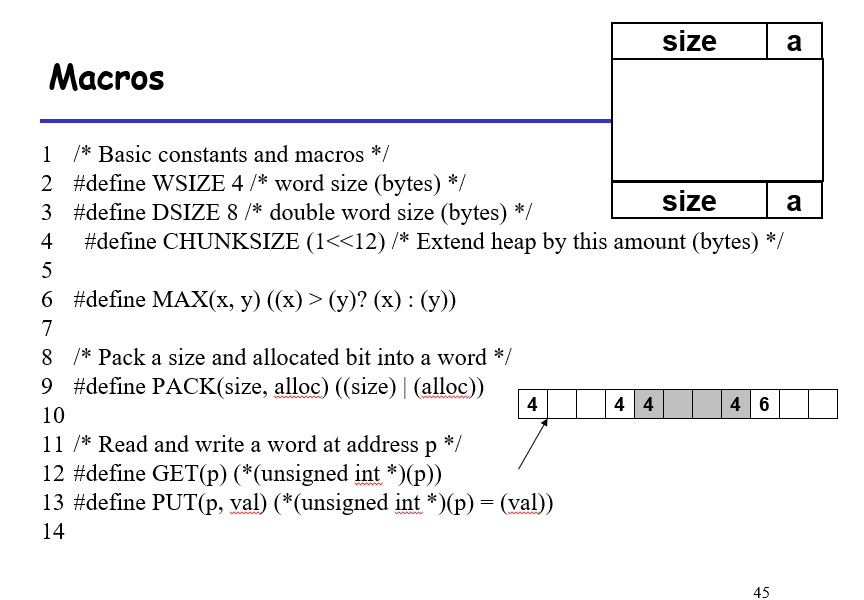
代码实现堆区开辟空间?意会一下,PPT代码也有,写lab的时候借鉴一下~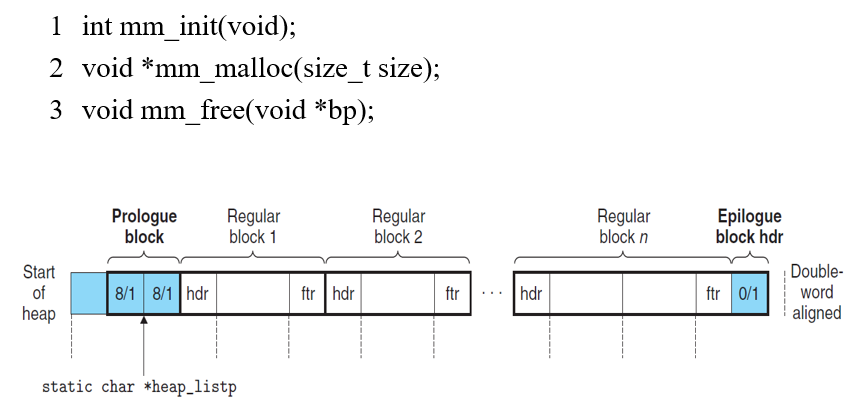
如何实现更好的性能??
Segregated Storage
将相同大小区间的空闲块连到一起,组成若干个链表;分配任务的时候可以直接选到对应链表的表头进行分配即可。但是这个方式还是有可能造成一定的内部碎片,比如长度为10的需求分配了长度为16的空间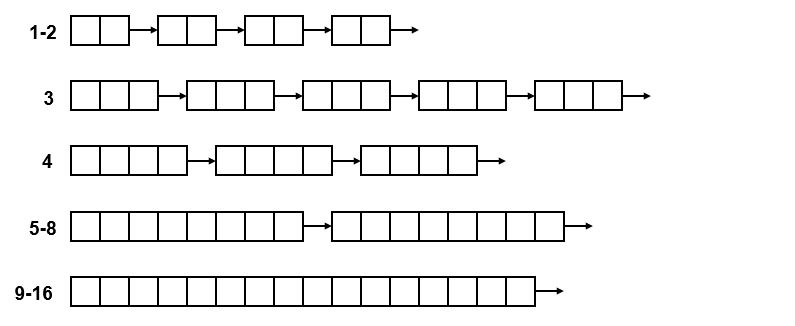

为了解决内部碎片的问题,有一种叫做Segregated Fits的策略,其支持在分配空间过大的时候去将未用到的空间插入到对应区间的链表中
Buddy Systems
每个块的大小为2的次方,具体来说,如果需要存15KB的数据,那么会先去向上取整,比如16KB,取到最近的、大于自身的2的次方;然后如果取到的是32KB,那么就需要将其分成2个16KB,给一个16KB给他;这个被分配的16KB如果被释放了,那么其会和自己原来的配对(如果此时配对空闲)合并成更大的空间块,依次递归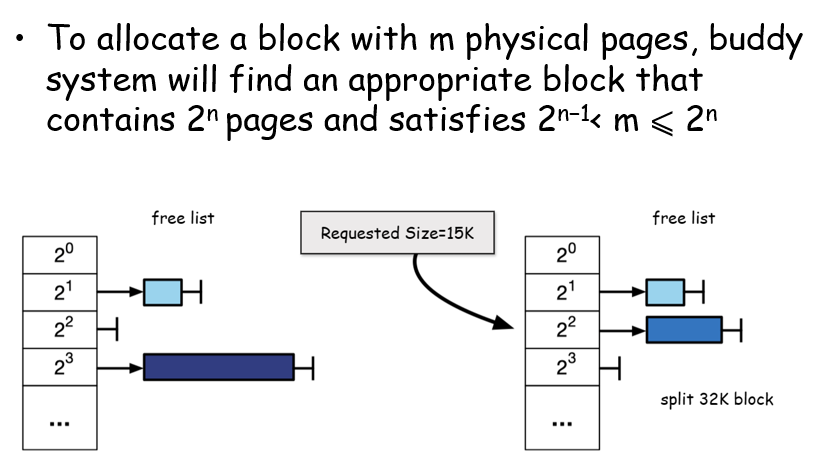
为什么可以找到结对的空间?结对的空间在位运算上和自身只有1个bit的差距,作差就是这两个块的首地址距离
SLAB Allocator
也可以将堆区内存分成不同的Slab pool:每个池标记自己可以分配的空间是32byte,然后找到对应的pool之后就可以在某个slab里面进行分配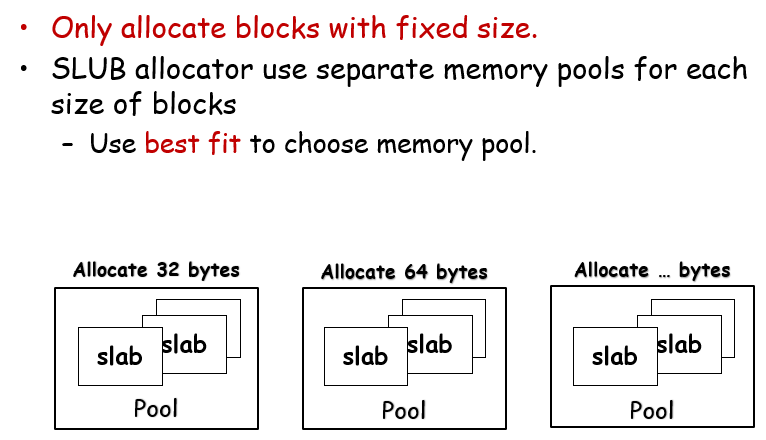
这里每个slab的大小也是固定的,这意味这,假设每个slab的大小都是2MB,那么每个slab的起始地址都是2MB的倍数;每个pool内会有一个current slab,用来响应当前要分配的请求;而每个pool维护了一个链表,名为partial,维护半空的slab;全满的不维护、全空的直接释放。
分配的步骤是:在current slab找一个空间进行分配,找到之后,会将这个地址内所存储的下一个空闲地址块的地址取出,存放到Next_Free里面(注意:每个空闲的slot会存储自己的下一个空闲块的地址,即指针),然后自己被分配,数据被复写
回收的步骤是:在free(p)处传入的是一个指针,那么首先会释放这个指针的地址所在区间,然后对这个地址去零头,找到自己属于哪一个slab(向下取整找到最近的2MB的倍数),然后就知道自己存储的Next_Free,以及自己这个slab存的数据块大小了,这样就可以准确地去释放正确数量的空间,同时将Next_Free的指针给新的空闲区域,而新的空闲区域地址被存到Next_Free里面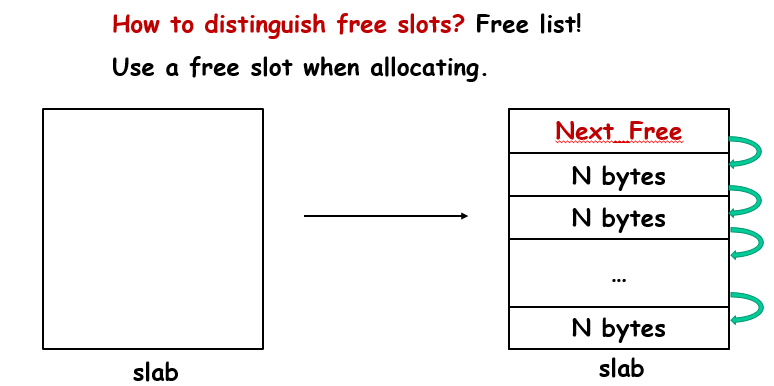
需不需要维护满slab?其实不需要,释放对应的指针就可以拿到这个slab的地址,将其插入到partial内就可以;释放空slab的原因是为了避免霸占空间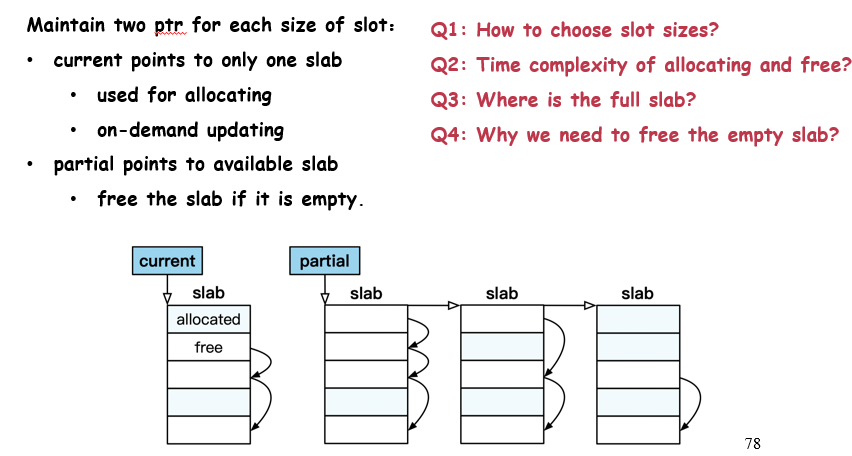
2-18 garbage collection
垃圾回收实际上是会回收那些,不会被指针(比如局部、全局变量定义的指针)间接或直接指到的空间: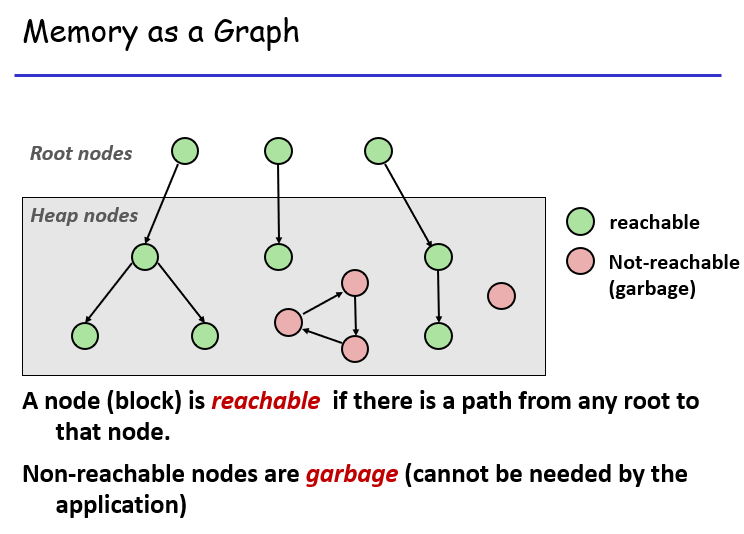
垃圾回收器处理的步骤:先对能够被指向的空间进行标记,然后去清理那些没有被标记的空间;深度优先搜索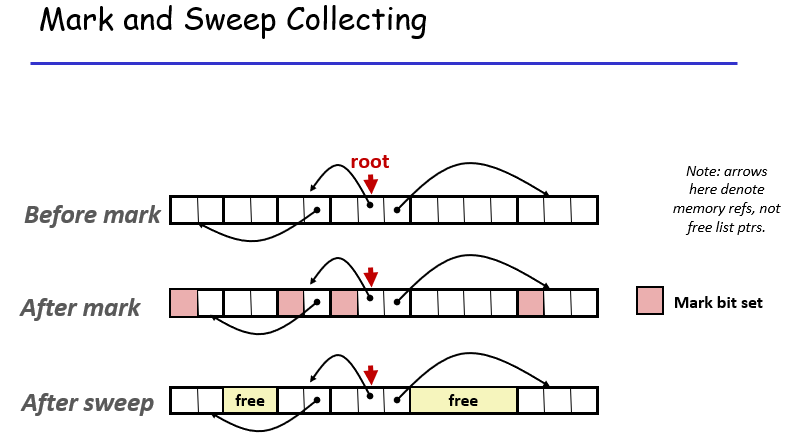
最后是举了一些挺抽象的内存错误,用来说明C语言是一个内存风险的语言,比如malloc未初始化、空间大小不合理、重复释放等问题
2-26 vm
一个进程的虚拟地址空间是通过一定的策略映射到实际的物理内存的:
- 首先虚拟地址空间之间相对独立,没有交集
- 虚拟地址空间和物理地址空间之间有相互映射的关系,由CPU来进行映射
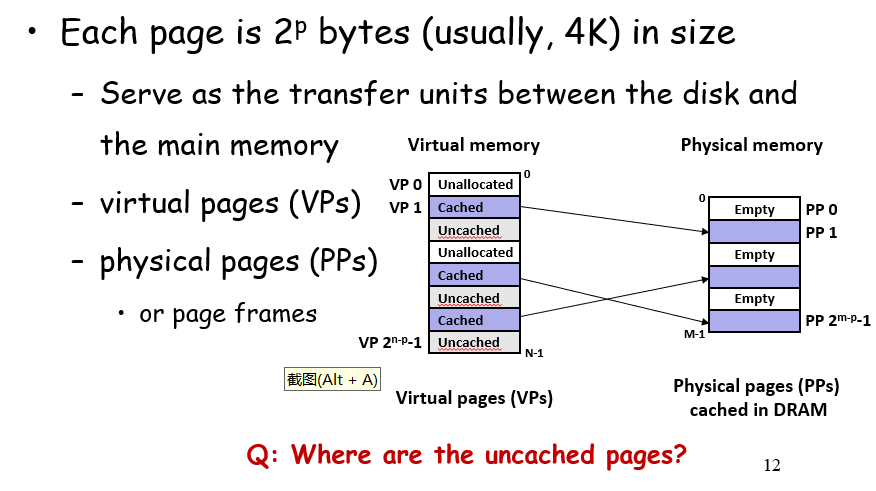
- 映射按需,不是整个空间都要映射,而是分page进行映射
三种类型的虚拟内存页: - unallocated 不可能被分配到物理地址空间的虚拟内存地址,比如0x0
- cached 已经在物理内存有映射关系的虚拟地址页
- uncached 可能被分配到物理地址空间的虚拟地址页,但是尚未分配,会指向一个暂存内存数据的磁盘空间
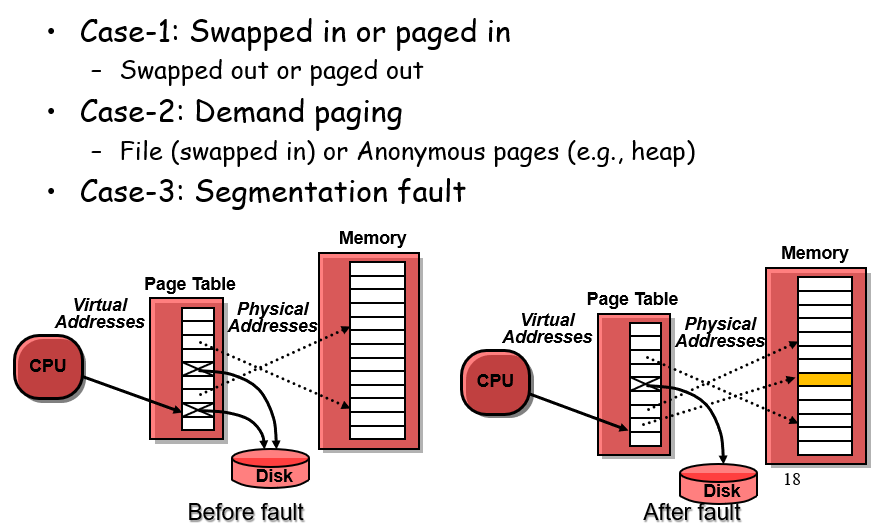
如下图,如果没有命中,会报缺页错误(chp8有提及),随后根据其类型来将磁盘内容放到内存的一个页或者直接segfault
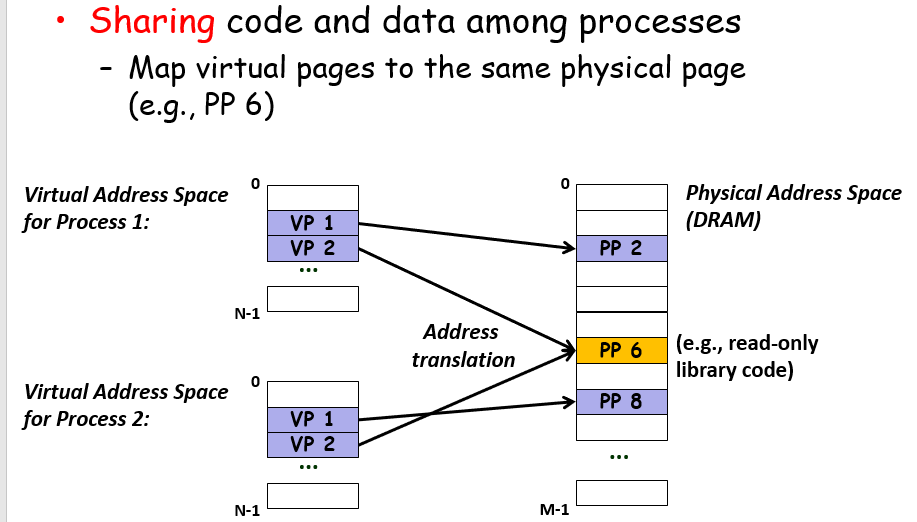
对每个虚拟内存到主存的映射并无限制,允许共享内容
优点: - 高效利用主存(用DRAM缓存)
- 简化内存管理(映射)
- 隔离不同进程的内容
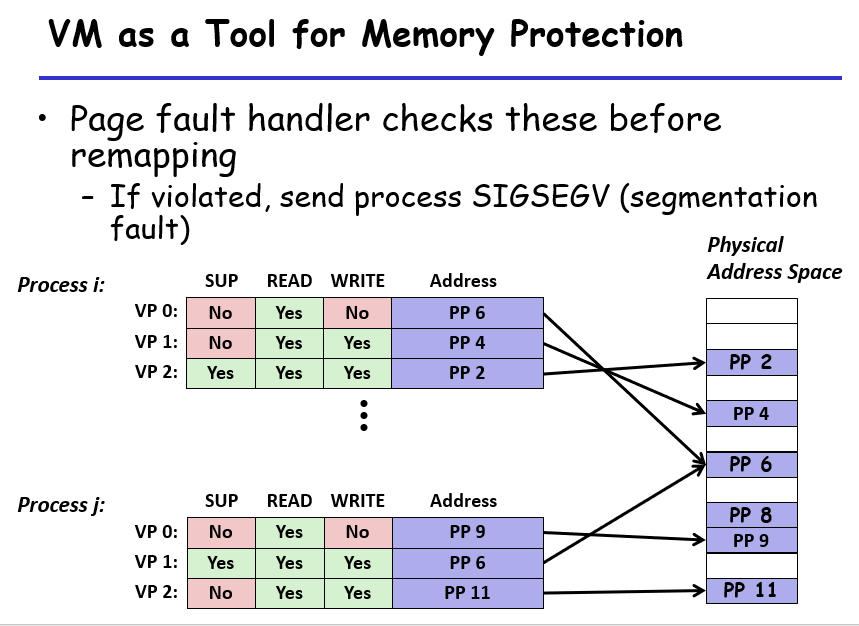
- 记录不同权限
2-27 trans
虚拟地址有n位,物理地址有m位,page有p位,虚拟地址和物理地址的组成如下图;每个进程(虚拟地址)都有一个Page Table,用来给该进程以映射的标准,其通过OS来管理,存放在物理内存的内核区域;PTBR用于标识进程的table在哪里,是一个名为CR3的寄存器,存储table的entry address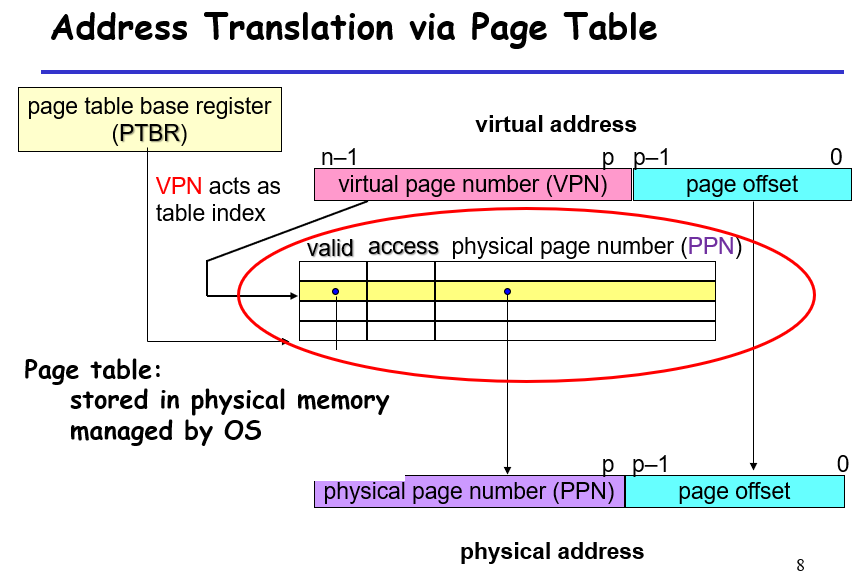
Page Hit
可根据table来找到vp对应的pp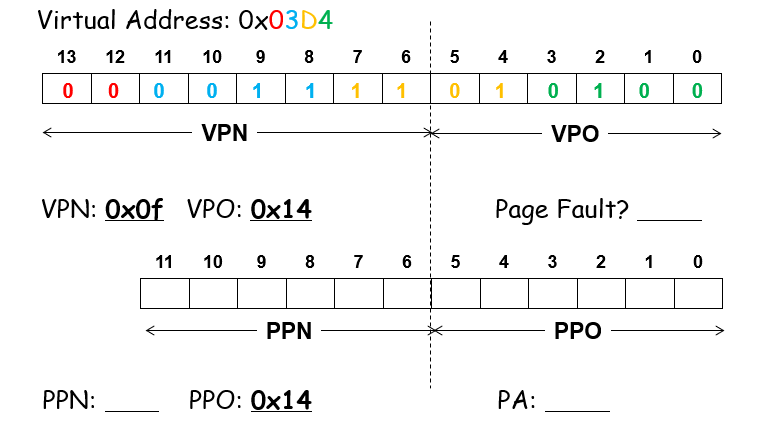
流程:先从内存中获取table entry address,然后valid之后就可以拿到pte,然后翻译,获取数据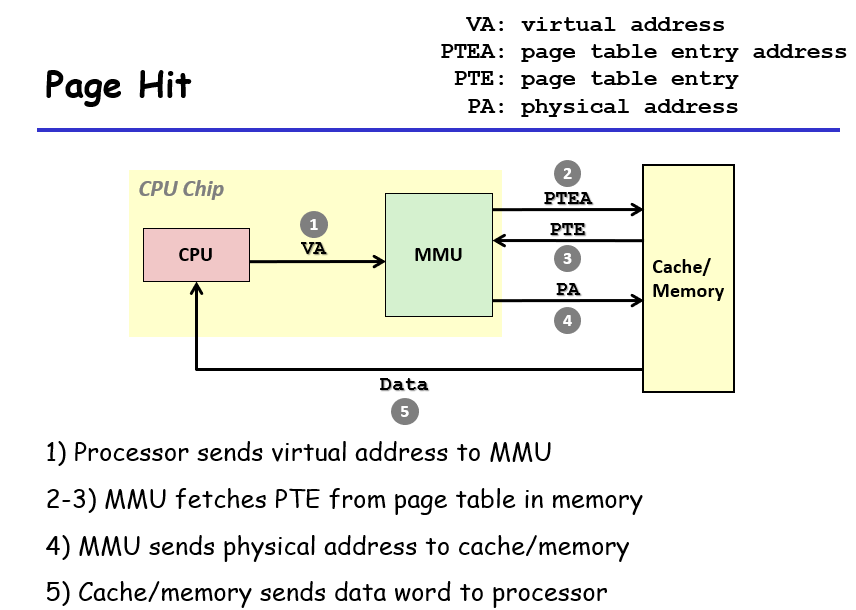
Page Faults
找不到会发生page fault,发一个signal,请求内核将disk的内容放到memory,然后再次运行这个程序(的出现错误的这一行);当然也有可能直接SegFault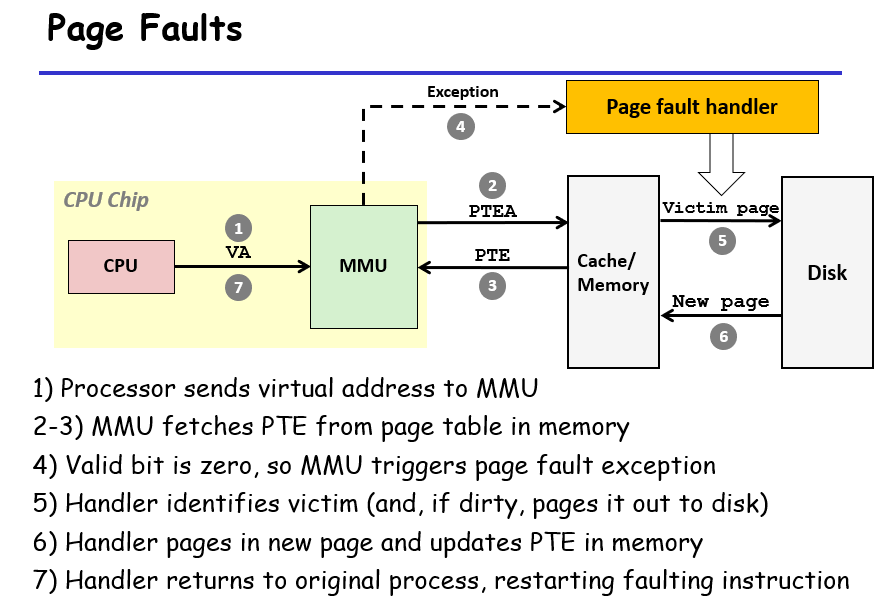
如果每次MMU都从内存去获取PTEA,那么太慢了,对于PTE的获取也是有类似于缓存的机制,被称为TLB(Translation Lookaside Buffer),如图,先从TLB中尝试获取已经缓存的PTE,若无才会去内存中寻找(寻找到了会使用类似于LRU的替代方法来对TLB的部分进行替代)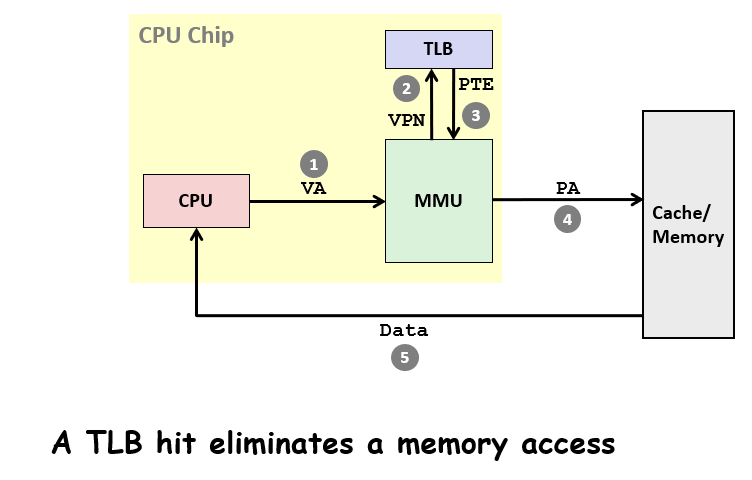
TLB如何运作?原先vpn是一个索引,现在将vpn划分成2个部分,TLBT是tag,TLBI是所属的set的index,整个机制与cache十分相似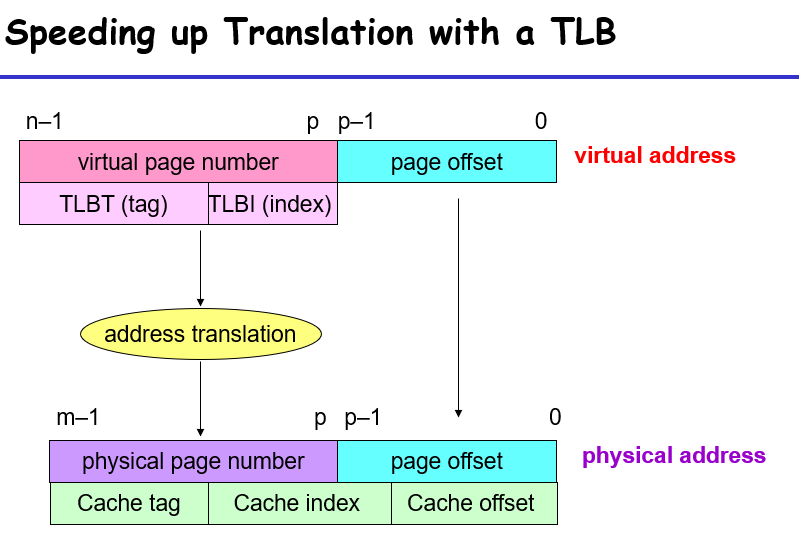
具体的例子?根据TLBT和TLBI来搜索是否有缓存,有的话返回PTE,MMU读一下valid看是否合法,合法即命中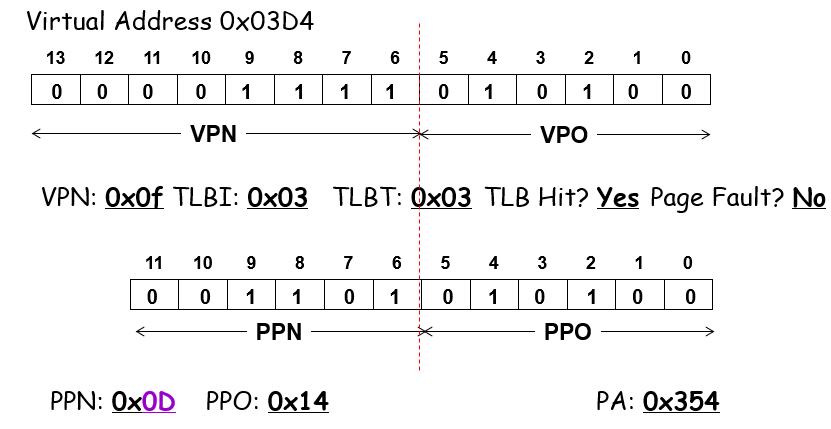
多层页表
上面都假设一个虚拟内存的Page Table是连续的,也就是说一个X86-64的48bit地址空间的虚拟地址,其4KB的页大小,就需要有36位的VPN来存储,折合一下就是512GB($2^{36}*8$),存在磁盘里都不够
事实上一个虚拟内存的空间大部分是用不到的,有很多空闲的块,但是为了访问PTE的速度,又不得不设置一个连续的Table,所以引入一个多级页表的概念
比如你可以第一级页表存粗粒度的,如果粗粒度范围没有有效的物理内存就直接null,有的就进入下一级页表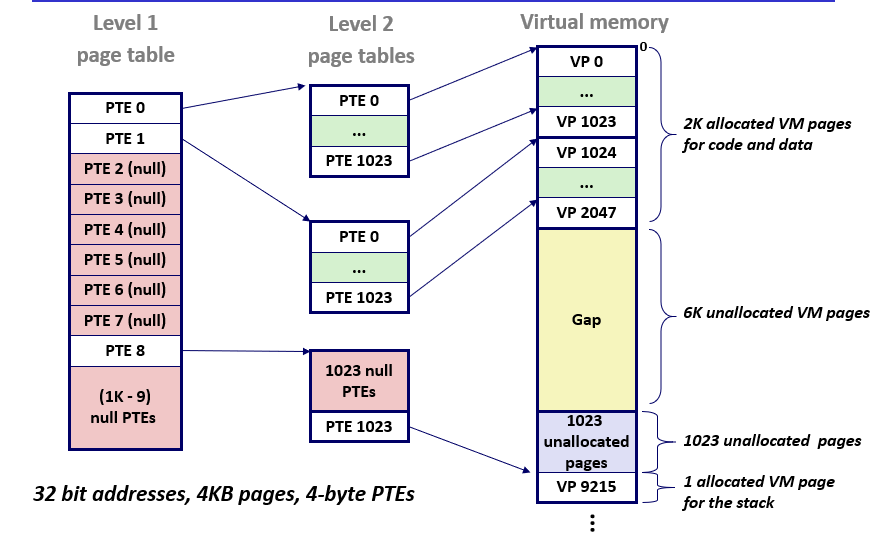
设计的概念就是将vpn继续划分成几个部分,每个部分作为多级页表的各个部分的索引,这样子可以获得最后的PPN和PPO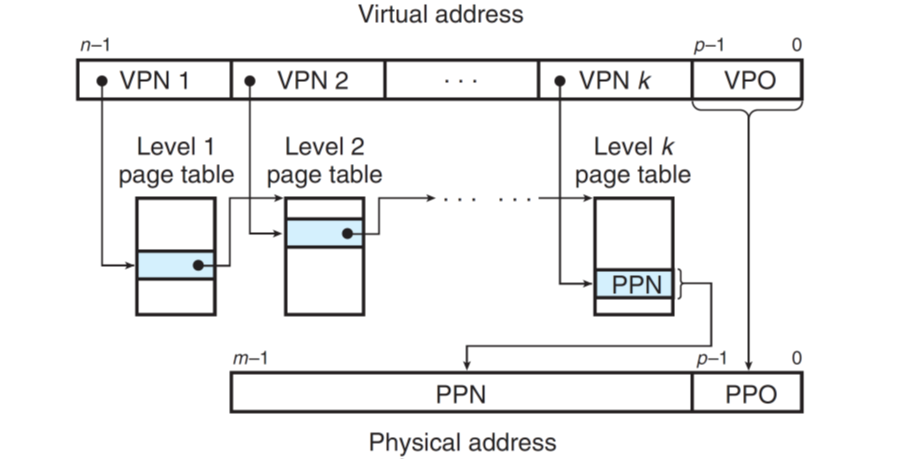
Core i7的地址获取结构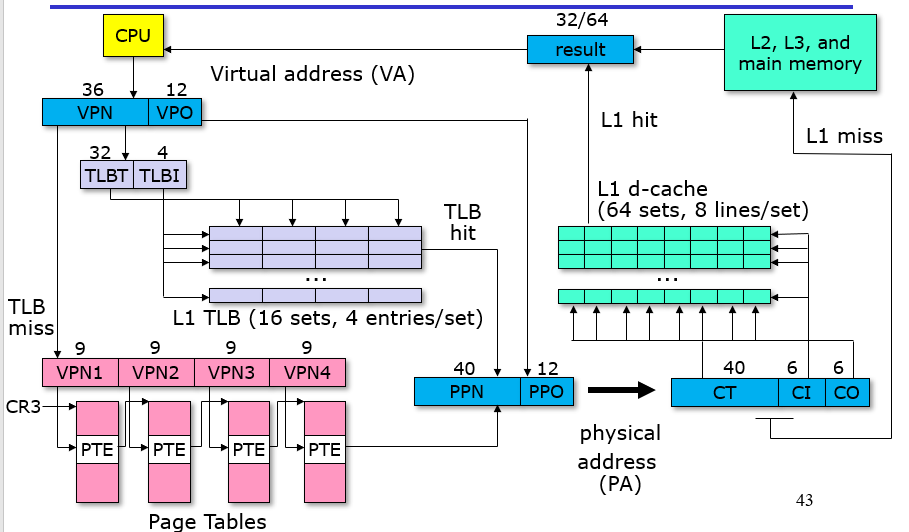
2-28 linux
Linux会给每个进程维护一个vm_area_struct,这个结构会管理所有有效的(not unallocated)虚拟地址块,pgd是CR3存储的页表基地址,CR2寄存器会存储翻译错误的地址,留待翻译使用;给定一个虚拟地址,如果不是有效空间直接SegFault,或者权限有问题也不能访问成功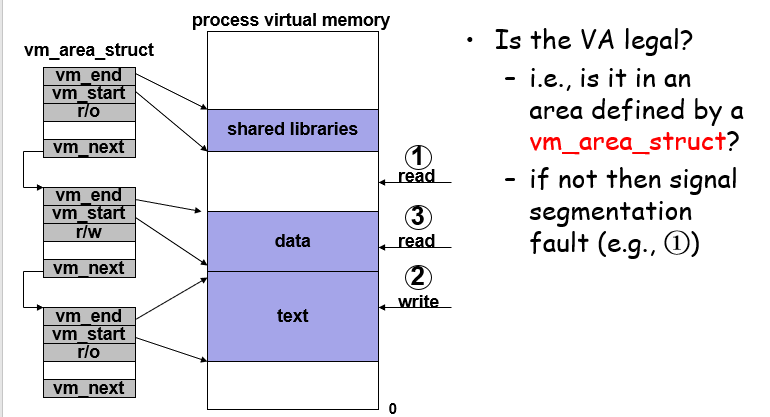
swap文件:假设所需要的所有虚拟地址空间为18G,但是物理地址又16G,为了满足需求,磁盘会有一块2G的swap file,用来存储那些暂时用不太到的内存内容,被内核管理
demand paging:按需分页,不将全部有效虚拟内存全部映射
如果开了一个子进程,子进程也会有虚拟内存,子进程会先清除掉继承自父进程的vm_area_struct和page table,然后自己新建,指向新的虚拟地址空间;这里涉及到一个shared libs的东西,他存放了共享的库文件,但是对于每个进程来说,其是私有的,因为这些库文件里面也有可修改的数据字段,比如errno,在errno.h文件中,用于标记库函数调用失败的错误代号(补充,errno是线程安全的)
磁盘文件读取
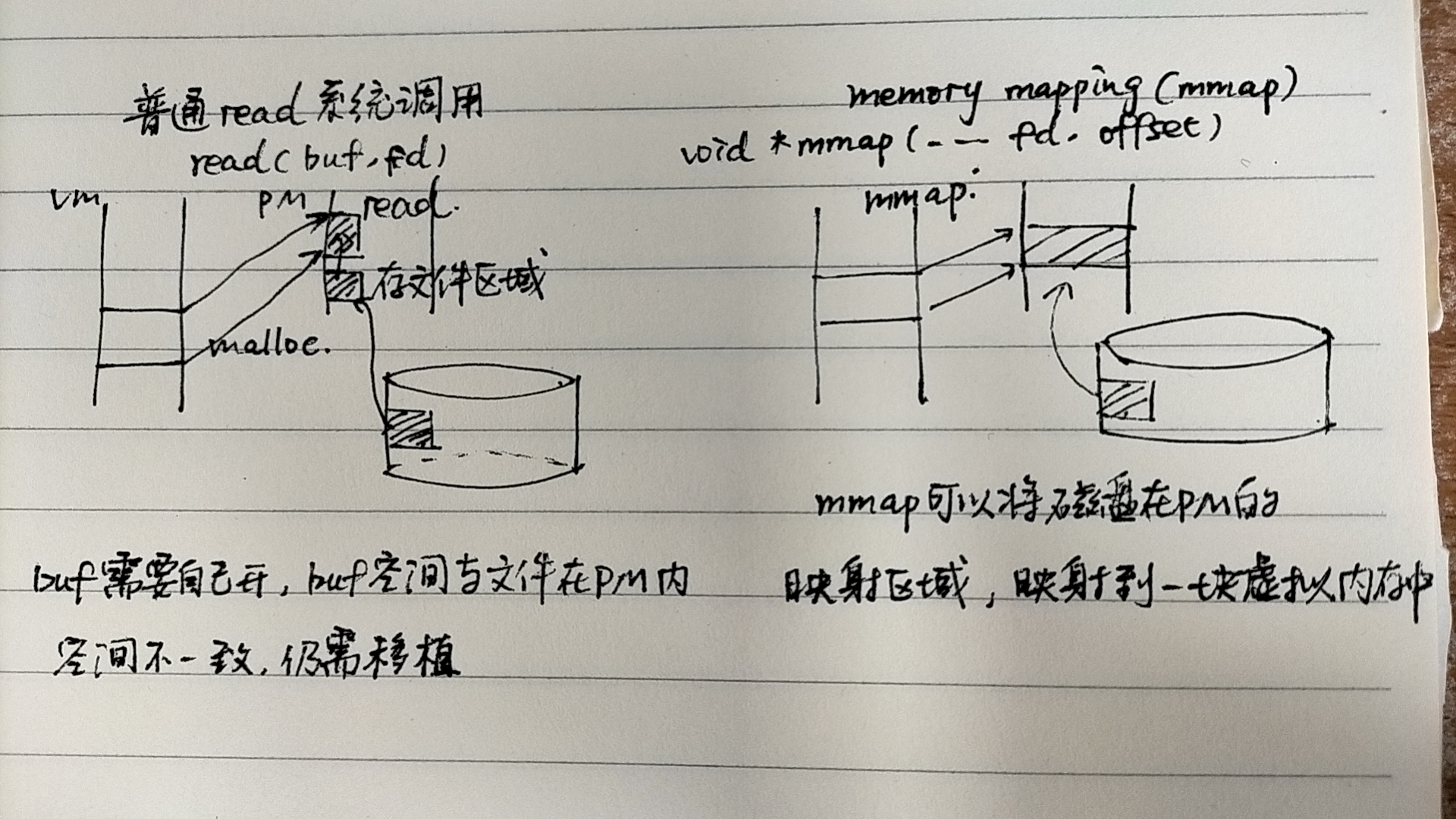
这块映射的空间也是由vm_area_struct来管辖的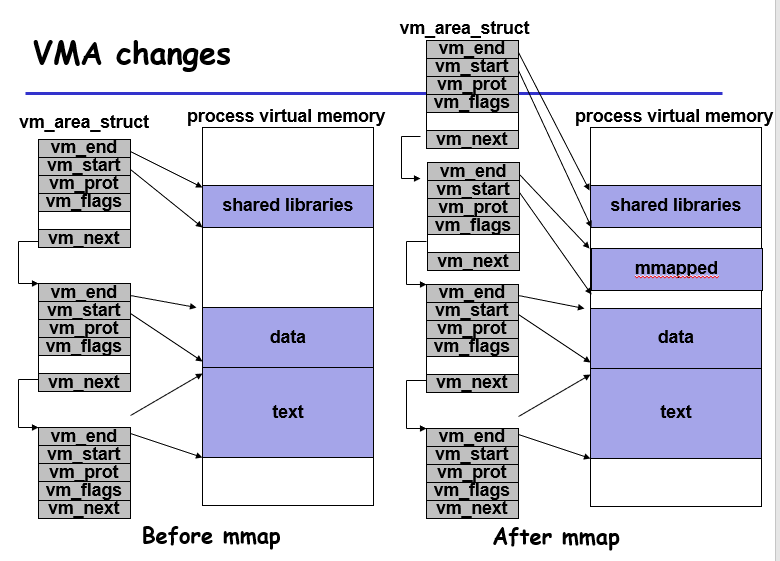
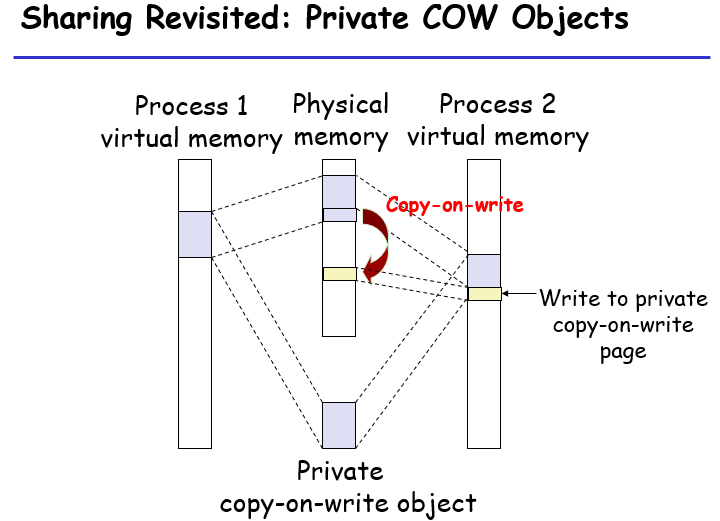
Fork()与Copy-On-Write
共享对象可以被多个进程共享,但是有些时候不希望因为共享的写导致程序执行不符合预期,所以对这类对象可以引入一个Copy on Write的标记:
- 标记这段空间为read only,同时加一个copy on write标记
- 去页表处查找,找到之后发现权限不对而且有cow标记
- 复制一份要写的空间的对应的页在PM,然后去写在拷贝的那一项
2-29 replacement
由于实际的物理内存大小有时候并不能满足所有虚拟内存的需要,所以会有swap out的机制,这个时候挑选合适的交换出去的物理页就很重要了,以下是一些策略:
random
first in first out
LRU/LF(frequently)U
关于FIFO策略,有一个值得关注的问题,叫做Belady’s Anomaly,即有些时候物理内存容量变大反而导致missing rate上升;而这个问题不会在LRU中出现,有一个叫做stack property的东西,就是“一个N+1元素的cache一定包含N元素cache的所有元素”,那么就可以保证物理内存页数量上升,未命中率严格不递减在随机的内存访问和替换的例子中,三者的区别不大,而random最节省资源,只需要出一个随机数就行,反而是最优解
80-20 workload,80%的引用只针对20%的空间,那么LRU表现较好
Looping Sequential,重复顺序地访问某些页,那么LRU和FIFO在物理页较小的时候命中率为0,较大的时候命中率为100%
如果严格地实现LRU,那么记录时间戳在物理硬件上不太现实,而且也显得耗费计算资源,所以计算机学者设计了一个阉割版的Clock Algorithm,具体的运行形式如下: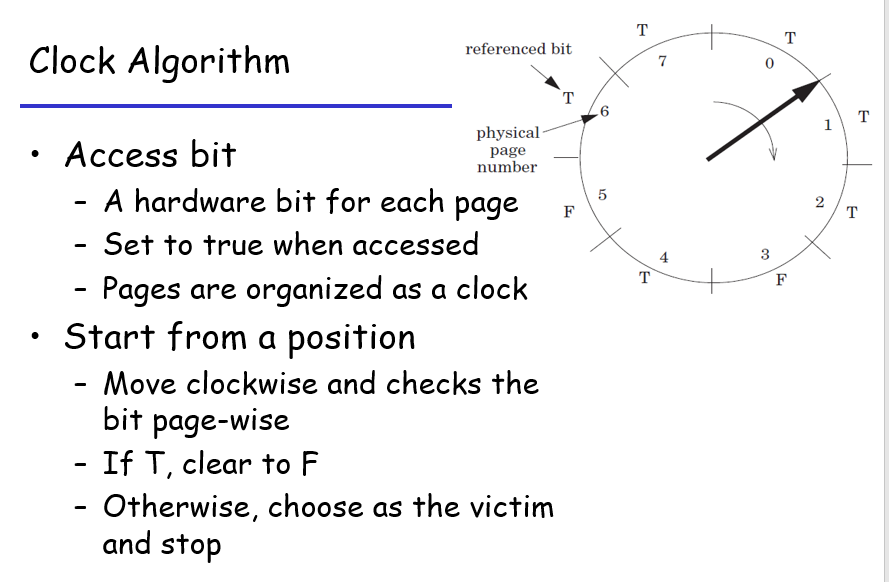
效果在80-20的测试集上也比较好


