计算机系统工程之:键值存储系统
Weiquan HuangLSM Tree
对文件的增删改查通过
append进行,因为文件顺序读取远快于随机读取(点查询)在内存中需要有一个index用来存储
byte offset,来标记key对应的位置,这本质上也是一个内存的KV;可以通过布谷鸟哈希来实现:优点,GET很快;缺点:INSERT可能会不成功,以及假设有大量的数据(导致触发了多次死循环等),需要扩容,扩容不仅要重新分配内存,还要重新设置哈希函数,重新将数据塞进去append操作会导致文件无限扩充,对于冗余数据(比如键值存储中已经过时的键值对),需要进行淘汰旧值的compaction,类似于LSM的操作垃圾回收:将空值(表示被删除)在重新进入内存的时候进行垃圾回收
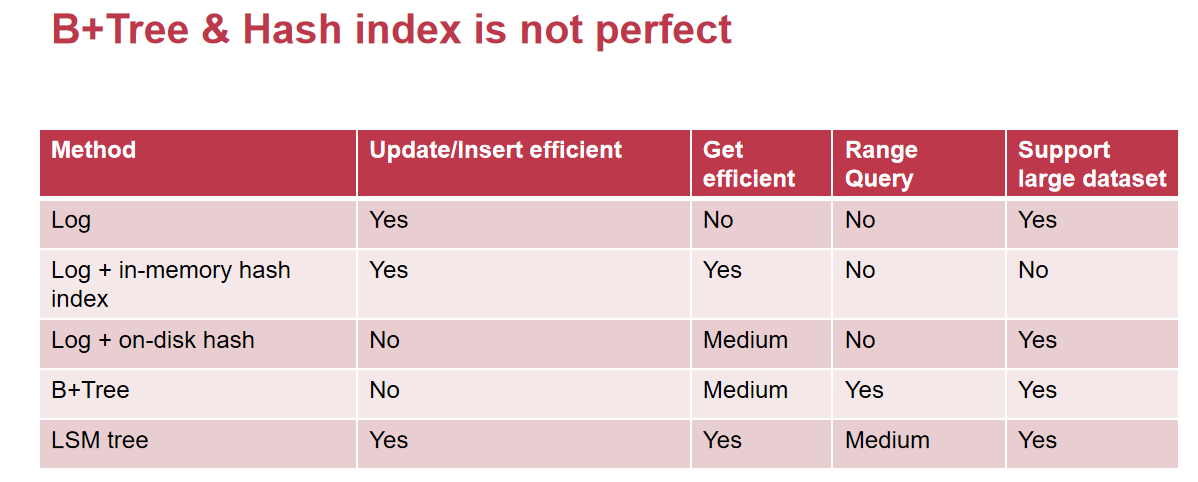
B+Tree不适合insertion-intensive类型的存储情景
分层存储SSTable:除了L0层以外其余层都根据键值对的顺序和时间戳进行了排序(优先以时间戳),这样是方便于对于一个key的查找,在假设时间戳一致的情况下,对于同一层的SSTable,只需要查找一个,其余的不需要查找(因为范围已经对不上了)
崩溃恢复:redo log,没有持久化之前先把自己写在内存的内容,通过log的方式写入到持久层中;重新启动后如果发现有需要修复的功能,再将log的内容写入内存

write stall:写入一个键值对的时候因为compaction而在单个操作上耗费了大量的时间,从原理上很难避免,只能加速compaction的过程
对于不存在的key,读取时间略长,必须确认所有的SSTable都没有这个key才能返回
Consistency Model
为保持一致性,有两种可行策略:
- 将对信息的读取、写入请求全部发送给中央数据服务点,虽然一致性可以保持,但是性能显著下降(需要等待server的ACK、单点负载大)
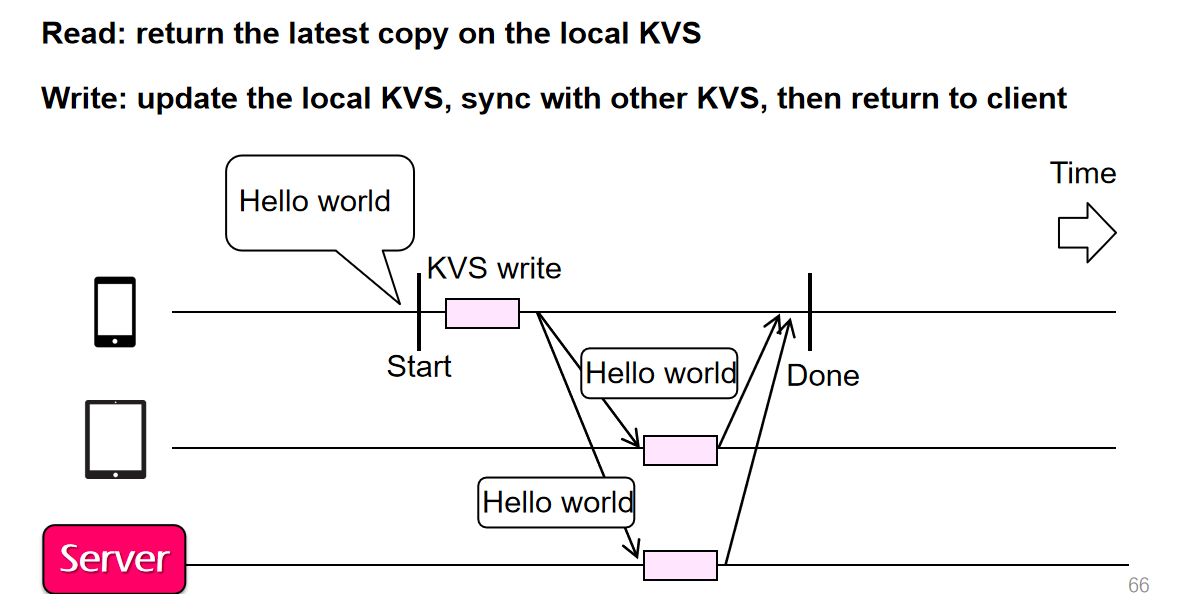
- 在自己的应用内置KVS读取信息,写信息的时候在本地KVS、对方端KVS、server进行写入
- 分为wait sync和sync but not wait两种,sync意味着需要等待接受请求端的ACK后才能确认自己有没有完成发送,否则重发或者提示发送失败
- sync but not wait意味着信息在本地完成发送的时候会同时发送给远端,但是在本地完成更新之后就直接认为信息已经发送成功,由于这对于远端的失败并没有感知,因此这种方式会在特殊的场景下引发不小的麻烦
- 分为wait sync和sync but not wait两种,sync意味着需要等待接受请求端的ACK后才能确认自己有没有完成发送,否则重发或者提示发送失败
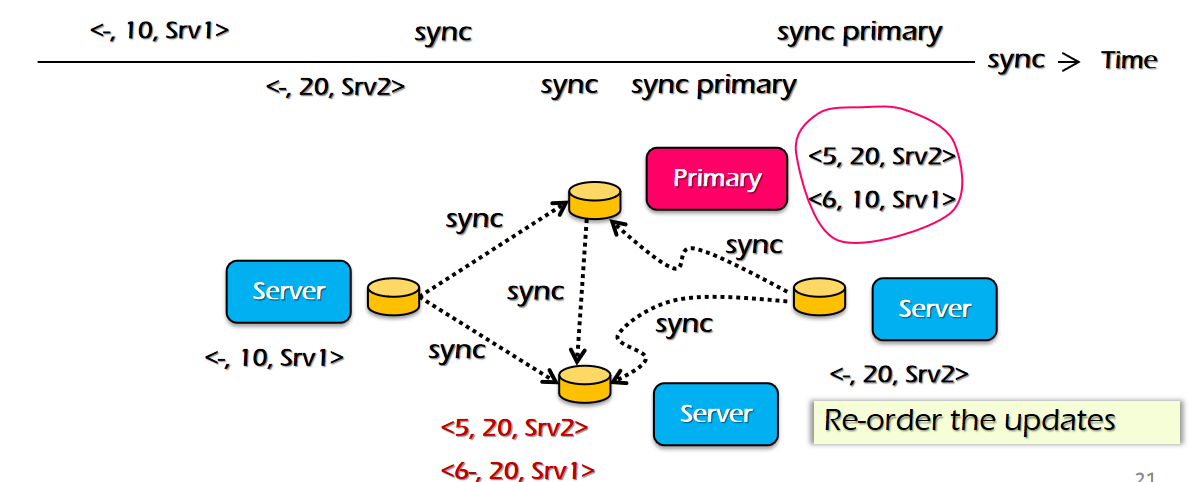
分布式应用存储的请求先后顺序问题十分类似于并发线程的任务执行顺序问题,各种顺序千奇百怪,只能保证自己一方发出的请求顺序相对一致;这时就需要提出一些模型来规范一下在服务端接收到不同的请求的时候如何调控他们的顺序
- strict consistency:用全局的请求发起时间来规定各个请求在服务器端被处理的顺序,显然这是异想天开
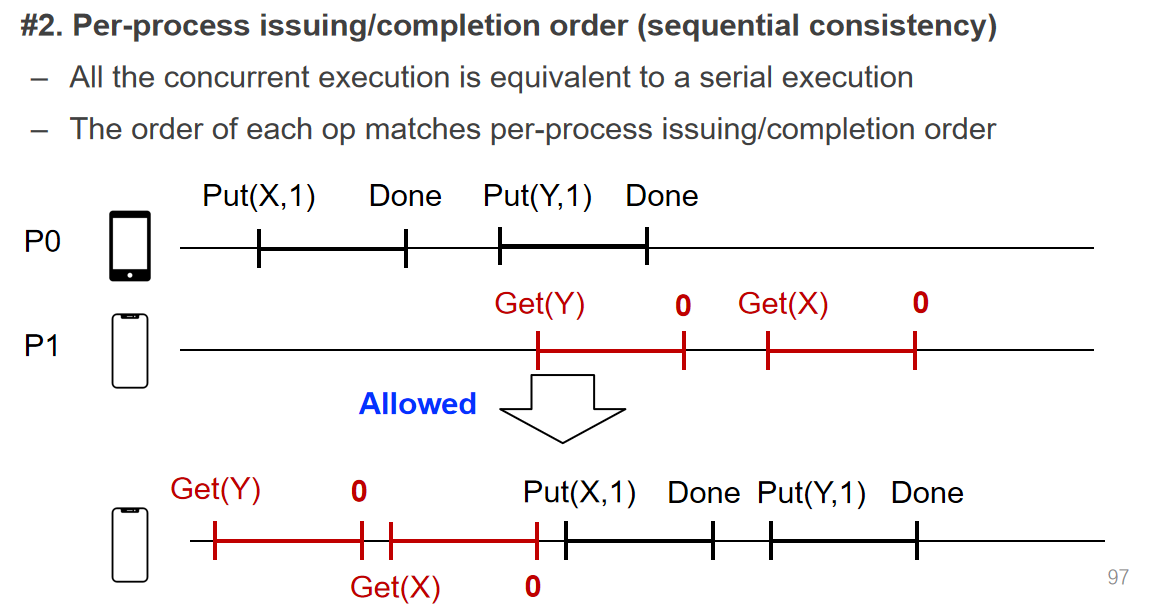
- sequential consistency:保证单个客户端发送的一系列请求是顺序连续执行的,而这些一系列请求的顺序不保证符合实际期望
- linearizability consistency:为每个请求添加一个全局时间戳,记录事务的起始时间和完成时间,限制事务的执行必须是某些事务的起始时间落后于其他事务的完成时间的时候会进行顺序调整(可能还有一些版本号机制,算法机制Raft等),图示的这种排队机制很像计网的TCP ACK机制
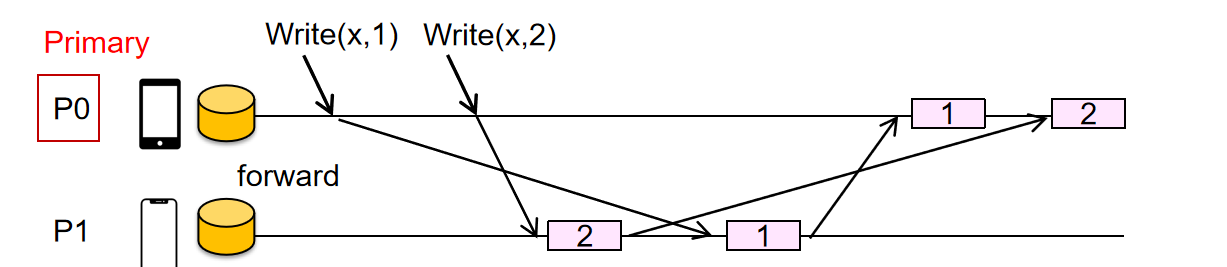
Eventual Consistency
实现Linearizability:需要将写操作先经过primary节点进行排序,然后将写请求广播给每一个相关节点,他们完成了写操作后,primary本地自己再写,随后给客户端Done响应;读操作无论如何都需要经过primary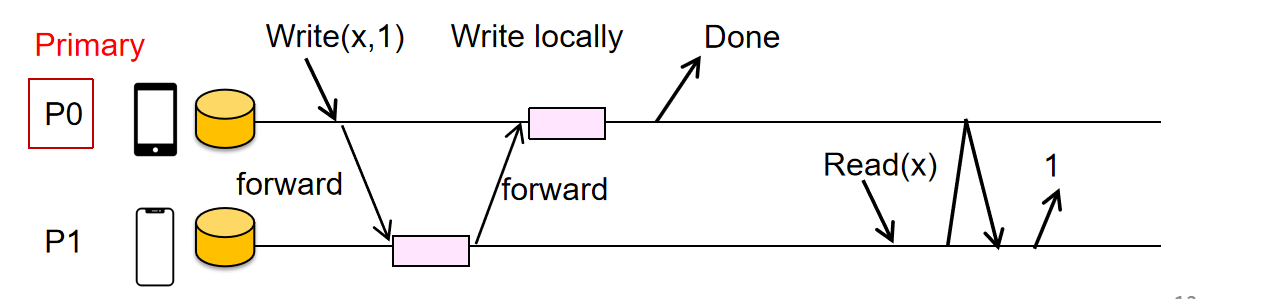
缺点:Read多了“额外”的RTT,但是为了Linear的性质不被破坏,不能在本地Read,下面的例子破坏了Linear性质,因为Read-2在顺序上一定是发生在Read-1之后的,但是在这里Read-2读取到的值却是比较旧的值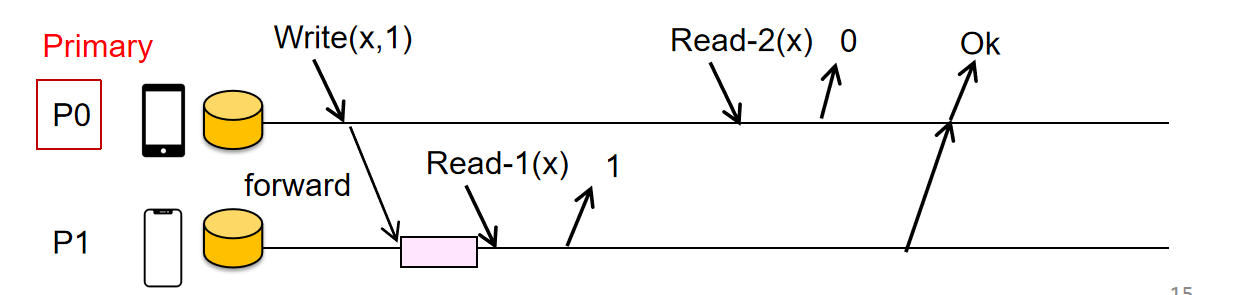
在这种设计中,单primary节点可能是一个性能瓶颈,因此可以借鉴之前的思路,为不同的数据设置不同的primary,分担其功能
Eventual Consistency事实上是为了性能去牺牲一致性的设计
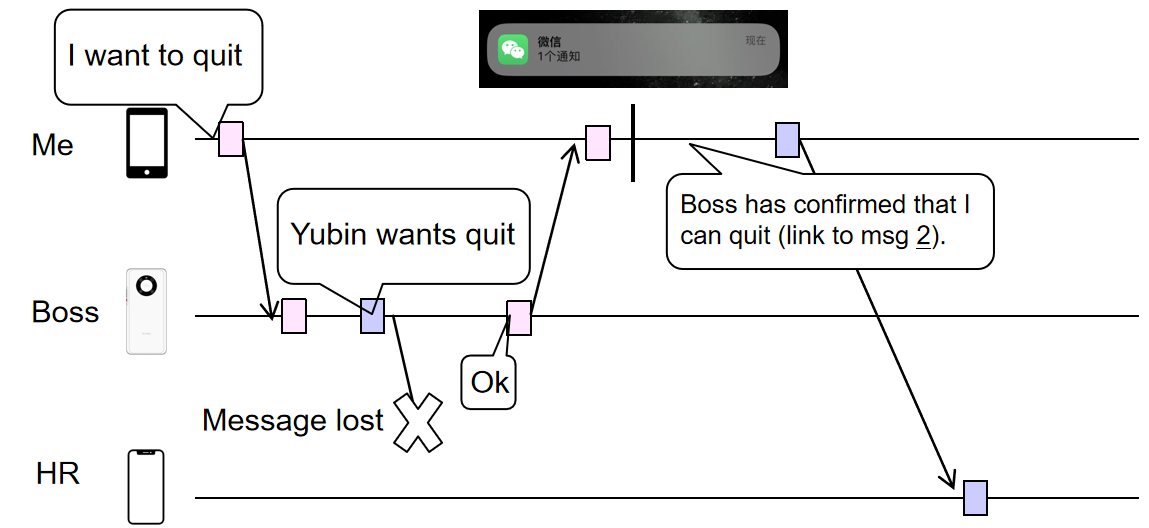
- 首先,对于聊天软件,不建议使用KVStore的
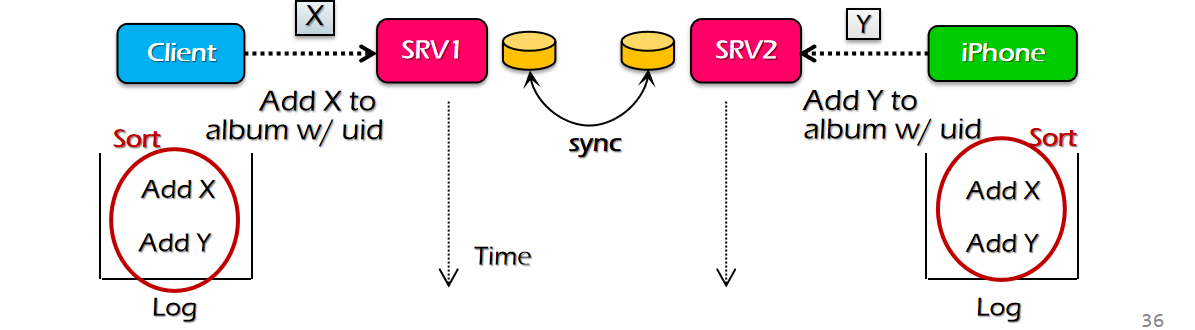
put更新方式,他的需求是append,如果两个请求同时刷进了存储系统,可能会把其中一个更新给刷掉,而不是两个都保留(因为put可能是把新的消息给添加到原来值的末尾) - 为保证两个时间相近请求在每个存档存储节点中都保持一样的数据顺序(而非各自为政),初步的想法是添加一个
log,写请求进入服务器系统后,先不持久化,而是暂时存下来,发送到对端的设备中;对话的两端在接收到彼此的信息之后,根据<Time, node_Id>来进行排序,排好序之后向服务器系统发出写请求的执行顺序,如此一来顺序在每个机器上就都是统一的了 - 对log进行排序,Time是第一优先级的排序参照位,但是每台机器的物理时间其实是不太一样的,有的机器可能时间根本就是坏的!这就会导致一定的不符合逻辑的问题,比如机器A的物理时间在同一时刻落后机器B两个小时,那么机器A看到了机器B的
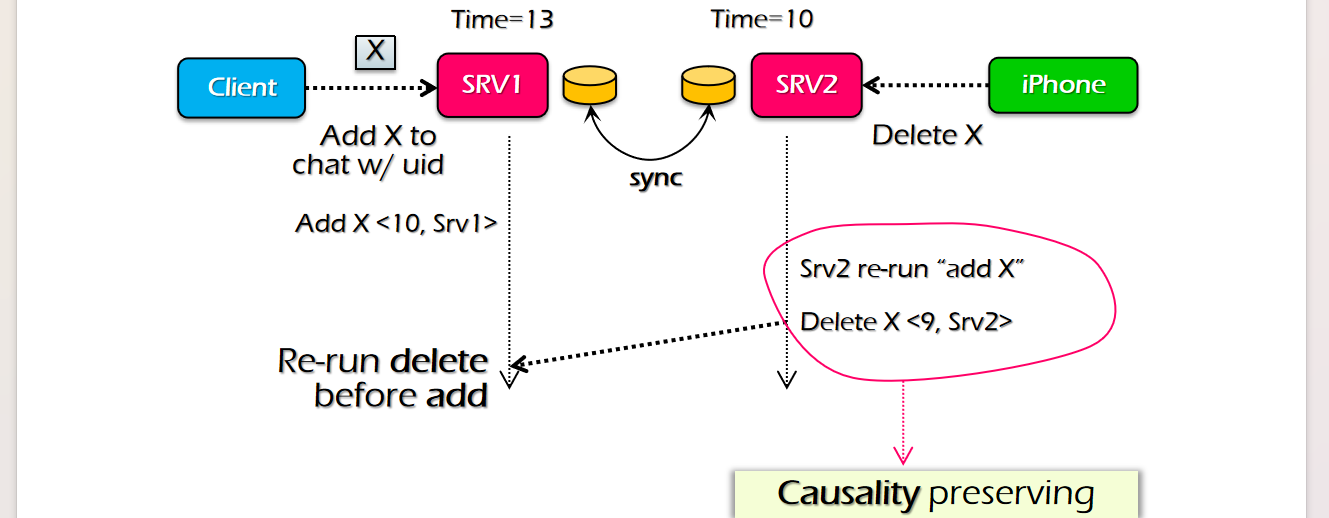
add X请求之后,希望发出delete X请求,但是在log排序的时候就会认为delete X在add X之前! - 此时就要引入一个叫做Lamport Clock的东西,具体做法是,一个请求从别的机器传过来的时候会携带一个$T_1$,而收到请求的机器会根据$T_2=max{T_2, T_1+1}$的规律来进行更新,这样子就确保了上面的情况不会发生,至少不会出现另一台机器发来的请求超出了本机器的时间;不过他也没法解决执行逻辑不符合预期逻辑的情况
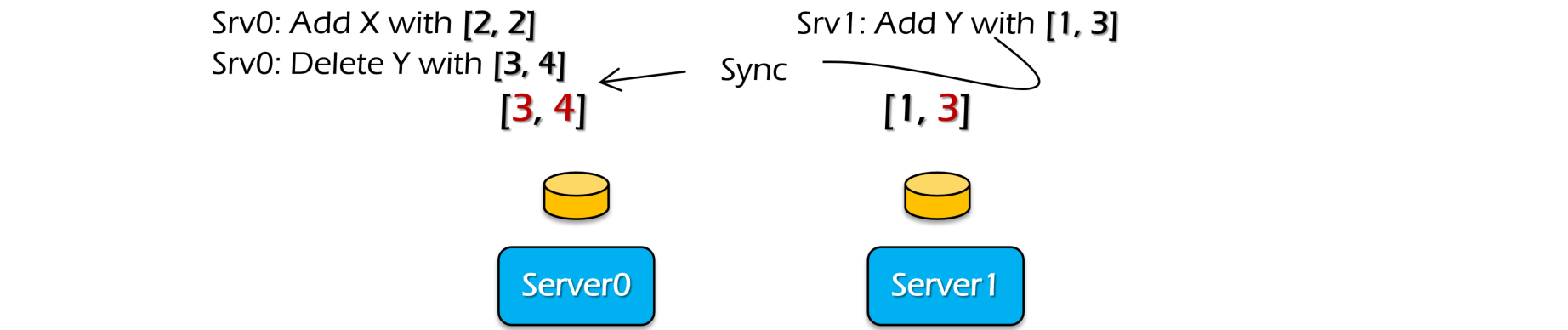
- 对于每个节点发来的请求的时间戳,可以使用一个vector clock来维护,包含了每个node的时间戳(当然包括自己的,比如node0自己的时间戳就维护在
idx[0]处),每次物理时钟会在一秒后将自己的clock timestamp更新,而当其他node发送了同步的请求之后,就会使用$T_i=max{T_i’ + 1,T_i}$来更新值,这样子就可以对每个节点分开排序;不过vector clock的维护成本太高了,一般是使用Lamport居多 - 在该系统中,希望建立一套机制,实现log的定期持久化;能够持久化的log,都需要是log上记录的物理时间小于评判标准物理时间的(比如vector clock的评判标准就是vector中的最小的项)这里的问题是如果某个节点挂了,那么这个节点对应的clock number就会成为定值,意味着vector中最小的项已经没有增长了;最后提了一嘴CSN(Commit-Seq-No),全局提交顺序号,且听下回分解

CSN
上节课的几个问题
- 机器时钟和物理时间无关
- 并不是必须的
- 假设e1在TS(1)发生,同步给e2之后node2为TS(15),那么其实e1,e2时间并无联系,e2仍然可以早于e1
- 只能说Lamport方法避免了早发生但是机器时间比较大的时间被认定为比另一个晚发生但是机器时间小的时间的发生顺序误判而已
CSN(Commit-Seq-No)是服务器对primary提交事件后,primary将这个事件赋予一个全局时间标记CSN,这样就可以在整个体系中对这些事件的持久化顺序做根于CSN的排序了;其中无关联的两个事件先后到达primary问题不大,而如果有明确事件关联的事件,则是由调用链的最后一层server来讲所有时间根据调用链先后顺序来统一提交,并形成基于调用链顺序的每个事件的CSN