计算机系统工程之:网络
Weiquan HuangLink Layer
链路层主要讨论0-1电压序列如何从电路转换成为设备上的bit数据
- Shared Clock:两条线,一条用于保持数据电压,一条用来作为trigger触发对方的读取,适用于比较接近的器件(长距离难以保证两条线的同步),如寄存器之间的通信
- 3-wire R/A protocol:三条线,一条保持数据电压,一条为ready线在数据设置完毕后置为高电压(1),一条为acknowledge线在数据接收完毕后置为1作为给发出端的响应,响应后r/a重新置为0,等待下一个bit的输入(缺点是传输数据的带宽比较低);另一种设想是类并发地设置多个这样的配对,可以提高单位时间的数据传输量,但免不了木桶效应

- serial transmission:单条线但是能够一次性接受连续的字节流,而不是逐字节接收(USB)
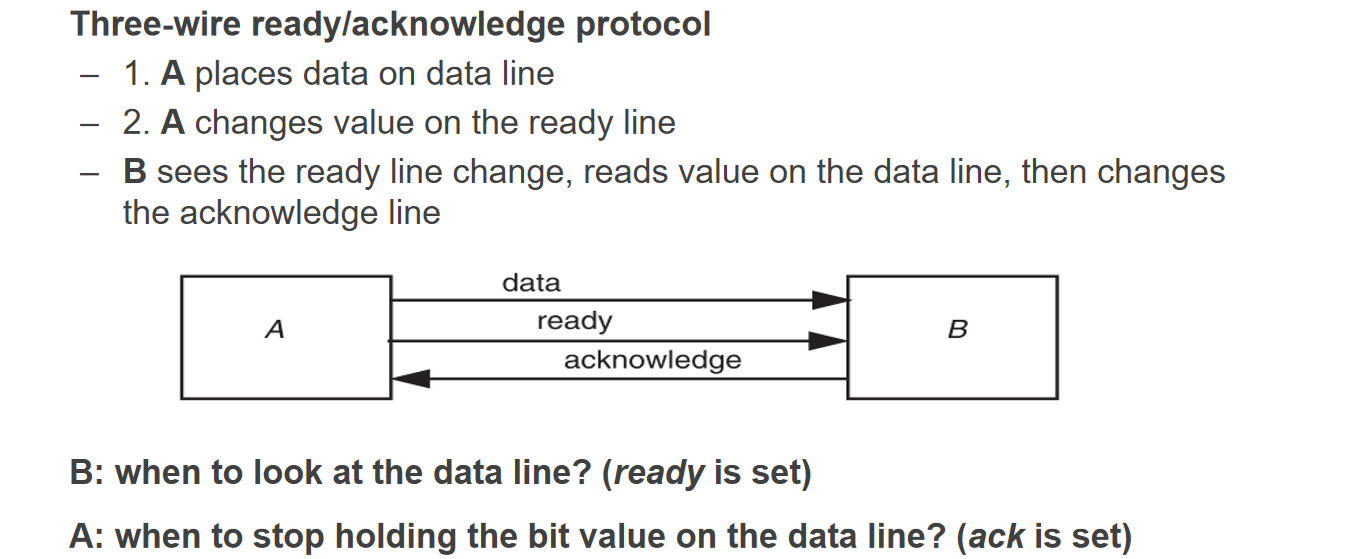
下面针对serial transmission的具体实现方式进行讨论
- VCO(Voltage Controlled Oscillator):根据当前检测到的电压变化频率来尝试拟合出自己的接受频率,问题在于假设有很长的一串连续相同电压可能干扰器频率的测算
- 增加频率的编码——Manchester Code:将
0->01 1->10,虽然会将有效数据率变为0.5,但是时间上带宽是可以保证的,只要接收方设备能够接收频率为原来2倍的数据 - 线路独立分区——TDM:将一条线路分为多个时间片,规定这些时间片分配给哪些会话,优点是能够保证通话的质量,缺点是能够同时占用的连接有限制
- 打包传输——Frame & Packet:一个包可以占有变长的帧数量,用整个字节流的方式将数据打包传输在链路中,目前是主流方法;线路不需要维护状态,连接状态由client/server维护,体现在报头上


下面针对Packet方式传输的一些讨论:
- 丢包问题:丢包是肯定会丢的,因为路由器的内存大小有限;加大内存反而是一个坏主意,因为内存大意味着队列长度上限大,反而容易诱发 一时大量数据涌入-在路由器排长队-排队时间过长导致大量数据触发超时重传机制-重新涌入大量数据 的阻塞正反馈,所以权衡下不如直接丢包
- 如何确定数据流的开始以读取数据?规定首次接收到1111111认为数据包开始,后续会针对111111(6-1)的数据后面添加0作为与7-1的区分,结束之后再解码回去;结束也有许多特殊的标识方法
- 小规模纠错:检测出错误后,就地纠错比返回NAK让发起方重传要高效的多,不过由于纠错容易引发误纠,因此目前支持小规模的纠错(比如相差一个1的错误)
- Hamming Distance:两串等长数据异或,最后结果为1的位数量为其Hamming distance,表示错误程度
- 4-7bit编码:传输前将0-1字节流每4bit做一个拓展编码为7bit流,在接收端可以根据7bit中校验位的计算错误来判断出某些位出现了错误;不过这里仅可以根据结果纠正那些只错了1bit的7bits单元(即能够检测出1、2、3个bit的错误,能够根据这些错误修复因为1bit出错的错误,如果是2bit同时出现错误导致的错误则无法修复)


Network Layer
一个包携带了NETWORK_HANDLE的IP信息(这里不叫“接收端”是因为这玩意可能有转发的功能),经过路由器的时候需要根据IP判断要导向哪一个出口,即需要查路由表;如何生成路由表的算法属于Control-Plane的范畴,而如何根据路由表寻找出口的过程属于Data-Plane的范畴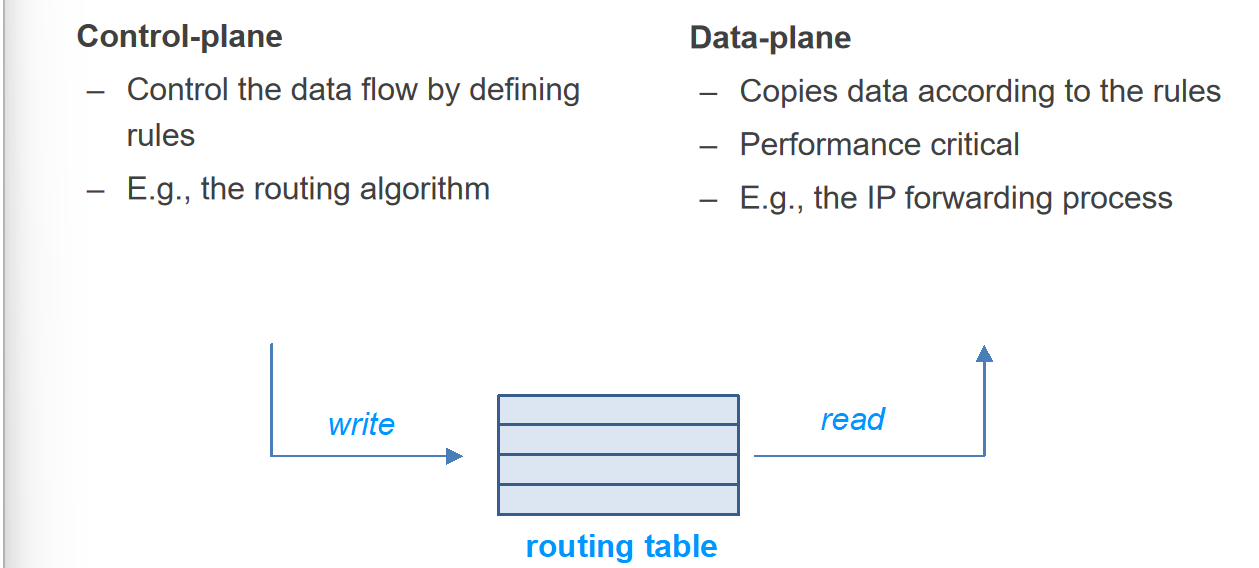
Control-Plane 如何生成路由表?

- Link-state:单个节点最初会携带其邻居的信息和距离,会先向距离最短的邻居发送请求,请求其以自己为基点向外拓展(可以优化:不向请求方拓展);拓展的时候会发回给最初基点,最初基点根据类Dijkstra算法更新自己的距离最小堆;一次迭代后,以最初基点和其已经请求过的点作为基础网络,向距离该网络距离最短的节点进行探索,直到每个节点都被探索到为止
- Distance-vector:网络中的每个节点都会向自己的所有邻居发送自己所能够到达的所有的点的信息(即不仅局限于邻居,取决于整个网络经过了几次该算法的迭代),每个节点都收到了大量的信息之后自行进行整合(Bellman-Ford算法),整合出当前通向每个点的最优距离以及最优出口;单次迭代无法得到理想最优解,需要经历多次迭代之后才能得到理想最优解(优化:B节点不要将从A节点来的路由信息重新传给A)
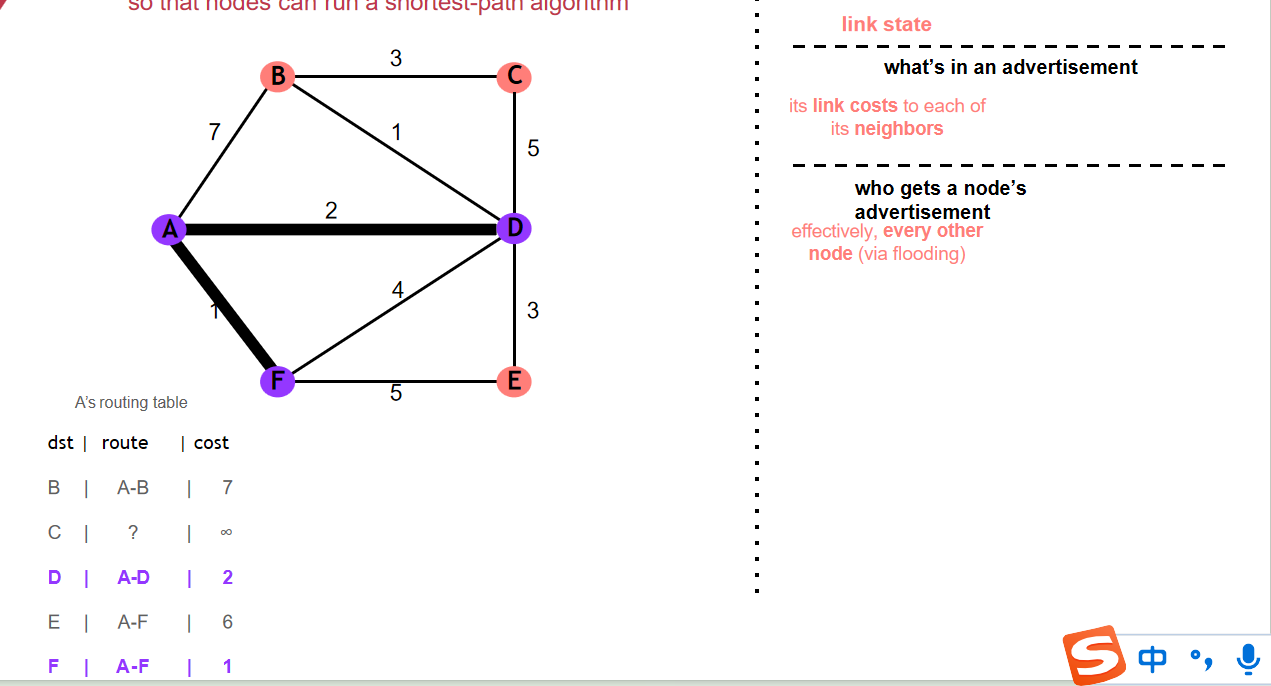
如果B会向A传递从A来的信息,假定之前A已经从B处获取了能从B到达C,此时B-C网络断了,此后B先记录C为断路,随后向A请求,A发送了C:A->B,2 那么B就会觉得能从A处获取C;由此A/B就会互相更新C的路由,其不仅没有意义,而且占用了网络资源
解决方法为:B不要去传给A从A来的信息,A也不要传给B从B来的信息
上述两种方案都只能适用于小规模的网络,link-state的主要问题是获取单个节点的表需要flooding所有节点,distance-vector的主要问题是每次出现变更就需要更新,而更新需要传的数据也比较多,迭代周期数量也取决于网络的大小
Scale the Routing Algo
- Path Vector Exchange:每个节点最开始只有通向自己的标记,随后向每个邻居发送自己的信息且进行交互,从而获得“从哪一个出口到达哪个点”的表;然后再多次迭代,拿到从当前点到目标点需要从哪一个出口出去的信息优点是表的收敛时间缩短了,overhead大于distance-vector,小于link-state
- Hierarchical Address Assignment:分层地址结构,本地维护一个对外的地址,网关可以用来进行内部网络和外部网络的通信,内部的网络只使用内部网的IP而不拥有外部网的IP,这样路由表所需要维护的内容就减少了(Region也被称为AS)
- Topological Addressing:可以将相同地点的地址使用相同的前缀,比如美国的IP都是
18.0.0.0/8,这样就可以以类似分级的思想,将18.0.0.0/8的地址统统导向美国的光缆
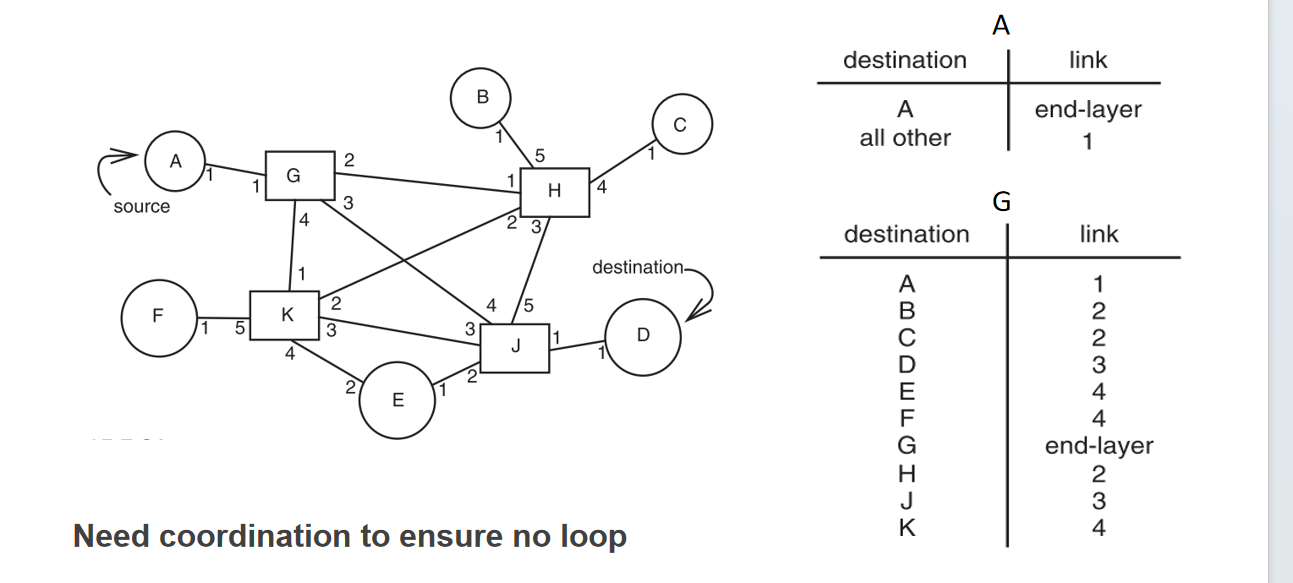
 优点是表的收敛时间缩短了,overhead大于distance-vector,小于link-state
优点是表的收敛时间缩短了,overhead大于distance-vector,小于link-stateData Plane
SEND函数封装报头,HANDLE函数确定请求应该发送去哪里
不仅是本地的请求需要经过HANDLE,从别的地方来的请求也需要经过它,如果是发给这台机器的那就接受,否则(比如路由器)就转给别的出口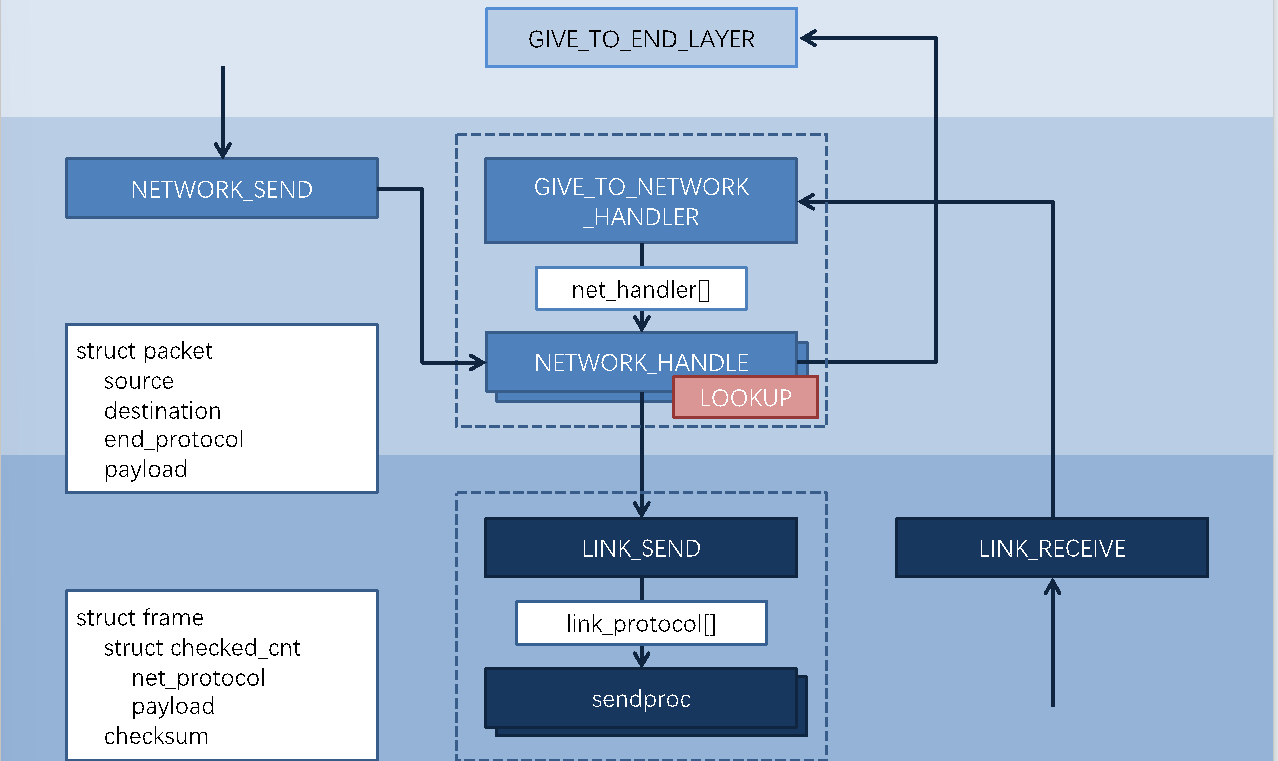
Data Plane Development Kit:相当于请求绕过内核直接发往对应的进程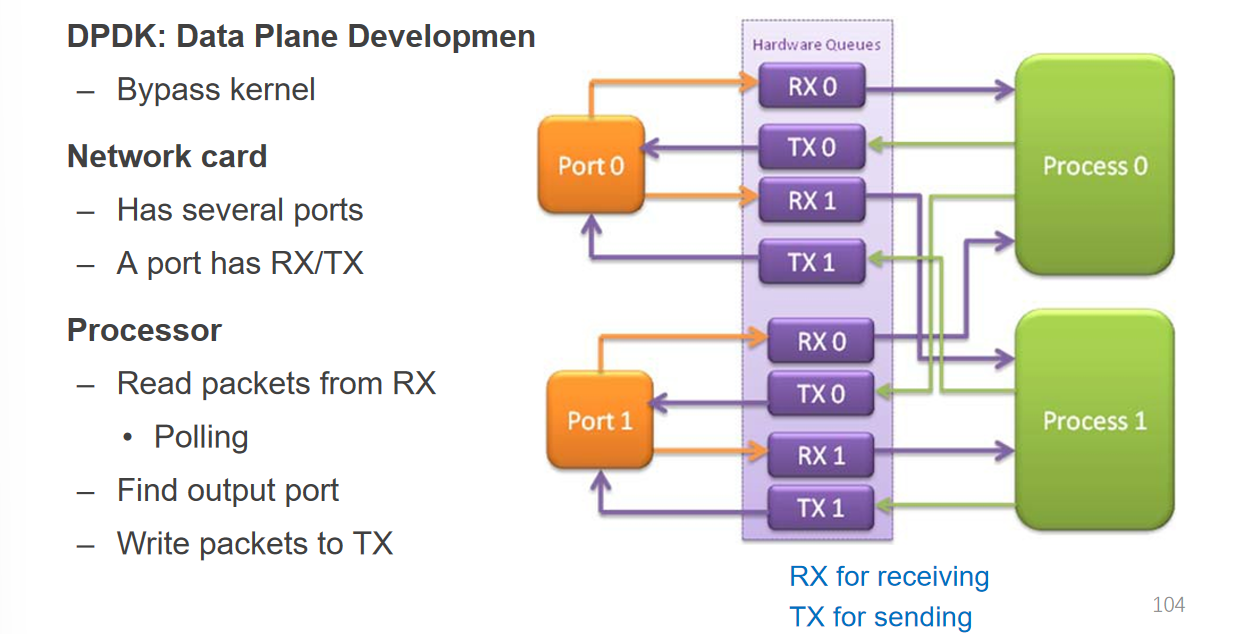
NAT(Network Address Translation)
前面有提到内网private network和网关NAT router的概念,这里讲的就是这个,不过这里的问题就是,出现了网络层和传输层的耦合,即在网络层步骤中使用了传输层才带有的信息port;这在系统设计中不好,但是由于大部分网络请求都是TCP体系,因此问题不是很大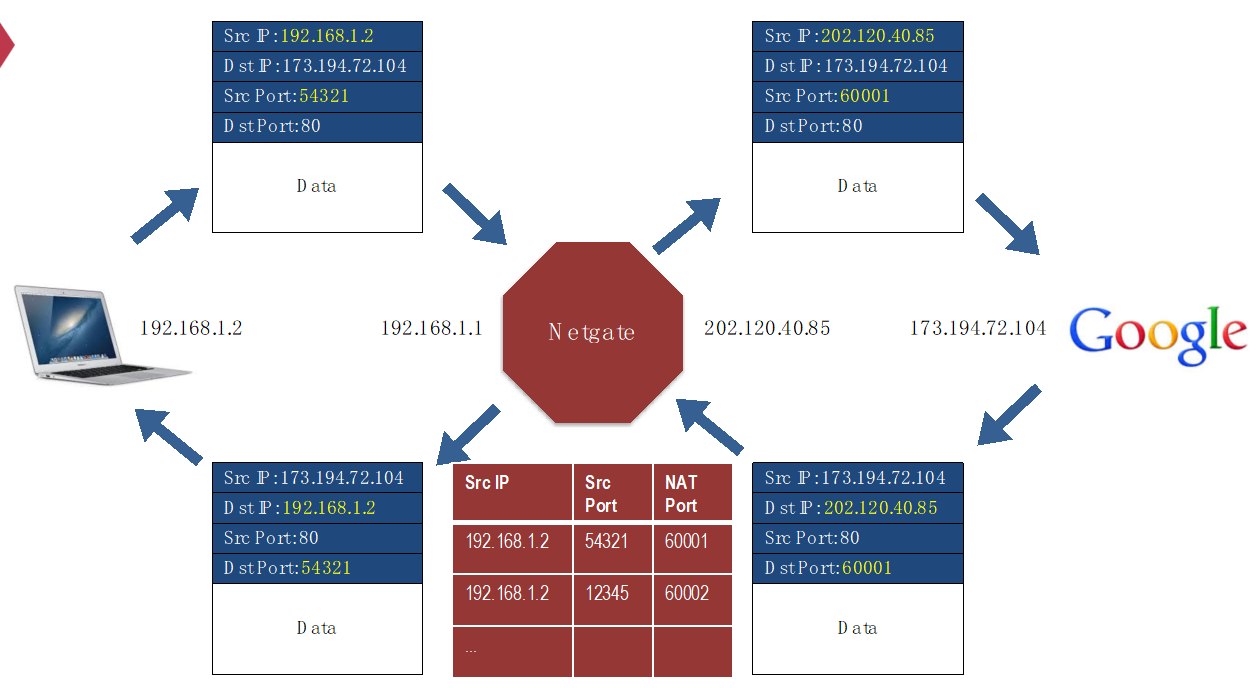
TCP Congestion Control & DNS
Sliding Window
发送者维护一个发送队列的Window,处在Window内的包可以被发出去,当Window内的编号最小的包确认ACK之后,窗口滑动,更新可以被发送出去的包的范围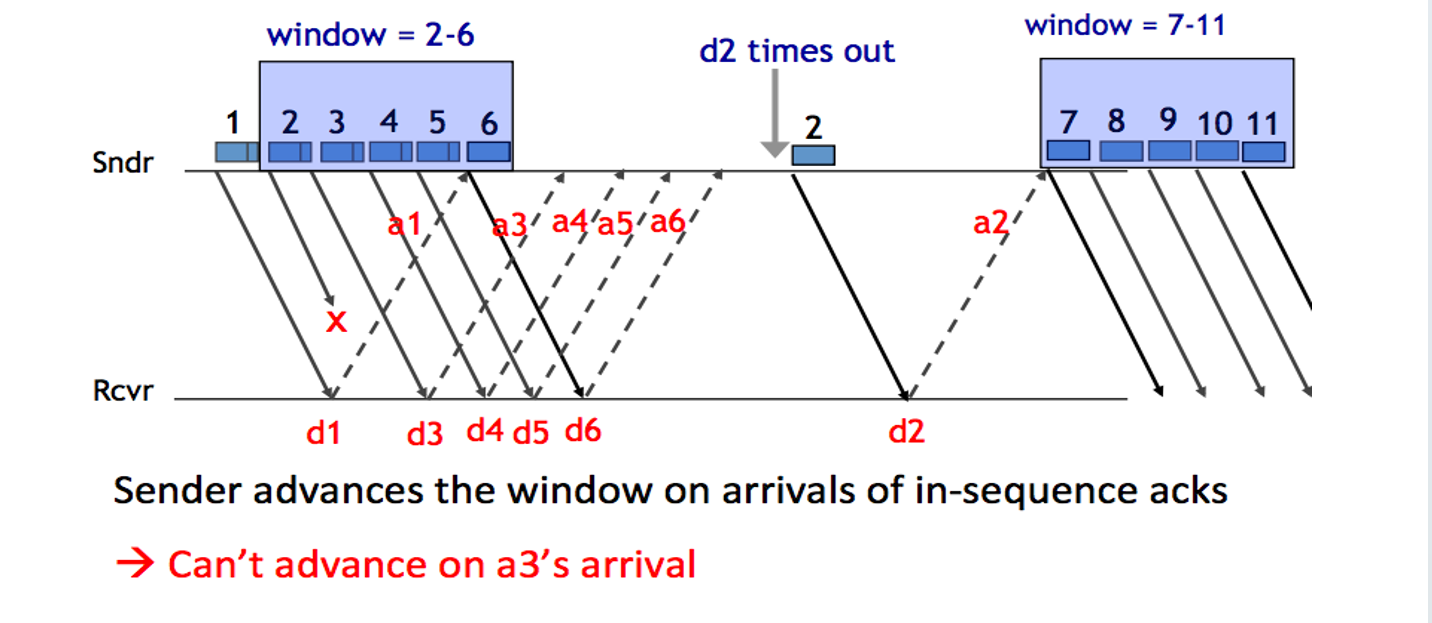
- 如果Window太小,那么就无法发挥类流水线模型的优势
- 如果Window太大,那么就会造成网络线路拥挤
我们需要动态调节Window大小的机制
Congestion

网络层的路由器和端到端层的发送方需要共同承担限制Congestion的任务
- 成因:大量网络包造成局部路由器阻塞且丢包,丢包导致大量重传,从而正反馈这一阻塞现象
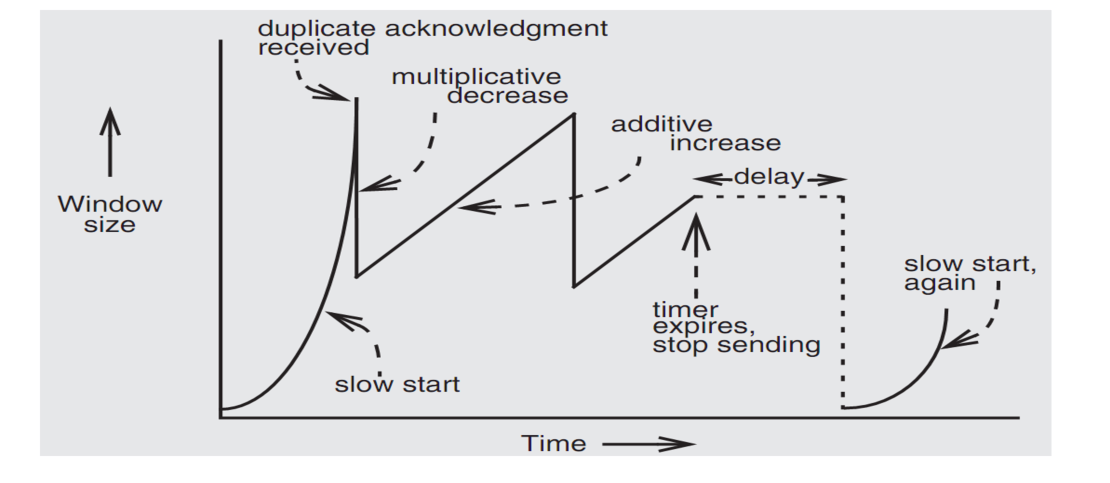
- 阻止:使用AIMD策略,即Additive Increase, Multiplicative Decrease
AIMD
- 如果当前没有发生丢包或者收到重复的ACK No.(即之前已经收到了ACK3,现在又收到了一次,说明曾经在Receiver触发了超时重传),那么window size按线性增长
- 如果收到重复ACK,则将window size减半,后续线性增长
- 如果发生超时重传,则直接将window size降为1,并且以指数形式增长(被称为”slow start”)
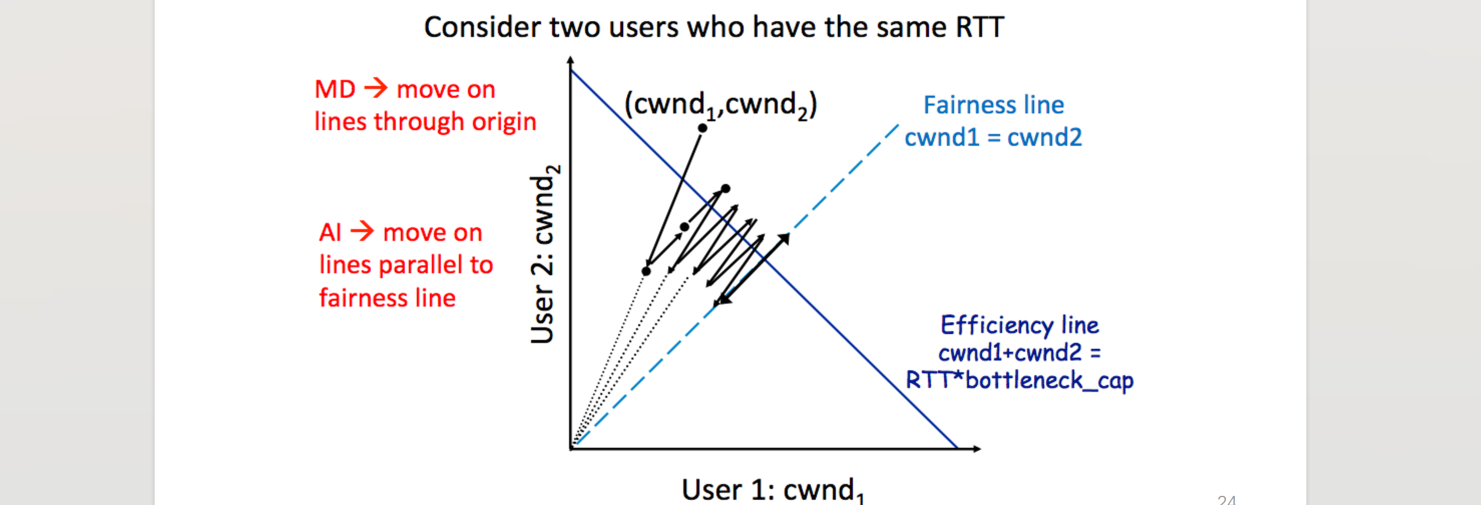
- AIMD被证明为能够保证多个发送方之间的平衡,发送方之间会逐渐收敛到发送量等同的状态,不会出现饥饿
Weakness of TCP
- 不适用于无线网,因为无线网发送异常通常是信号不好(即发送方无法将数据投放到网络层中),而AIMD频繁认为其触发了超时重传
- 不适用于数据中心:数据中心的网络层带宽比较高,通信质量比较好,AIMD在实际会浪费一部分网络带宽(体现为面积中的倒三角形)
- TCP需要握手,连接需要花费RTT
DNS
通过域名翻译为IP,支持一对多(分流降压)、多对一(单机部署多网站)、绑定关系修改
Look-up Algo
域名系统类似于文件系统,倒序的树状结构
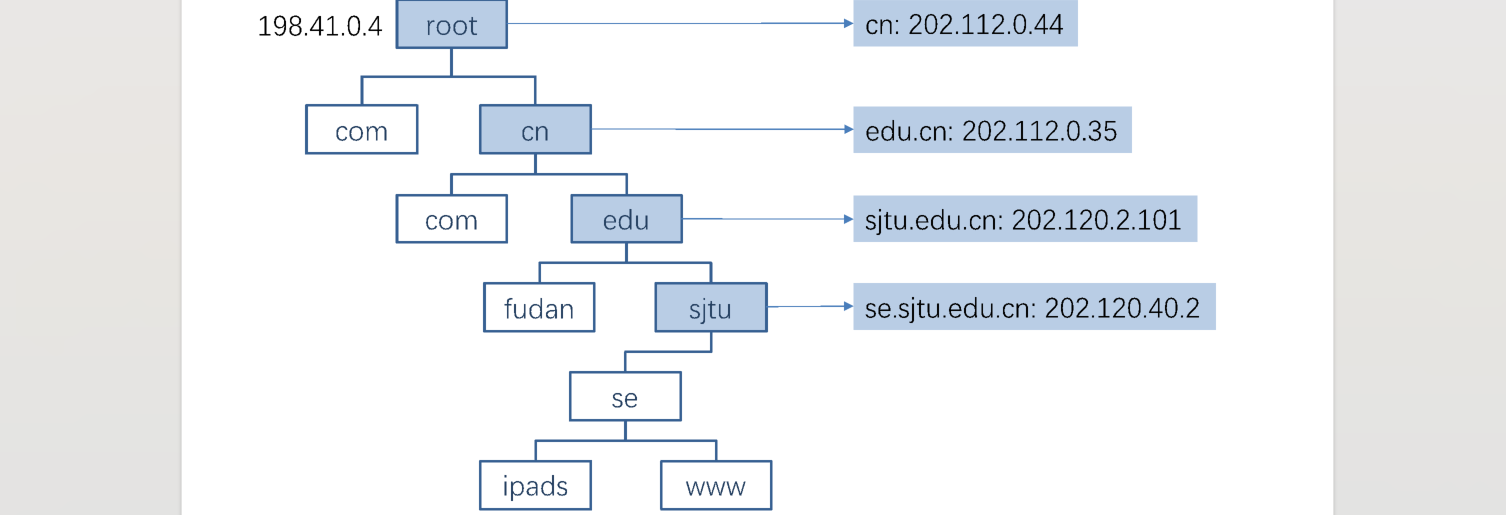
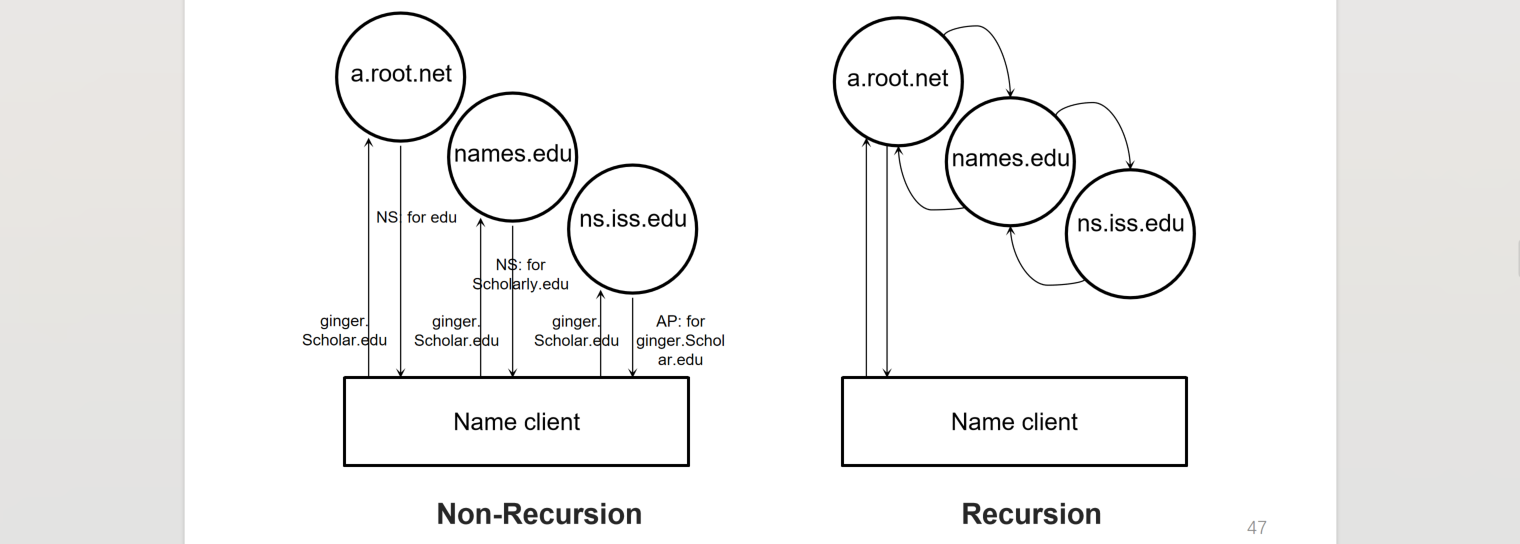
- each zone can have multiple name servers
- initial DNS request can go to any name server, not just the root server(自己配置一个
/etc/resolv.conf文件) - name server does recursive lookup steps, client does not need to send to all name servers in the domain name chain(network between name servers are better!)
- lower layer name server can cache the request to higher layer name servers, thus client will hit the record, instead of frequently requesting higher name server
End2End Layer
Ethernet
数据包广播给每个接入设备,而每个设备则检查这个包是否是发向自己的(或者检查这个包是不是广播性质的包),单个Ethernet内的设备用Mac地址标识,不同的Ethernet之间可以出现相同的Mac地址,只要在单个内网里不出现重复即可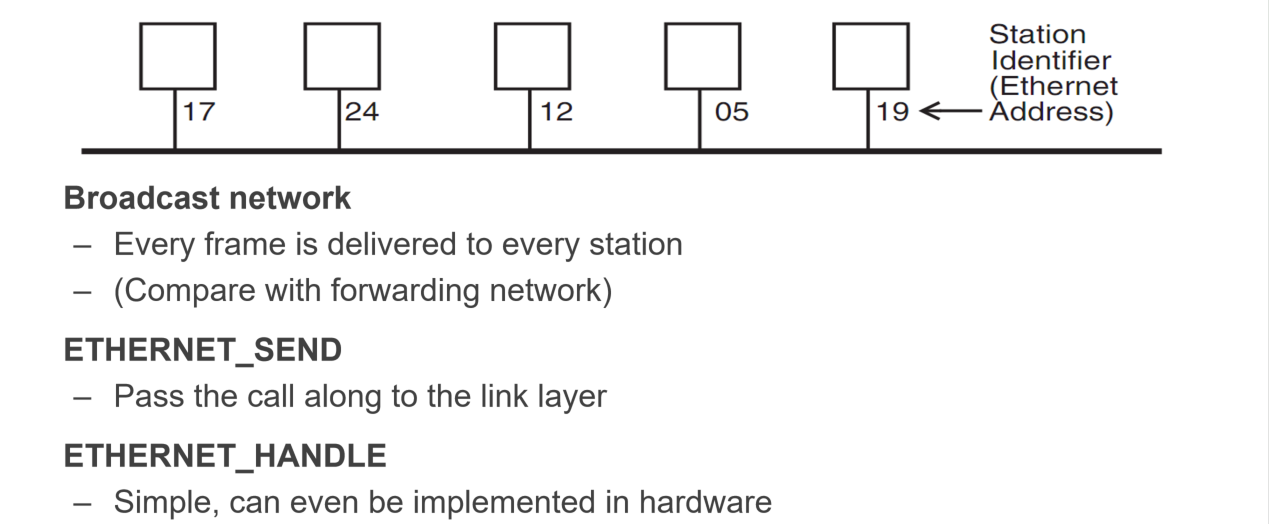
ARP(Address Resolution Protocol)
问路算法:想知道一个IP地址的Mac物理地址,询问者会向每个能直接通信的节点广播,而被查询者本机和了解被查询者物理地址的路人节点都可以对其提供信息
下面根据一个网络拓扑图来分析发送信息的具体流程:如何从Node-C到百度?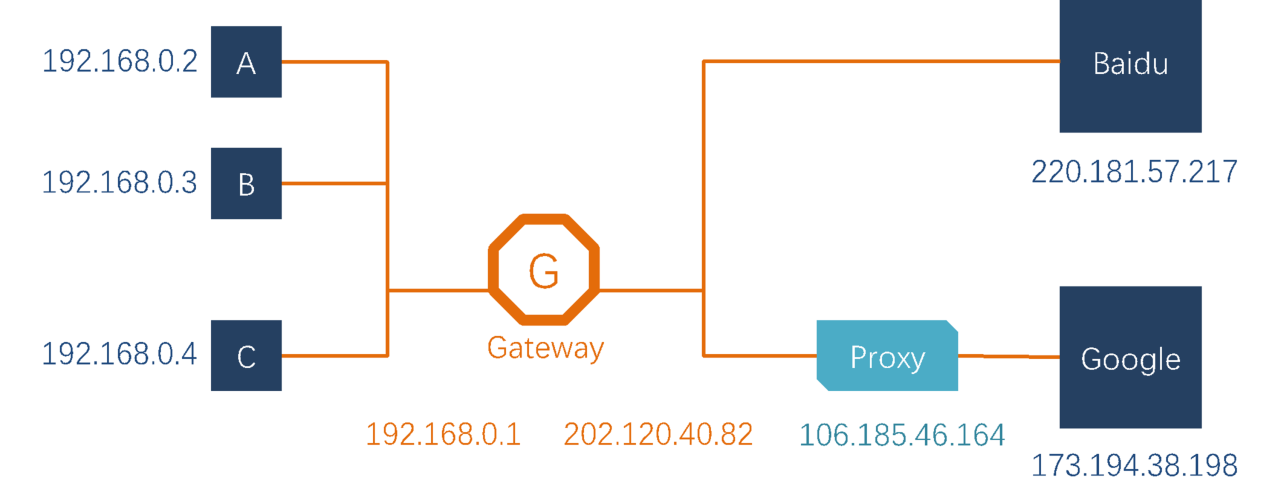
- APP发送出请求,从节点C的应用进程出发的时候只知道自己的IP和对方的IP,不知道两者的Mac地址(对,不知道自己的Mac地址)
- 经过本机操作系统之后获知内网拓扑结构,根据两个IP得到当前阶段(从NodeC到Gateway)的Mac地址,每个阶段都会更新当前的src/dest MAC地址
- ARP Spoofing:黑客利用ARP问路机制的漏洞,伪装成一个正常接入内网的节点,发送虚假的信息给问路者,从而污染他们的路由表,将这个窃听节点作为其他节点信息的接受者目前仅有一些治标不治本的解决策略




 目前仅有一些治标不治本的解决策略
目前仅有一些治标不治本的解决策略
Assurance
- At-Least-Once:发送方至少发送一次,如果没有接收到ACK则适当地触发超时重传
- 定时超时重传:会造成信息集中冲击接收方,当冲击量足够之后会导致接收方崩溃
- 动态调整超时重传:Linux使用一系列公式来调整超时重传的触发时间,思想类似于当前情况权重更大的算法,即$T_{avg}:=\alpha T_{avg}+(1-\alpha)T_{now}$,但是$\alpha$的设置并无理由可言,也许可以训练出来?
- 将责任推给接收方(接收方发送NAK,则发送方不需要设置超时重传的时间):接收方难道就不会出现网络故障吗?
- At-Most-Once:接收方实际的效果为至多只接受(并处理)一次
- 记录已接收包的nonce:如果给这个记录设置删除时间,那么如何保证该时长过后不会有重复的请求?如果不设置,那么记录不断增长会造成负担
- 幂等性处理请求:读操作可以,POST怎么保证?
P2P network
CDN(Content Distribution Network)
将大型文件存储在一个个CDN节点上,比如B站可以在很多个城市维护很多个CDN节点,当视频上传的时候可以直接将这个视频广播到这些节点上/这个节点被动在用户的请求后获得视频并缓存,这一部分取决于视频的火热程度
获取视频的方式大概类似于这样,作为一台客户端机器,发送请求寻找最近的CDN服务器只需要一次miss,而后这个被定位到的最近CDN服务器就会向中央的内容提供商来进行请求,并将结果返回给客户端,同时这个内容会被缓存到这个CDN服务器中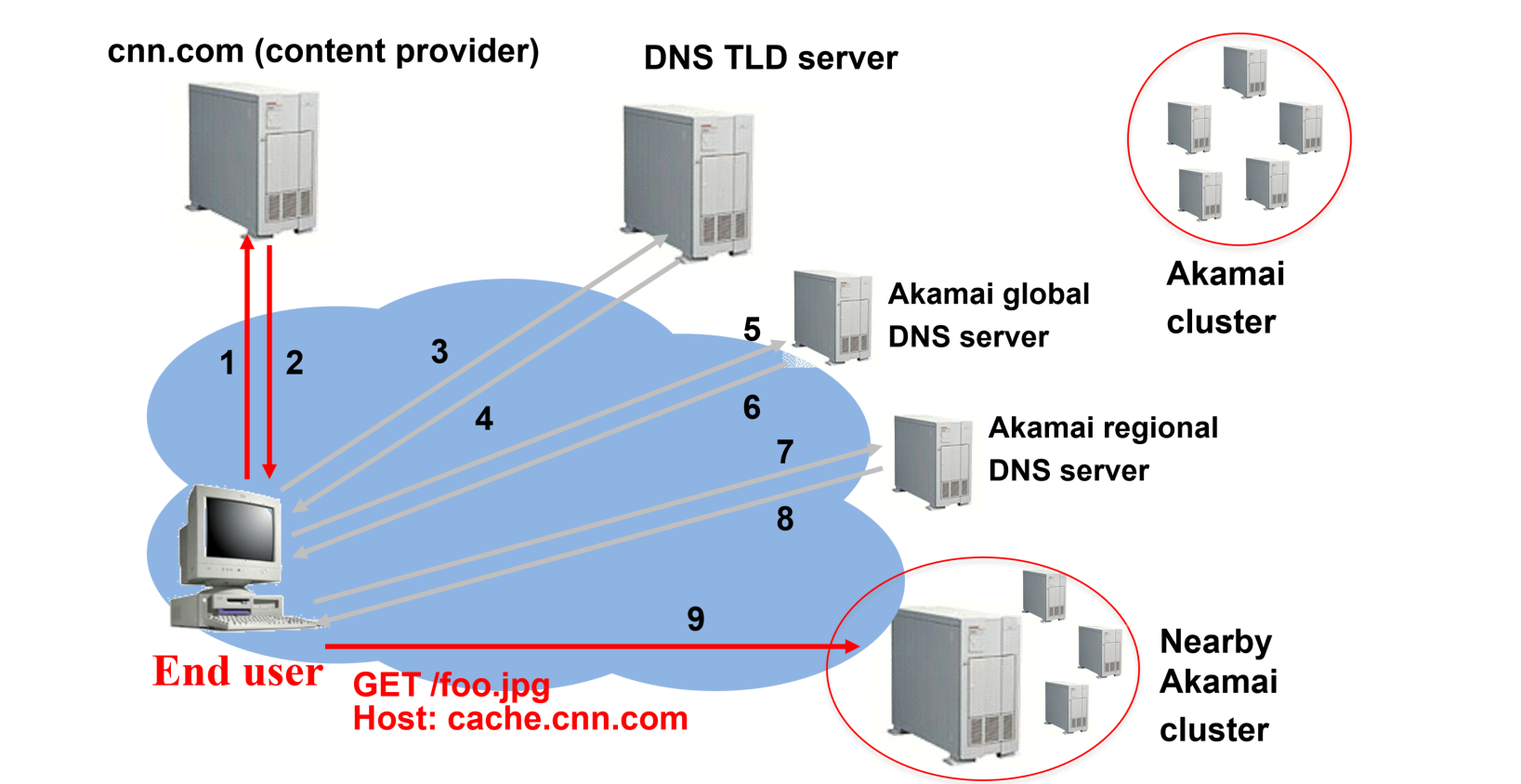
P2P
去中心化网络,用于每个端共享各自的文件,一个端从体系中别的端拿到一个文件拼图的一部分,然后一步步拼成完整的文件,而获得文件部分的端也要承担起共享文件的责任
- Publisher 发布
.torrent文件,具有tracker以及其他能够帮助到端获取文件拼图的信息,放置在一个网络服务器上 - Tracker 保存谁下载过哪些文件,方便想获取文件的端去定位
- Seeder 需要有文件的全部

通常一个端可以采用优先获取稀缺资源的策略,当然也不止这一种策略
DHT(Distributed hash table)
就上面提到的分布式端到端文件共享网络,他也要根据key去寻找value所在的机器,这里采用的策略就是将特定编号的key根据一定的规律存放在指定的机器中,存放和寻找都是用哈希的方式
Consistent Hashing:环形哈希,处在范围内的键存放在箭头所指的节点中,这里的key和node id都需要经过SHA-1编码
实际上采用这种二分的方式能够实现以$O(logn)$的时间复杂度来寻找到键所对应的机器,就不用每次都一个一个沿着环顺序找下去了——具体来说,每个N节点存储的路由节点为距离自己$\frac{1}{2^n}$个周长的节点,首先去$\frac{1}{2}$处找,然后去$\frac{1}{4}$处找,etc.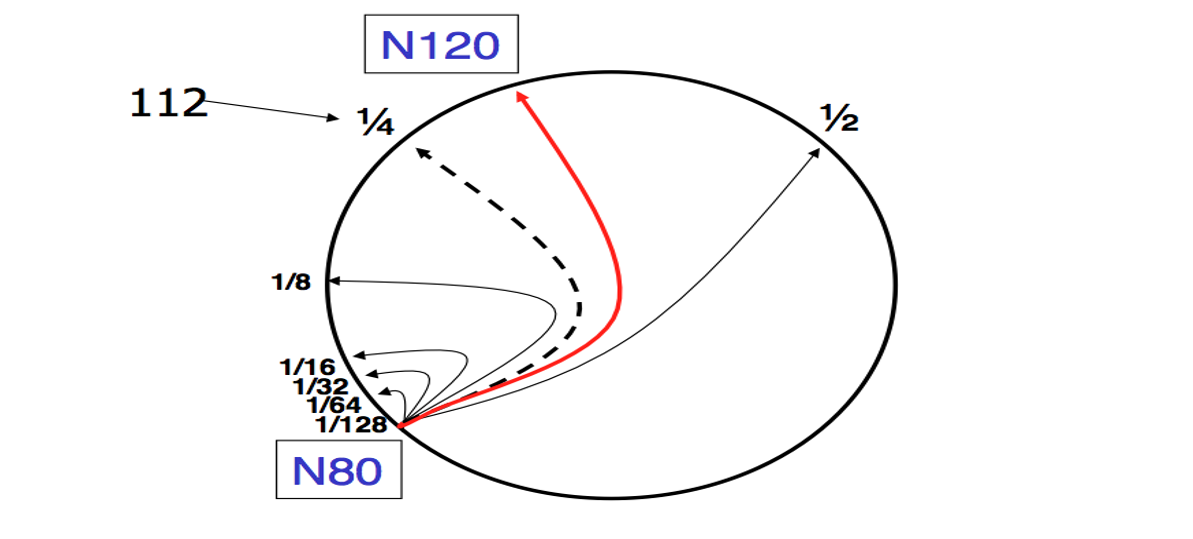
如果有N节点挂了咋整?这里K90应该是存在N113里的,但是这种二分查找策略却导向了N120(因为N10只会存储上述的二分的节点);那么这个时候就需要一个备用的successor lists,用来存放每个节点的一些后继者列表,作为备选方案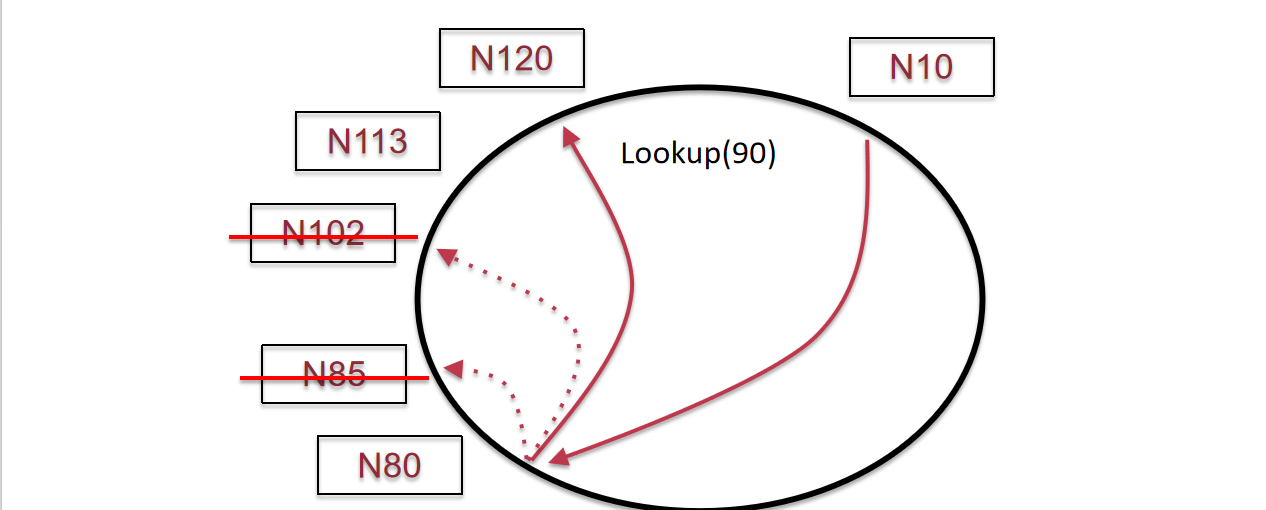
新加入的N36会接收K30,而N40不会删除K30,因为这并不会使其增加workload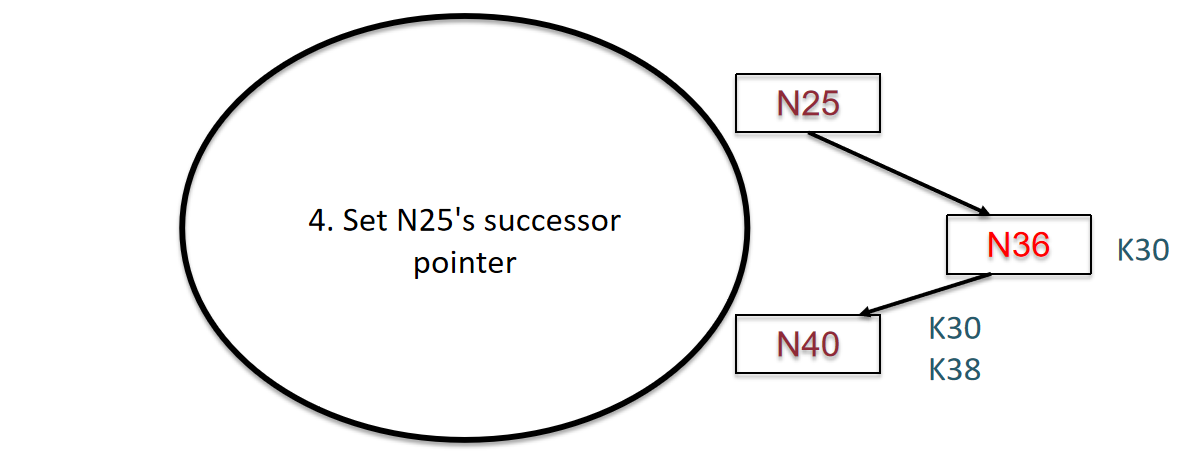
虚拟节点:如果一个P2P体系的节点数量过少,那么这个体系的节点可以自己创建虚拟节点;这样做的目的是将哈希函数的可哈希范围增大,以利于哈希的相对均匀,不会造成过载
Off Topic: Naming Scheme
系统领域的命名是一门学问,一个优秀的命名体系通常具有如下的优点
命名空间通常要和其所处的上下文相关联,比如lab1的上下文可以是cse也可是 战编译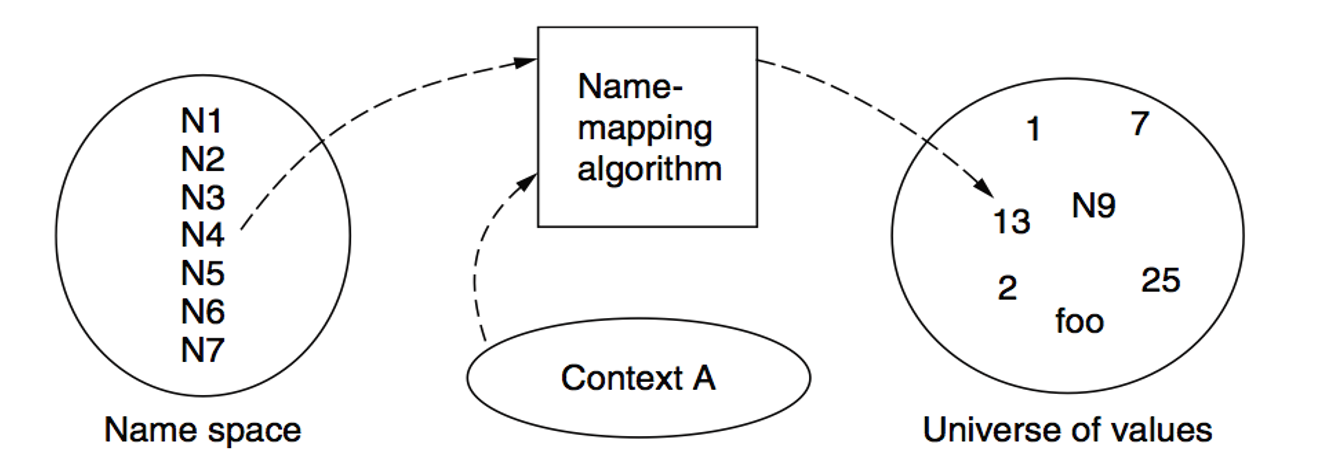
名称映射查找算法:
- Table lookup 即从存放map关系的数据结构中查找映射关系
- Recursive lookup 即分层递归式查找
- Multiple lookup 即给定许多个可选项,逐个查找
命名体系抽象API


