计算机系统工程之:分布式文件系统
Weiquan Huang分布式文件系统用处广泛,比如网盘等常用应用就使用了这个系统
NFS with RPC
Network File System希望提供一个服务端无状态、客户端无磁盘的服务;它为客户端提供了一些fs api接口,客户端向服务端发送file handler(not fd!)
客户端将fd和fh关联,在服务端不需要维护fd状态
- 服务端若维护状态,维护的数量和与之连接的客户端数量成正比,内存负担较大
- 服务端若断电,客户端无感知,但是客户端已经无法通过本地维护的fd访问服务端的文件
- 无服务处理写操作有一定问题:因为可能会有retry请求的发生,这对于请求的幂等性需要做一定的规定,否则会导致一些奇怪的现象发生(比如at-most-once)

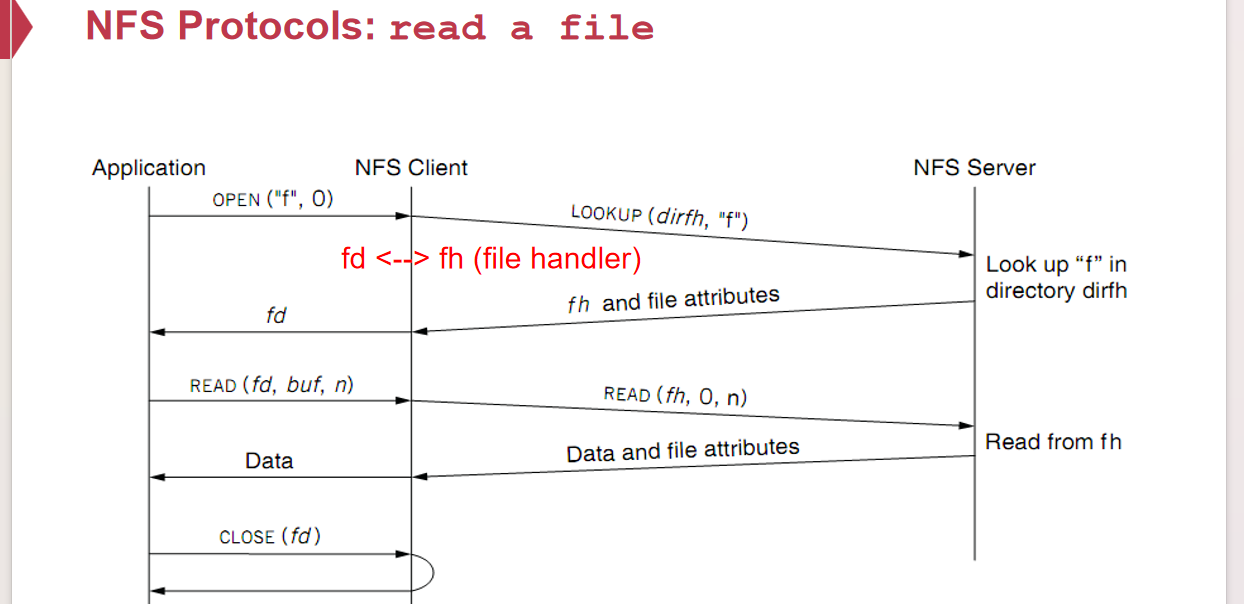
什么是file handler?客户端维护的访问远端文件系统的信息,但是又不仅仅使用/path/to/remote/file或者inode来标识
- 仅使用文件名会导致在客户端1访问文件两次的间隙,文件被改名并且别的文件顶替了该文件名,导致两次访问的文件不同
- 仅使用inode会导致在客户端1…,远端文件被删除,又被新建一个文件,那么这个inode肯定不是指向原来的文件
- 使用inode+generation number(GN的作用是每次inode更新了所对应的文件,就直接对其+1)
优化性能之缓存:缓存到远端服务器优化程度不大,缓存到本地存在缓存一致性问题,一般的做法是给本地的缓存附加一个mtime,首先缓存的文件定时向服务器请求更新,其次若访问文件,会获取远程的mtime并与之进行比较;更新文件一般在客户端发起close调用后会去更新
NFS最大的问题就是服务端单节点,十分不利于拓展硬盘、抗崩溃性差
Distributed NFS
- 远程服务器的集群有很多个硬盘,一个较大文件可以分别存储于多个硬盘,文件的
inode可以存储形如<mac, block_id>的信息 - 远程集群需要一个
master节点,存储全局的inode bitmapblock bitmaproot inodesuper blockinode table等 - 查文件也就是简单的依据目录路径之类的去查找(或者上面讲的inode+gn),存储文件的形式和单机差不多,就是寻找另一个block的时候需要一个
mac地址而已
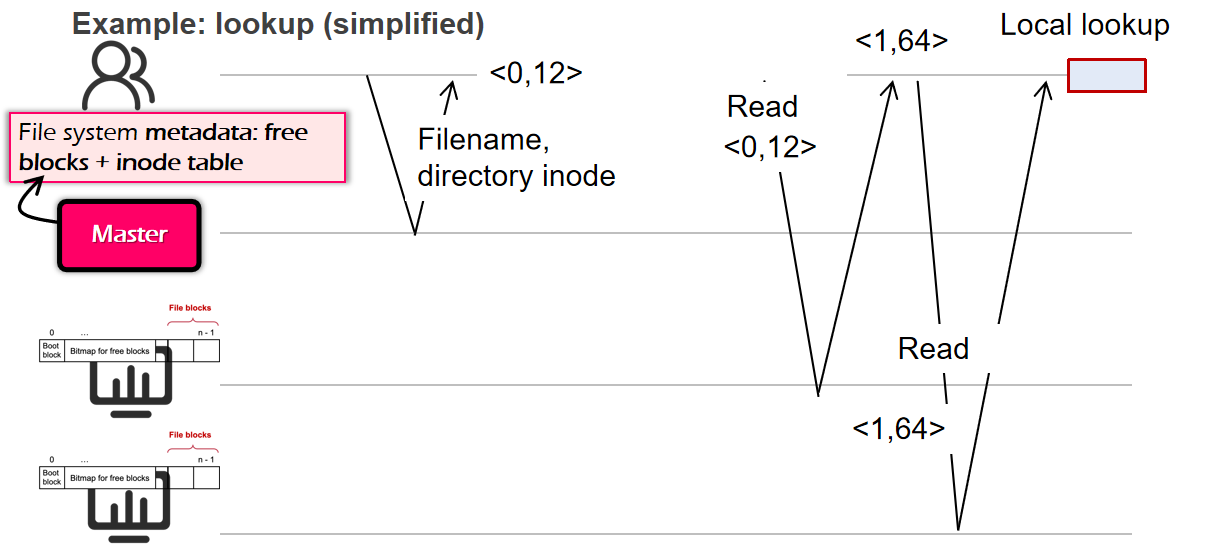
磁盘拓展性具备了,但是由于主节点、文件都没有备用,稳定性仍然有问题
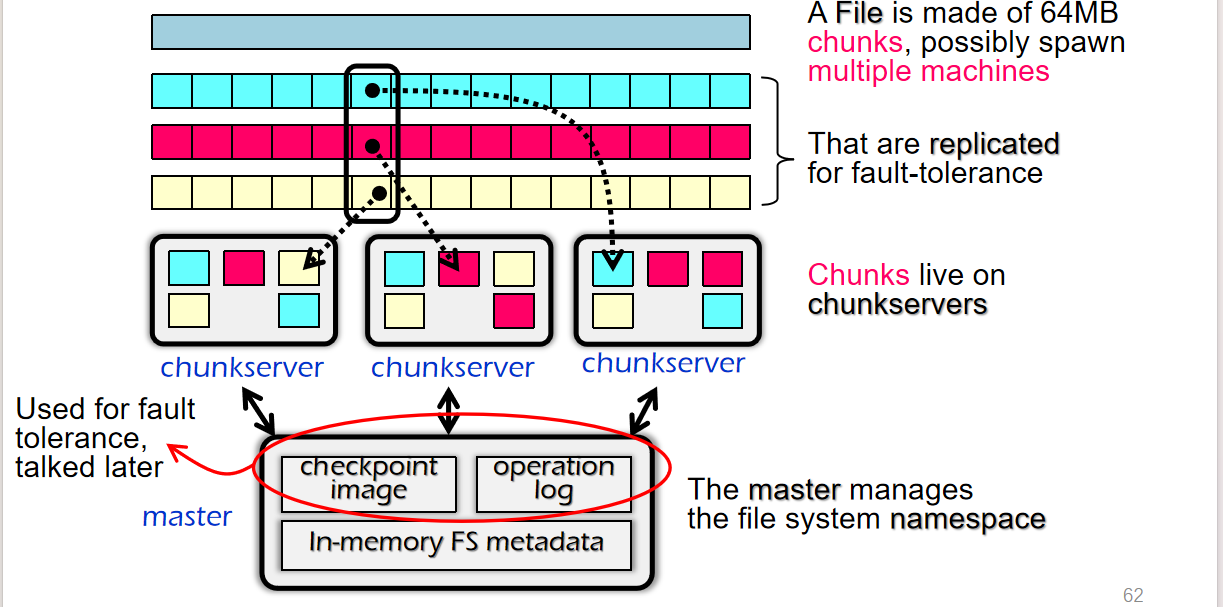
GFS
Google File System是谷歌公司设计的分布式文件系统架构,其根据自己的应用场景舍弃了部分性质
- 绝大部分文件
append而非复写(给web项目添加新页面) - 绝大部分请求是
read而非write,意味着可以使用pre-fetch等策略,或者缓存热页面 - 对一份文件的某个
chuck有多个备份,分别备份在不同的服务器上 - 一个
chuck是很大的,因为Google考虑到如果一个文件的chuck太小,意味着数量多,那么网络传输次数就上升了,因此倒不如减少数量;同时由于master和chuck server需要连接来进行访问,因此不如减少建立连接的次数;这对于append也是有利的 - GFS并不保证每次用户看到的都是最新的数据,但是最后会更新
- 只用一个
master会不会导致稳定性问题?实际上master存储的索引数据来源于chuck node,停机后重启,重新发个请求去拿就行了,也不需要自己持久化到磁盘上;或者就通过operation log的方式将一些信息存档在磁盘上
数据一致性: - 如果两个写操作同时到达分布式文件系统,且他们对不同的
chuckNode进行操作,那么会导致不同的chuckNode有不同的数据 - 需要一个节点作为对每次写操作的排队,如果都交给
master管理,那么会导致负担过重 - 一般由
master去选择存有某个文件的若干个chucknode的某个节点为primary node,作为为这个文件写操作的排队处理节点,这个节点是轮流的 - 一个写操作携带着数据进来,先将数据传送给某一个
chuck server,再由这个chuck server转发给另一个chuck server而不是广播;因为对于同一个主机来说,带宽是指能够从网卡中送多少数据到链路上,广播的话,时间就是数据份数的倍数;而如果是链式的传播,带宽就不是个瓶颈,因为一个主机只需要传送一份文件,而链路的传播速度更快 - 随后,当客户端收到每个备份节点的ACK后(实际上达到一定数量的备份节点就可以了),给
primary发送一个写请求,primary node将数据的写顺序广播给各个chuck server;当每个节点给primary发送ACK,就说明按照写顺序的写已经完毕了(这里用广播的原因是本身发出写请求顺序的数据量本身就不是很大) - 关于这里第二步,虽然他是同时地将很多个对该文件的读写到不同的chuck node,但是对于client来说,其判定自己能不能发送写请求的是根据自己本身的请求ACK到达了给定标准之后就可以发送了;再由
primary对这些写请求进行打包排序,广播出去 - GFS的文件系统没有目录,只有文件名