计算机系统工程之:事务与分布式事务
Weiquan HuangConsistency under single-node faults
这里举了一个例子其实就是讲事务,如何保证一串操作的原子性,由银行转账问题来引出原子性问题,因为这对于单机来说已经不是通过设计一致性策略能够修复的了,需要针对单机来进行事务处理策略的设计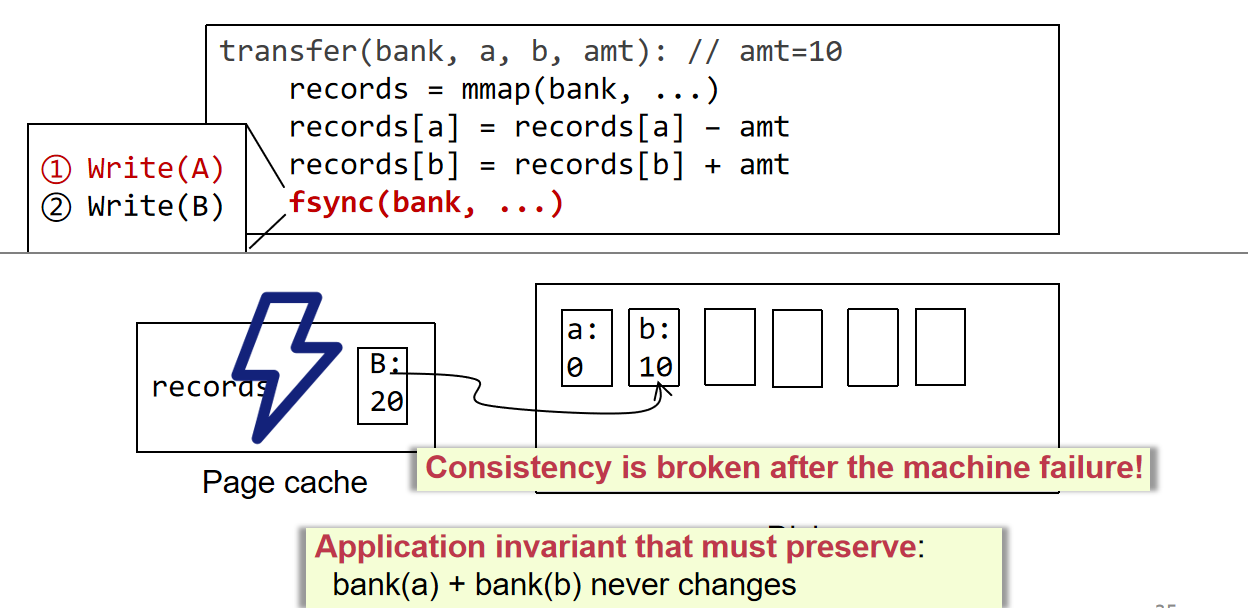
- shadow copy:将需要写的文件拷贝一份,写的时候写在临时拷贝文件中,最后将文件改名(指针指向修改完的文件);如果在
fcopyfsync处出问题不会影响原子性,如果在rename处出问题则可以先将rename需要做得持久化操作先保存到磁盘上(称为journal),随后假设record未执行完全则可以通过journal来恢复,而本身如果在磁盘执行的时候断电,则可以给磁盘添加一些电子元件,让其能够在一定时间内保持继续写入数据的电力 shadow copy对付大型文件的性能不太行,比较适合修改元数据;而且对于多线程请求,shadow copy首先不能针对两个同时写同一个文件的请求去各自copy一份,因为这样显然会造成复写,但是有可能一个线程写完了之后他直接
shadow copy对付大型文件的性能不太行,比较适合修改元数据;而且对于多线程请求,shadow copy首先不能针对两个同时写同一个文件的请求去各自copy一份,因为这样显然会造成复写,但是有可能一个线程写完了之后他直接rename了,那么其他线程可能还没更新完毕,假设其他线程在重新更新的之前宕机了,那就寄了;而且shadow copy对于disk io不频繁,比较浪费磁盘带宽(可以频繁异步写磁盘) - log:每次开始一个事务的时候往磁盘log添加
begin,完成一个事务则在持久化之前添加commit,如此则可以在意外宕机的时候去执行那些committed的事务,并且撤销那些uncommitted的事务- 仅redo log的缺陷:磁盘io不频繁,因为只能持久化那些确实已经完成的事务的commit日志;事务未完成的时候状态不能从内存清空,即使有些状态已经不再被程序使用,因为尚未持久化
- log结构:根据TX来进行分块链接,redo-undo的扫描顺序是先倒序扫描日志来undo,再顺序扫描日志来redo

 shadow copy对付大型文件的性能不太行,比较适合修改元数据;而且对于多线程请求,shadow copy首先不能针对两个同时写同一个文件的请求去各自copy一份,因为这样显然会造成复写,但是有可能一个线程写完了之后他直接
shadow copy对付大型文件的性能不太行,比较适合修改元数据;而且对于多线程请求,shadow copy首先不能针对两个同时写同一个文件的请求去各自copy一份,因为这样显然会造成复写,但是有可能一个线程写完了之后他直接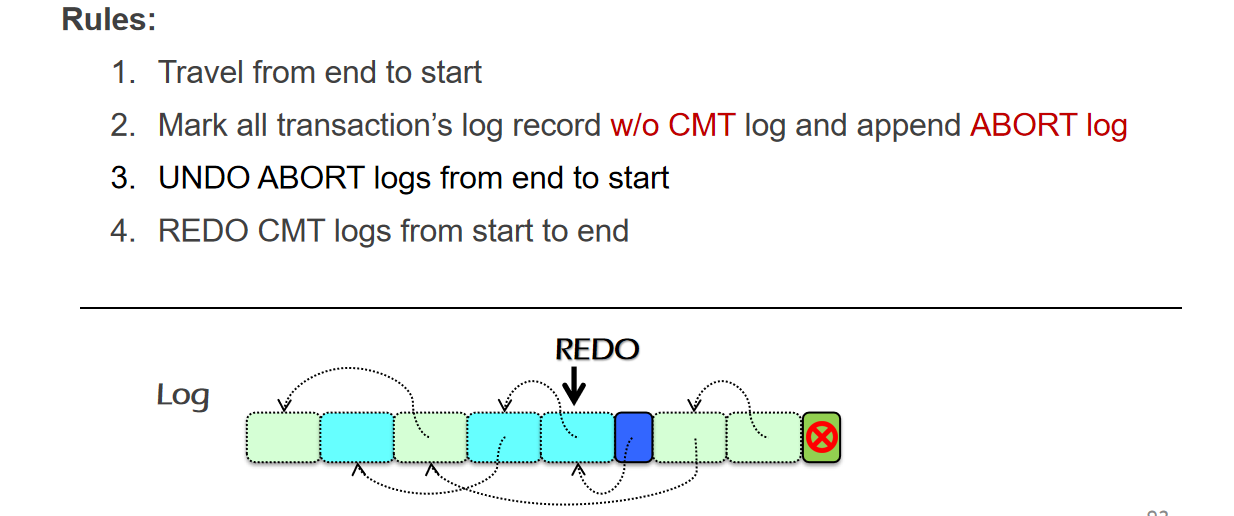
checkpoint
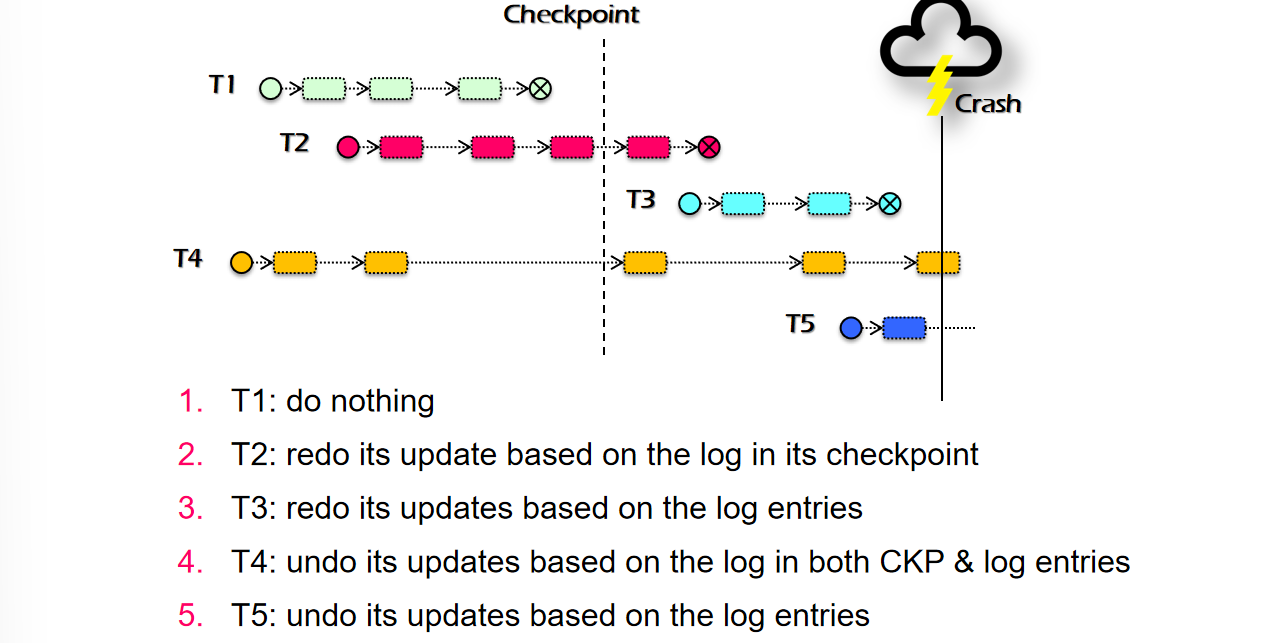
如果任由log无限尾部追加,那么磁盘迟早有一天会被占满,这里需要引入一个checkpoint的机制,这样可以在checkpoint之前的位置先把能够确定已经commit的记录给删掉
- 在checkpoint之前需要先等待所有已经进行的disk action执行完毕之后(注意这里可以在TX执行完成之前)进行checkpoint,期间会阻塞所有的coming disk actions,保证checkpoint如实记录在其之前的状态
- checkpoint的方式是在log处添加一个checkpoint tag
- checkpoint步骤完成后会将每个TX涉及的page cache全部持久化
- 每个TX会分阶段将自己的持久化操作写到page cache里,同时会将log写入磁盘,但是在checkpoint之前有可能会出现page evict的操作,就有可能会持久化的(如T2需要redo的原因是CKPT后的数据不一定持久化了,T2只需要redo CKPT之后的内容,而T4需要undo的原因也是这个)
- undo-redo vs. redo-only:redo-only对磁盘的带宽利用率差
- undo-redo vs. undo-only:undo-only相当于FORCE,每次事务完成都要立即持久化,比较耗时,不过恢复时间会比redo-undo快
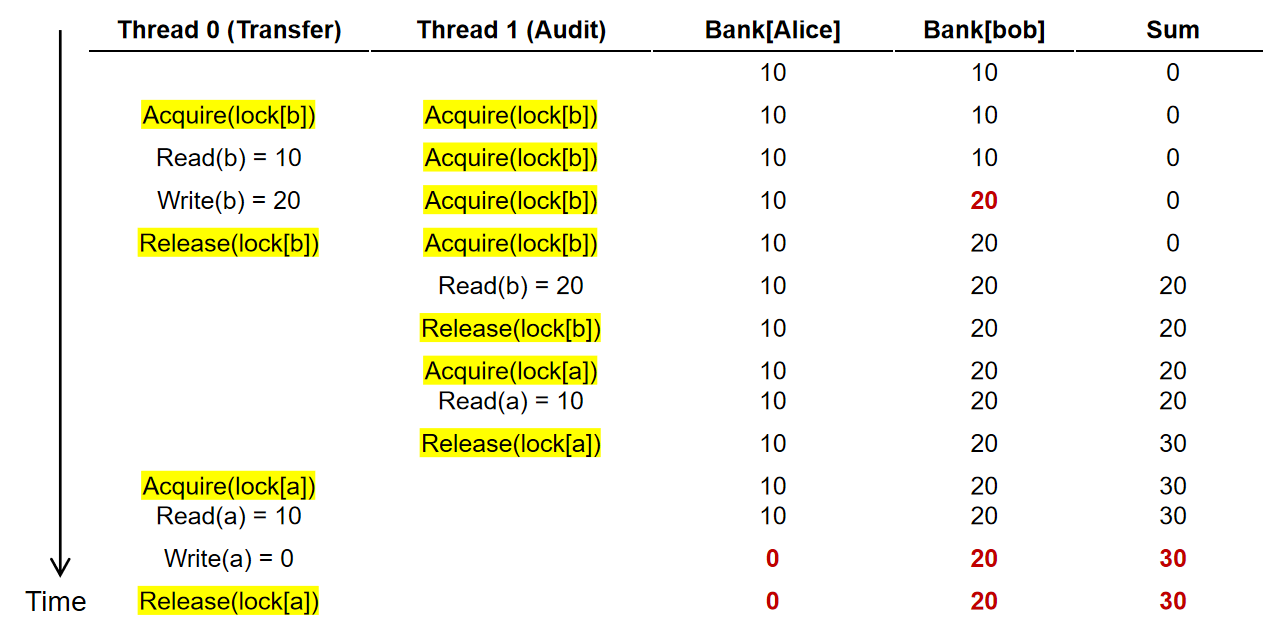
Before-or-after atomic
BOA原子性要求要遵守事务和事务之间是线性执行的效果,事务和事务之间不能有穿插“并行”的现象发生;这种类并行问题比较难用调试方式解决,因为其出现的偶然性,以及为调试所做的额外工作也可能对其出现的概率产生影响,因此会造成Heisenbugs(具有不确定性的东西在限定一定条件后,会塌缩到一定的非原来的状态)
简单的思路是加锁:
- 粗粒度锁:对每个disk io操作加锁,虽然严格保证了BOA原子性,但是性能极低
- 细粒度锁:对特定数据的disk io加特定数据的锁(说实话可能在实际的db中估计就对一个node,或者page加锁),虽然保证了性能,以及对单TX的原子性,但是假设某个变量在TX未结束的时候释放锁,那么当其他TX读取数据的时候会读取到该TX未完成的中间数据,可能会导致一些数据比对/统计的任务比较难完成
- 一次性把所有要访问变量的锁都加上?你怎么知道要访问哪些变量
- 2PL(Two-Phase Locking):对访问到的数据先上锁,最后统一解锁,这样就避免事务刚开始的时候不清楚谁需要加锁的问题
- 锁的payload:主要在于维护锁需要的内存开销
Serializability
如果将TX1, TX2, TX3, …, TXn并行执行,实际顺序能够达到和事务BOA原子执行的要求一致且顺序也一致的结果,那么称为这个顺序为Serializability
- Final-state Serializability:并行最终结果符合预期
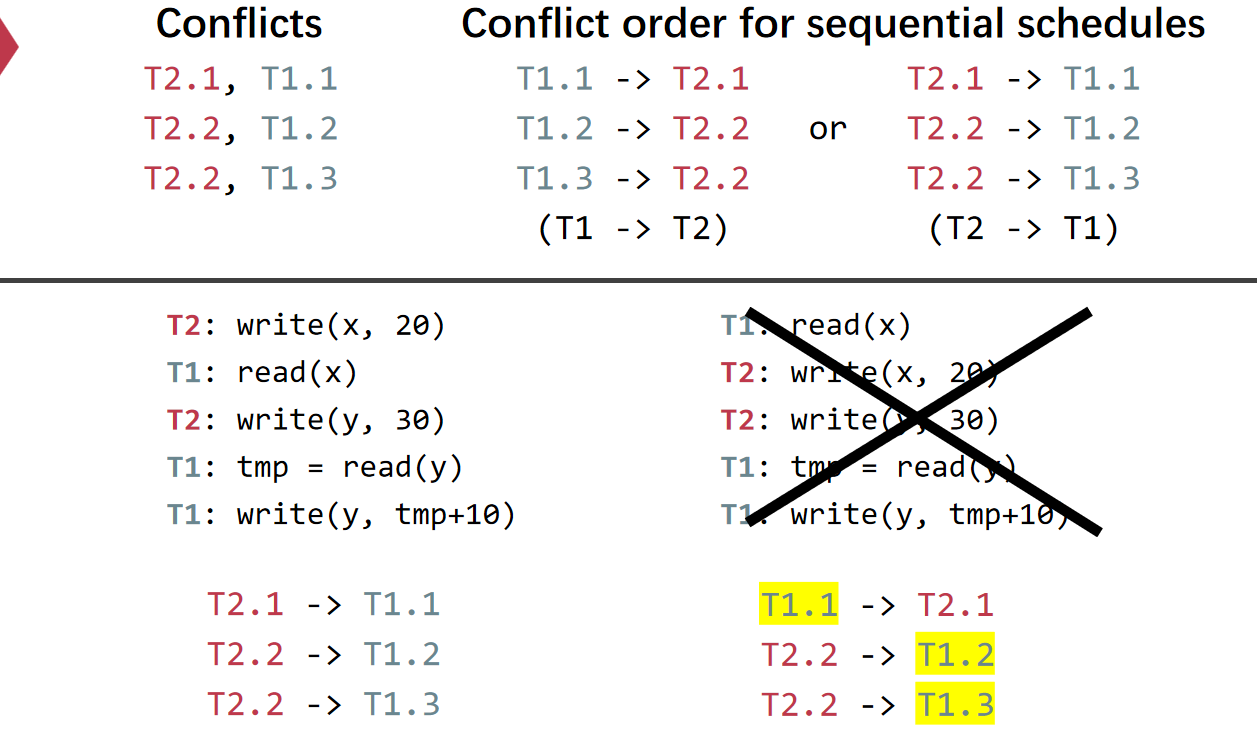
- Conflict Serializability:
- 认定为Conflict的条件
- 定义
- Conflict Graph:对一个TX和另一个TX,存在若干个彼此具有Conflict关系的小步骤,出现TX1一个小步骤在TX2另一个预期具有矛盾关系的小步骤前面则认为TX1->TX2,如果整个流程无环且顺序正确则认为满足Conflict Serializability
- 认定为Conflict的条件
- View Serializability:不一定满足Conflict,但是能够保证每个中间过程的read和write的结果和串行是一样的


2PL discussion
证明2PL方法能够在 非corner情况下 保证Conflict Serial. 使用反证法,首先假设不满足C. S. ,那么整个Graph里面就有环,两个TX有冲突当且仅当他们访问了相同的数据而且至少有一个是写,因此可以对Ti做如下假设,可以发现对T1的锁策略并不符合2PL的要求,因此出现矛盾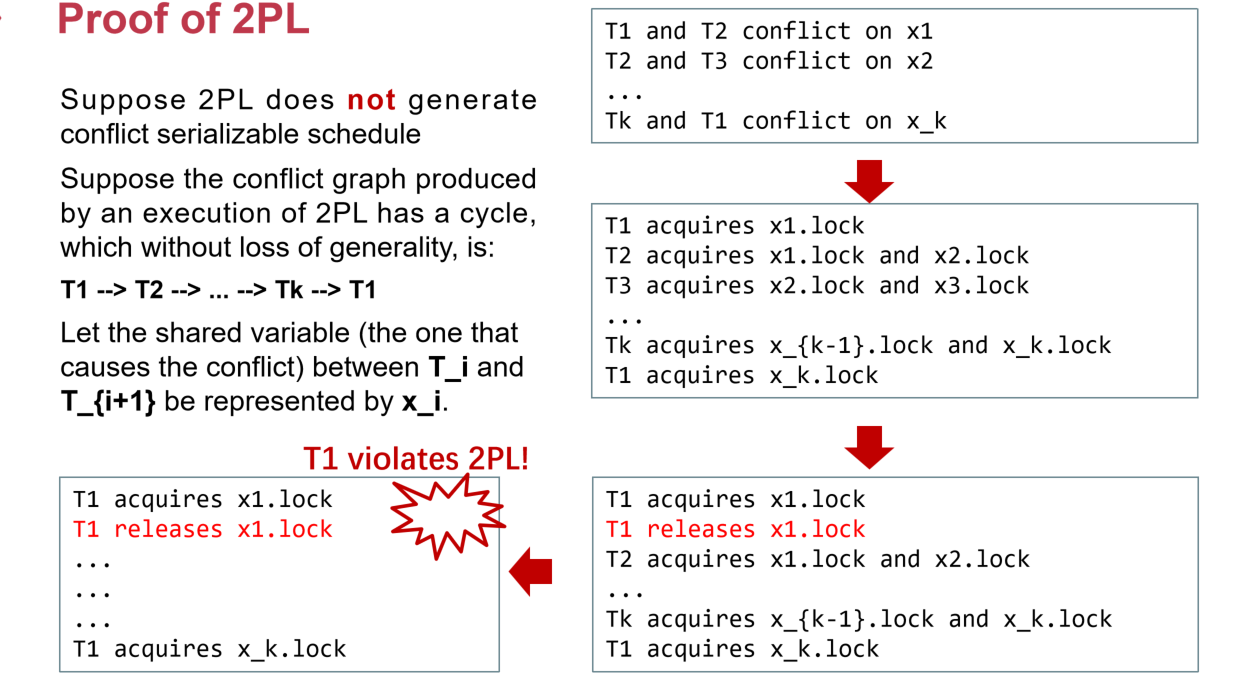
存在corner case使得2PL无法保证Conflict S.——幻读(Phantom Problem)
下面的例子中T1在update阶段只能给H R加锁,在这期间可以穿插T2的insertX Y,随后再进行T1的print H R X Y,相当于单个事务两次读取相同的数据时出现了先后不一致的读取(后一次比前一次多读/少读了内容)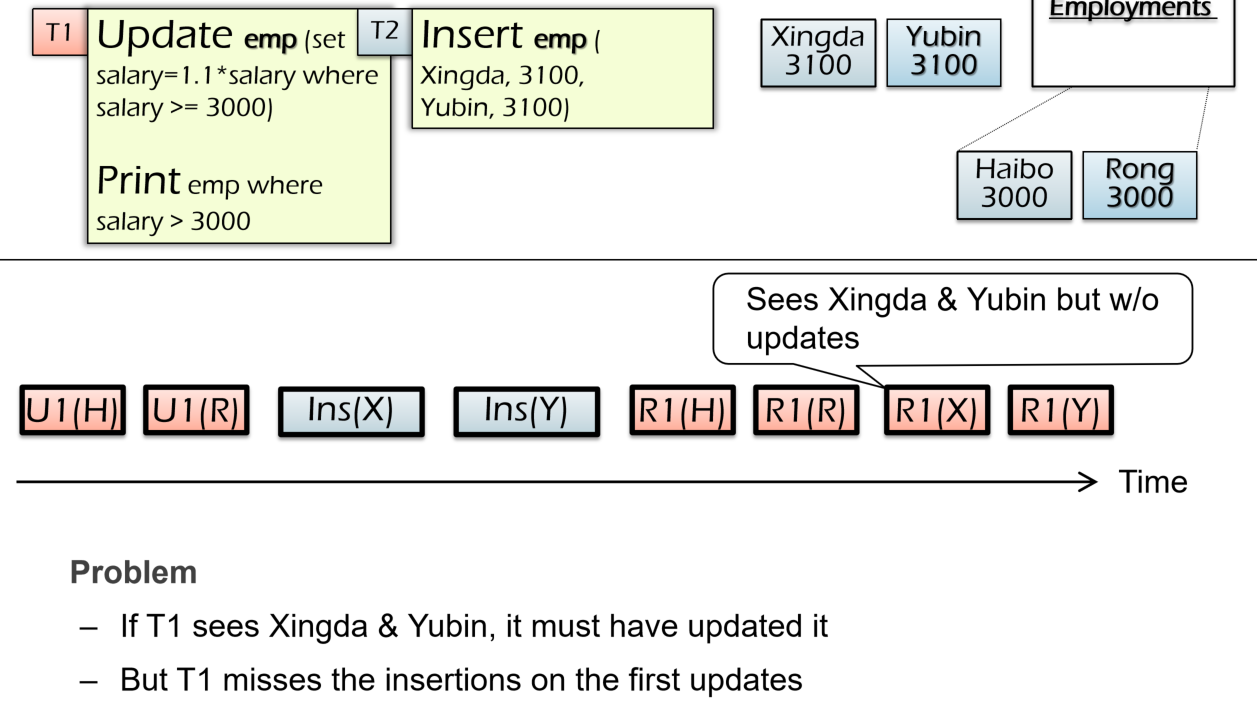
Deadlock死锁:
可能的解决策略:
- pre-defined getting order:提前定义拿锁的顺序,不切实际
- detect deadlock by conflict graph(cycle):这个还算能实现,但是性能不好,检测的时候只能是单线程
- heuristics:发现超时直接callback,可能会误报
Optimistic concurrency control
- 第一阶段:将读到的数据和写的数据分别写到读/写集合(写操作暂时不持久化),为了避免ABA问题(在T1执行过程中,T2拿到执行权,将某个在T1中的数据修改后又改回原值,导致T1无法发现这个值被改过),一般需要加上版本号
- 评估集合,是否满足Serial.
- 满足可以提交,不满足则会被终止(此时写操作持久化)
这里有一个需要注意的点,即P2/P3需要一起执行,否则可能出现P2判定为可提交之后,提交之前数据被别的线程修改的情况,给P2/P3统一加锁的方案有

- 加全局大锁:因为P2-P3过程相对来说耗时较小,因此还算可以接受
- 加类似2PL的锁,但是
- 只针对按照全局排序规则排序后的写集合进行逐个加锁
- 扫描读集合中:是否现存的值和读集合中的值一致(包括版本号),以及是否读取的数据正被上锁(如是则说明其已经被另一个TX写了),如第一个是第二个不是,那么commit,否则abort
- 持久化写集合中的数据
Lock在硬件中的机制是会在汇编码中添加Lock prefix,执行到这一句的时候会将CPU到Memory的bus上锁,使得只有持有锁的线程能够访问内存,这一过程比普通的CPU访问L1 cache耗时很多
OCC的问题:
- False Aborts 在有些情况下,满足一定的Conflict Serial.的执行结果仍然会被OCC的终止机制终止掉,这样就会造成无谓的终止
- Livelock 活锁,即由于大量的并发读写操作,导致每个事务之间互相造成了彼此的验证冲突,从而每个事物都需要进行终止以及推翻重来,那么这样就会反复造成事务之间的终止(可以设置一些机制,比如不同的事务终止之后重做的delay时间有所区别)
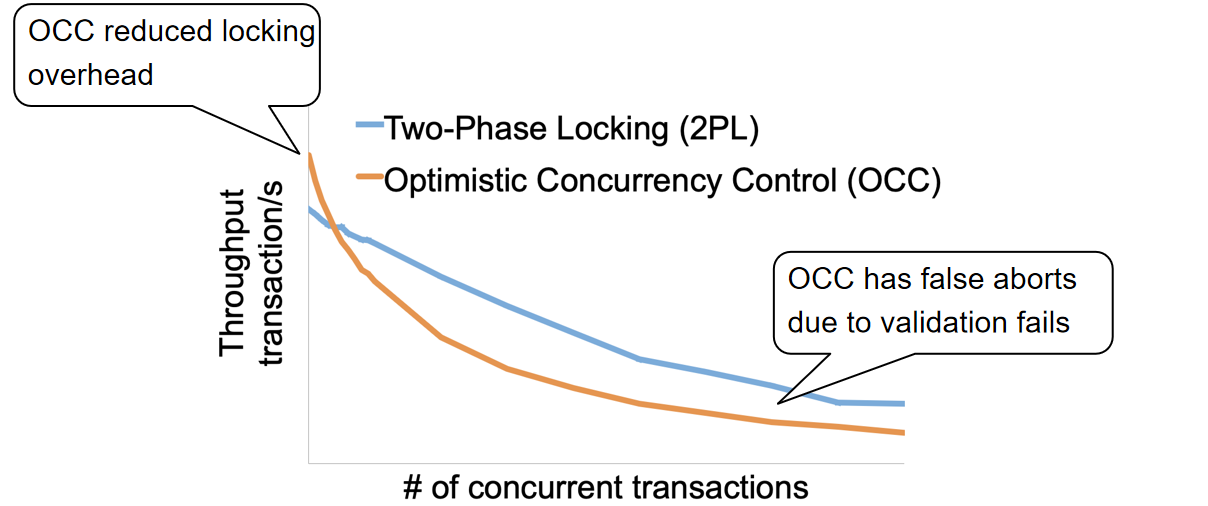
- OCC在高并发情况下表现不如2PL,因为他会反复终止已经完成了操作的事务,但是2PL本身在高并发条件下也会持有非常多的锁,从而导致其他进程没有抢到锁
OCC in hardware tx memory(intel)
因特尔的芯片可以支持在硬件层面的OCC,只需要在软件层面添加一些预设的接口表示事务的开始和结束即可
这使得在实现OCC从软件层面能够易于编程,但是在这里面的操作并不能保证执行成功
Intel通常将write sets保存在L1 cache中,将read sets放到L2 cache中,在多线程缓存中存在一个机制叫做cache coherence,具体内容是将每个线程对同一个内存区域的不同缓存进行同步,某个缓存被修改之后会将修改广播给别的指向相同内存地址的缓存;不过这里有个问题就是,假设这些cache被塞满了怎么整?一般来说如果这些地方被塞满就意味着别的事务不能够继续设置read/write sets了,因此这类事务会被直接放弃掉
这种OCC在纯读的情景性能比较好,而在写操作比较多情况下就会比较慢,因为老是会被abort
Snapshot isolation
在OCC的优化上,可以考虑不对read操作进行验证,因为很多False Abort就是因为不合适的read validation,导致了本来可以不终止的事务终止了
但是从常规的机制来看,又不能放弃这个read validation
现在有个想法,每个数据可以分不同的版本号,而且不同版本号的数据可以共存,然后每个事务也标记一个commit number,这样子可以保证具体的TX能够访问最靠近自身版本号且不高于自身版本号的数据(这样子就可以满足TX开始时间的实际执行效果满足串行的TX顺序)

- 首先每次一个TX开始都会先去
fetch_and_add的操作,获取一个开始号,表示当前TX的次序;单个TX执行读操作的时候会读取版本号最接近自身且不超过自身的版本的数据,执行写操作仍然是写入write sets - 随后会获取一个提交号,提交最终的结果,写操作在获取提交号之前会上锁
下图中的T2是已经完成了将数据写到write sets操作,即validate and commit持久化数据的过程,这里先拿锁再更新版本号,主要是为了保证T2写对外的原子性,否则T1仍然能够在T2已经更新commit_time的时候读取旧版本的数据
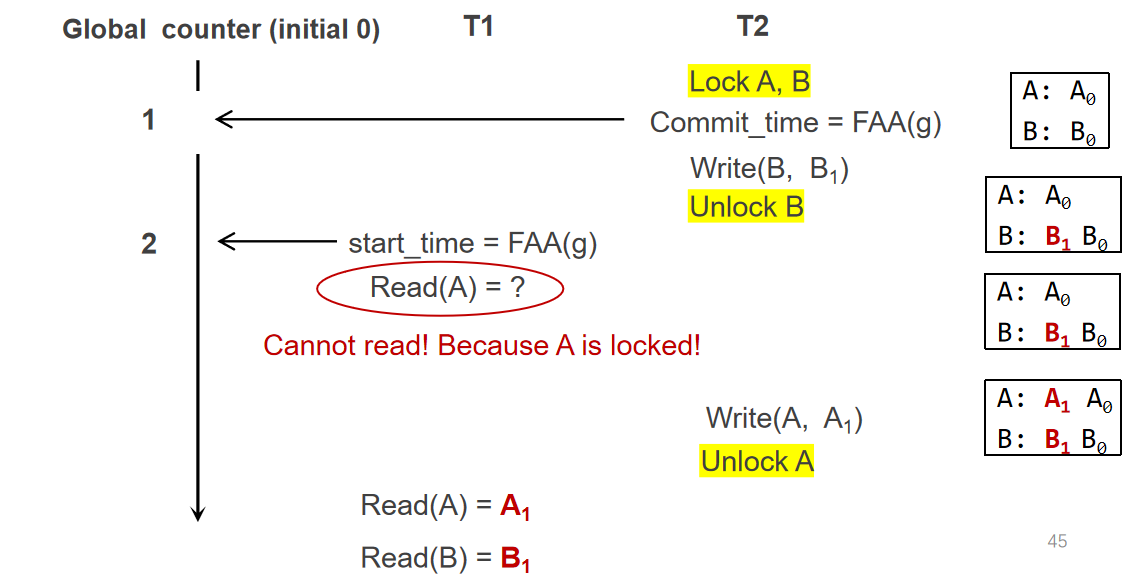
如果一个事务只有读或者只有写,那么这个策略是很好的;如果一个操作有读又有写,那么会存在一定漏洞,因为这里会认定读到的数据是一定不会错的(即不需要验证的原因),因此这里写操作的数据也是基于读操作的数据进行写的,那么在这里就出现了前一次的写被后一次的写覆盖,而本身应该是串行执行,+=1执行两次
验证的方式:在获取commit_time后先验证一下当前拥有的数据是否已经被其他具有大于该事务start_time的commit_time的事务给修改了(这样还是算是一定程度上剪枝了的),修改后的方法就从SI正式改为MVCC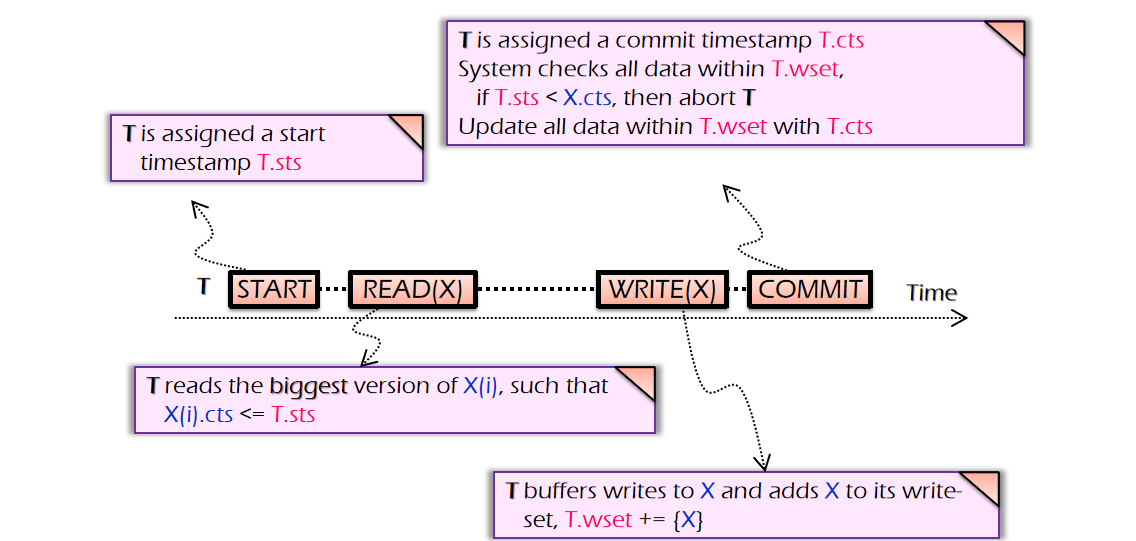
然而,即使是MVCC也不能够保证整个操作的Conflict Serial.性质,比如下面这个例子,我们看到这个例子里面有一个TX指向关系的环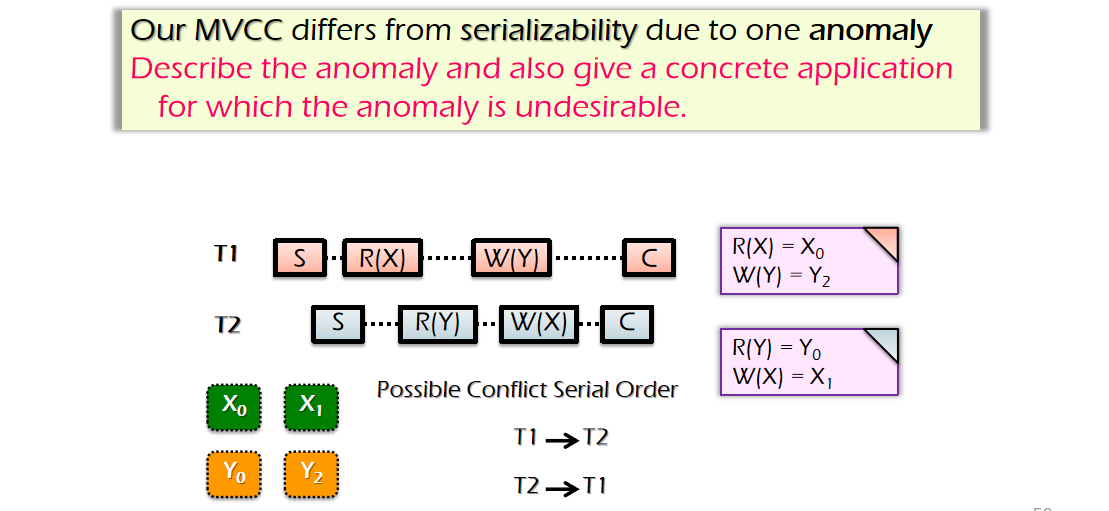
一般解决办法是在read-write TX进行一个对read set的验证操作,而read-only TX则可以不需要进行一个read set的验证操作,这样还是能够做到性能上的提升,一般MVCC也可以直接改为SI,忽略掉read-write TX的验证read set操作
Multi-site atomicity(Two-Phase Commit)
现在要解决的是分布式事务的问题,由于种种原因,一个单独的事务可能需要再不同的机器上执行指令,那么如何控制单个事务的多台机器的all or nothing就成为了一个问题
- case 1:整个大的操作作为一个high-level的事务,而每个针对单机单条数据的读写作为一个low-level事务,low-level事务提交与否取决于high-level的判断,high-level事务根据low-level事务的状态去决定这些low-level要不要提交
- case 2:单个事务本身就包含了对多台机器的多个读写操作,这可以抽象成第一种情况
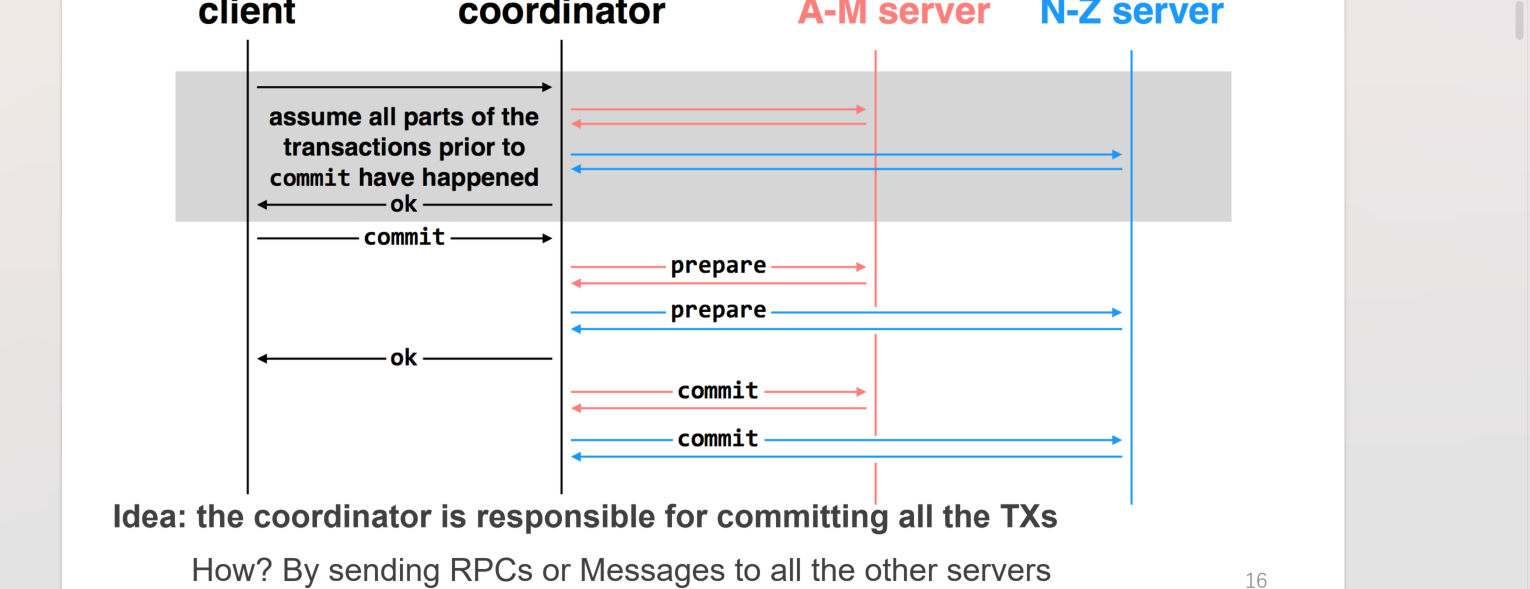
针对这种情况,每个low-level可以添加一个中间状态tentative-commit(prepared),表示本地已经完成了写操作的log,等待high-level的指令以持久化;而high-level可以在一定时间内向每个low-level进行check,若都进入了prepared状态则可以向每个low-level发出“可以持久化”的指令,否则待定(比如某些还没有确定完成与否),否则把全部的都中断掉(某些abort)
通常中间加一层coordinator作为协调者
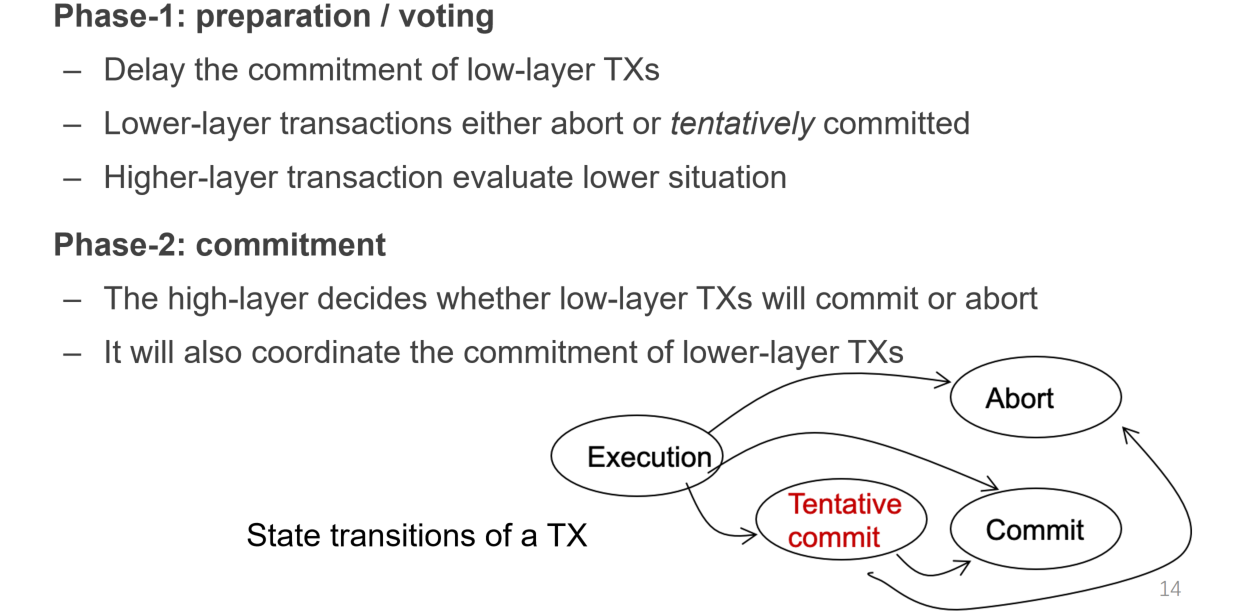
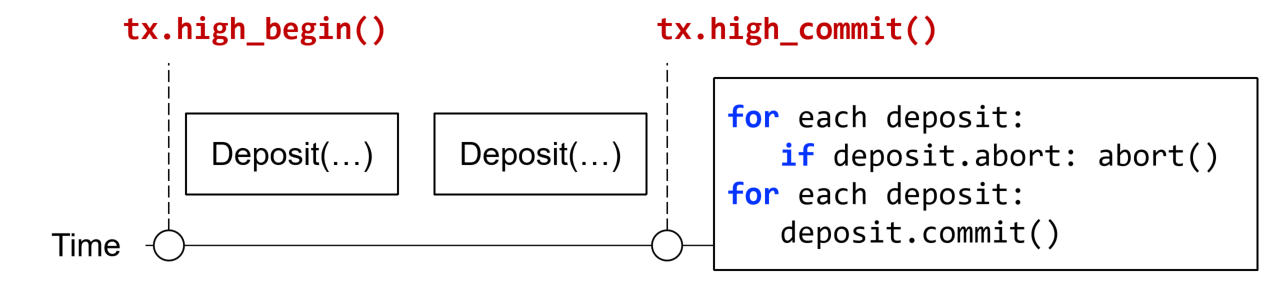
Logging rule under 2PC
如前所述,添加一个prepared阶段,作为本地已经完成操作的log,等待持久化/中断指令的状态,并且向high-level发送自己已经prepared的状态
这里强调的是,low-level在prepared阶段之后必须基于coordinator的指令进行下一步动作,比如可以是low-level询问high-level(在coordinator向low-level发送查询请求失败之后,prepared面临可能被OS换页的情况),而high-level然后针对每个low-level发来的信息确认状态,全部就位就可以在自己的log写commit;如果high-level并没有发出指令则等待
some failure cases
- 假设客户端打算
commit了,coordinator会向每个server发送询问其是否已经prepared的请求,假设在coordinator发送请求或者server返回ACK的时候网络丢包了,那么一般来说coordinator会存在超时重传的性质 - 如果在case 1的情况下,不是网络丢包,而是server直接挂了,那么意味着超时重传多次失败,则coordinator会认为有一台机器挂了,那么直接在自己的日志写入abort,并且告知其他的server去终止
- 如果coordinator已经得知每个server全部都prepared,那么其会向客户端发送
commit OK的响应(客户端认为已经成功提交,然而这其实是一个异步的信息,实际内部尚未提交),同时coordinator告诉每个server去提交数据;如果这个时候出现了网络中断,意味着coordinator没有及时收到ACK,则和第一种case一样采用超时重传的策略 - 如果在case 3下故障改为某台机器挂了,那么coordinator不去理睬这个故障,而是故障机器重启后,将要处理prepared日志的数据时,询问coordinator该事务的状态,确定其为abort or commit
- 假设在查询prepared阶段时,coordinator挂了,在PPT上显示的是重启后coordinator会认定为终止(可能是认为某些prepared信息丢失了),不过其实也可以是磁盘持久化prepared信息,重新统计并查询(这样增加写磁盘的开销,本课程不采用此策略,因为优化性能要求减少日志操作)
- 假设在确定commit的时候,coordinator挂了,机制上需要让commit先写入到coordinator log中,然后再去向每个server发送commit请求,这样才能够让别的没有收到commit请求的server直接按照case4去解决
与2PL OCC的结合策略:

对于2PC而言,其保证了一致性,没有保证容错性(多机备份),所以需要增加容错性的机制
而本身事务这种东西对一致性要求比较高,那么就需要采用pessimistic replication的机制


